OpenAI GPT-1 - Improving Language Understanding by Generative Pre-Training(GPT1 논문 설명)
21 Aug 2019 | Paper_Review NLP이 글에서는 2018년 6월 Alec Radford 등이 발표한 OpenAI GPT-1: Improving Language Understanding by Generative Pre-Training를 살펴보도록 한다.
코드와 논문은 여기에서 볼 수 있다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
OpenAI GPT-1 - Improving Language Understanding by Generative Pre-Training
논문 링크: OpenAI GPT-1 - Improving Language Understanding by Generative Pre-Training
홈페이지: OpenAI
Tensorflow code: Official Code
초록(Abstract)
자연어이해는 원문함의, 질답, 의미 유사성 평가, 문서분류 등 넓은 범위의 과제로 이루어져 있다. 미분류 상태의 큰 말뭉치가 풍부함에도, 이러한 특정 과제의 학습을 위한 분류된 데이터는 부족하며, 모델이 적절히 수행하도록 만드는 것을 어렵게 한다.
이 논문에서는 이러한 과제들에서의 큰 성능 향상은, 언어모델을 다양한 미분류 말뭉치로 생성적 사전학습(generative pre-training)을 시킨 후 각 특정 과제에 맞춘 미세조정(fine-tuning) 과정을 거쳐 가능하다. 이전의 접근법과는 달리 모델구조는 최소한으로 변화시키면서 효과적인 전이(transfer)를 얻기 위한 미세조정 단계에서 과제에 맞는 입력표현(input representations)을 사용했다. 그리고 이 접근법이 다양한 과제에 대해 효과적임을 보일 것이다.
이 논문에서 제시하는 과제에 대한 별다른 지식이 없는(task-agnostic) 모델은 특정과제에 특화된 구조를 사용하는 모델의 성능을 뛰어넘는데 연구된 12개의 과제 중 9개에서는 state-of-the-art를 달성하였다. 예를 들어 상식추론(Cloze)에서는 8.9%, QA에서는 5.7%, 원문함의에서는 1.5% 상승하였다.
1. 서론(Introduction)
원본 그대로의 텍스트에서 효과적으로 학습하는 능력은 NLP에서 지도학습에 대한 의존성을 낮추는 데 있어 매우 중요하다. 대부분의 딥러닝 방법은 수동으로 분류된 방대한 양의 데이터를 필요로 하는데 이는 분류된 자원의 부족으로 인한 많은 범위로의 응용에 제약을 건다. 이러한 상황에서 미분류 데이터로부터 언어적 정보를 얻어낼 수 있는 모델은 힘들게 분류된 데이터를 만드는 것의 훌륭한 대안이 될 뿐만 아니라, 괜찮은 지도 방법이 있다 하더라도 비지도학습이 더 좋을 결과를 얻기도 한다. 사전학습된 단어 embedding이 그러한 예이다.
그러나 미분류 텍스트에서 단어 수준 정보 이상의 것을 얻는 것은 다음 두 가지 이유로 어렵다.
- 어떤 최적화 목적함수가 전이(transfer)에 유용한 텍스트 표현(representation)을 배우는 데 효과적인지 불분명하다. 최근 연구들은 언어모델링이나 기계번역, 담화 일관성(discourse coherence) 등 다양한 objective에서 각 방법이 다른 과제에서는 다른 방법을 능가하는 것을 보여 왔다.
- 학습된 표현을 다른 과제로 전이하는 가장 효과적인 방법에 대한 일치된 의견이 없다. 존재하는 방법들은 복잡한 학습전략이나 부가 학습 목적함수를 더하는 등 모델 구성에 과제에 특화된(task-specific) 변화를 주어야 한다.
이러한 불확실성은 언어처리에 대한 효과적인 준지도학습 접근법의 개발을 어렵게 한다.
이 논문에서는 비지도 사전학습(unsupervised pre-training)과 지도 미세조정(supervised fine-tuning)의 조합을 사용하여 언어이해 과제를 위한 준지도학습 접근법을 탐색한다. 목표는 약간의 조정만으로 넓은 범위의 과제에 전이 및 적용할 수 있는 범용 표현을 학습하는 것이다. 미분류 대량의 말뭉치와 수동으로 주석을 단(annotated) 학습예제를 갖는 여러 dataset에 대한 접근가능을 가정한다. 또한 학습은 두 단계를 거치게 된다.
- 신경망모델의 초기 parameter를 학습하기 위해 미분류 데이터에 대한 언어모델링 목적함수를 사용한다.
- 이 parameter를 연관된 지도 목적함수를 사용하여 목표 과제에 적용시킨다.
모델 구성은 기계번역, 문서생성, 구문분석 등에 상당한 성능을 보이는 Transformer를 사용한다. 이 모델은 RNN 등에 비해 장거리 의존성을 다루는 데 뛰어나 더 많은 구조화된 memory를 쓸 수 있게 한다. 전이 중에는 traversal-style 접근법에서 얻은 과제특화된 입력적응을 이용하며 입력은 한 개의, 일련의 ‘연속된 token’으로 주어진다. 이러한 적응방법은 사전학습된 모델의 구조를 바꾸는 것을 최소화한다.
이 접근법을 네 가지(자연어추론, 질답, 의미 유사성, 문서분류)에 대해 평가한다. 과제에 대한 지식이 없는 이 범용 모델은 12개 중 9개의 과제에서 state-of-the-art 결과를 보이며 선전했다.
2. 관련 연구(Related work)
Semi-supervised learning for NLP
이 연구는 자연어의 준지도학습에 넓게 걸쳐 있다. 이 체계는 sequence labeling이나 문서분류 등의 응용에 큰 관심을 불러일으켰다.
초기의 연구는 나중에 지도모델의 특징으로 사용될, 단어수준이나 구 수준의 통계를 계산하기 위해 미분류 데이터를 사용했다. 지난 몇 년간 연구자들은 미분류 말뭉치로부터 학습된 단어 embedding의 장점(다양한 과제에서의 성능 향상 가능성)을 발견했다. 그러나 이 접근법은 주로 단어 수준 표현을 학습할 뿐이다.
최근의 연구는 미분류 데이터로부터 단어수준 이상의 정보를 학습하려 하고 있다. 구 수준이나 문장 수준의 embedding은 미분류 데이터로부터 학습될 수 있으며 다양한 문제에서 텍스트를 적절한 벡터표현으로 변환할 수 있다.
Unsupervised pre-training
목표가 지도학습 목적함수를 수정하는 것이 아닌 좋은 초기화 지점을 찾는 것일 때, 비지도 사전학습은 준지도학습의 특별한 경우가 된다. 초기에는 이미지 분류나 회귀문제에 사용했다. 후속 연구는 사전학습이 정규화처럼 동작하며 DNN에서 더 좋은 일반화를 가능하게 함을 보였다. 최근에는 이미지분류, 음성인식, 다의어 명확화, 기계번역 등에 사용되고 있다.
GPT와 가장 유사한 연구는 신경망을 언어모델링 목적함수를 사용하여 사전학습시키고 지도 하에 목표 과제에 맞춰 미세조정하는 것을 포함한다. 그러나 어떤 언어적 정보를 포착하는 데 있어 LSTM의 사용은 이를 좁은 범위에 한정시킨다. 하지만 Transformer를 사용함으로써 넓은 범위에 걸친 언어적 구조와 정보를 학습할 수 있게 하였고 나아가 다양한 과제에 사용할 수 있게 되었다.
다른 접근법은 목표 과제에 맞춘 감독학습 중에 사전학습된 언어/기계번역 모델에서 얻은 은닉표현을 부가정보르 사용하였는데 이는 상당한 양의 parameter를 추가하는데, GPT는 그렇지 않다.
Auxiliary training objectives
보조 학습 목적함수를 추가하는 것은 준지도학습의 대안이다. A unified architecture for natural language processing deep neural networks with multitask learning이 여러 NLP task에 사용되었으며, 최근에는 Semi-supervised Multitask Learning for Sequence Labeling이 목표 과제에 보조 언어모델링 목적함수를 추가해 sequence labeling task에서 성능향상을 얻었다. GPT도 보조목적함수를 추가하지만, 비지도 사전학습이 이미 목표 과제에 대한 여러 언어적 정보를 학습했다는 것을 보일 것이다.
3. Framework
학습은 두 단계로 진행된다.
- 큰 말뭉치에서 대용량의 언어모델을 학습한다.
- 분류 데이터를 써서 특정 과제에 맞춰 모델을 미세조정한다.
3.1. Unsupervised pre-training
token의 비지도 말뭉치 $\mathcal{U} = {u_1, …, u_n}$이 주어질 때, 다음 우도를 최대화하도록 표준언어모델링 목적함수를 사용한다:
[L_1(\mathcal{U}) = \sum_i \log P(u_i \vert u_{i-k}, …, u_{i-1}; \Theta)]
$k$는 문맥고려범위(context window)이고 조건부확률 $P$는 parameter가 $\Theta$인 신경망을 사용하도록 설계된다. 이들은 확률적 경사하강법(SGD)에 의해 학습된다.
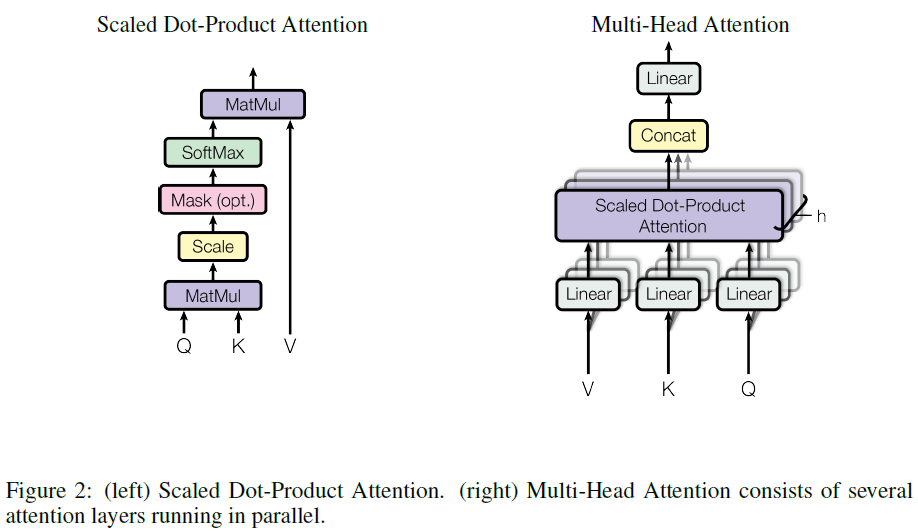
GPT는 언어모델로 Transformer의 변형인 multi-layer Transformer decoder를 사용한다. 이 모델은 입력 문맥 token에 multi-headed self-attention을 적용한 후, 목표 token에 대한 출력분포를 얻기 위해 position-wise feedforward layer를 적용한다:
[h_0 = UW_e + W_p \qquad \qquad \qquad \qquad \ \ \qquad]
[h_l = \text{transformer_block}(h_{l-1}) \ \ \forall l \in [1, n]]
[P(u) = \text{softmax}(h_n W_e^T) \qquad \qquad \qquad \quad \ \ \qquad]
$U = (u_{-k}, …, u_{-1})$는 token의 문맥벡터, $n$은 layer의 수, $W_e$는 token embedding 행렬, $W_p$는 위치 embedding 행렬이다.
(참고: 논문에는 위 식에서 $\forall l$이 $\forall i$로 오타가 나 있다)
3.2. Supervised fine-tuning
위 $L_1(\mathcal{U})$ 우도에 따라 모델을 학습시키고 나면, parameter를 목표 과제에 맞춰 미세조정한다. 분류된 dataset $\mathcal{C}$이 있고 각 구성요소가 일련의 입력 token $x^1, …, x^m$ 및 그 정답(label) $y$로 되어 있다고 하자. 입력은 최종 transformer block의 활성값 $h_l^m$을 얻기 위해 위의 사전학습된 모델에 전달하고 이 결과는 다시 $y$를 예측하기 위해 parameter $W_y$와 함께 선형 출력층으로 전달된다:
[P(y \vert x^1, …, x^m) = \text{softmax}(h_l^m W_y)]
이는 다음 우도를 최대화하도록 한다:
[L_2(\mathcal{C}) = \sum_{(x, y)} \log P(y \vert x^1, …, x^m)]
미세조정 단계에 언어모델을 보조 목적함수로 포함시키는 것은 다음 이유에서 학습을 돕는다.
- 지도 모델의 일반화를 향상시키고
- 수렴을 가속화한다.
이는 이전 연구들과 결을 같이한다.
구체적으로, weight $\lambda$에 대해 다음 목적함수를 최적화한다:
[L_3(\mathcal{C}) = L_2(\mathcal{C}) + \lambda \ast L_1(\mathcal{C})]
종합적으로, 미세조정 단계에서 추가된 parameter는 $W_y$과 구분자 token을 위한 embedding 뿐이다.
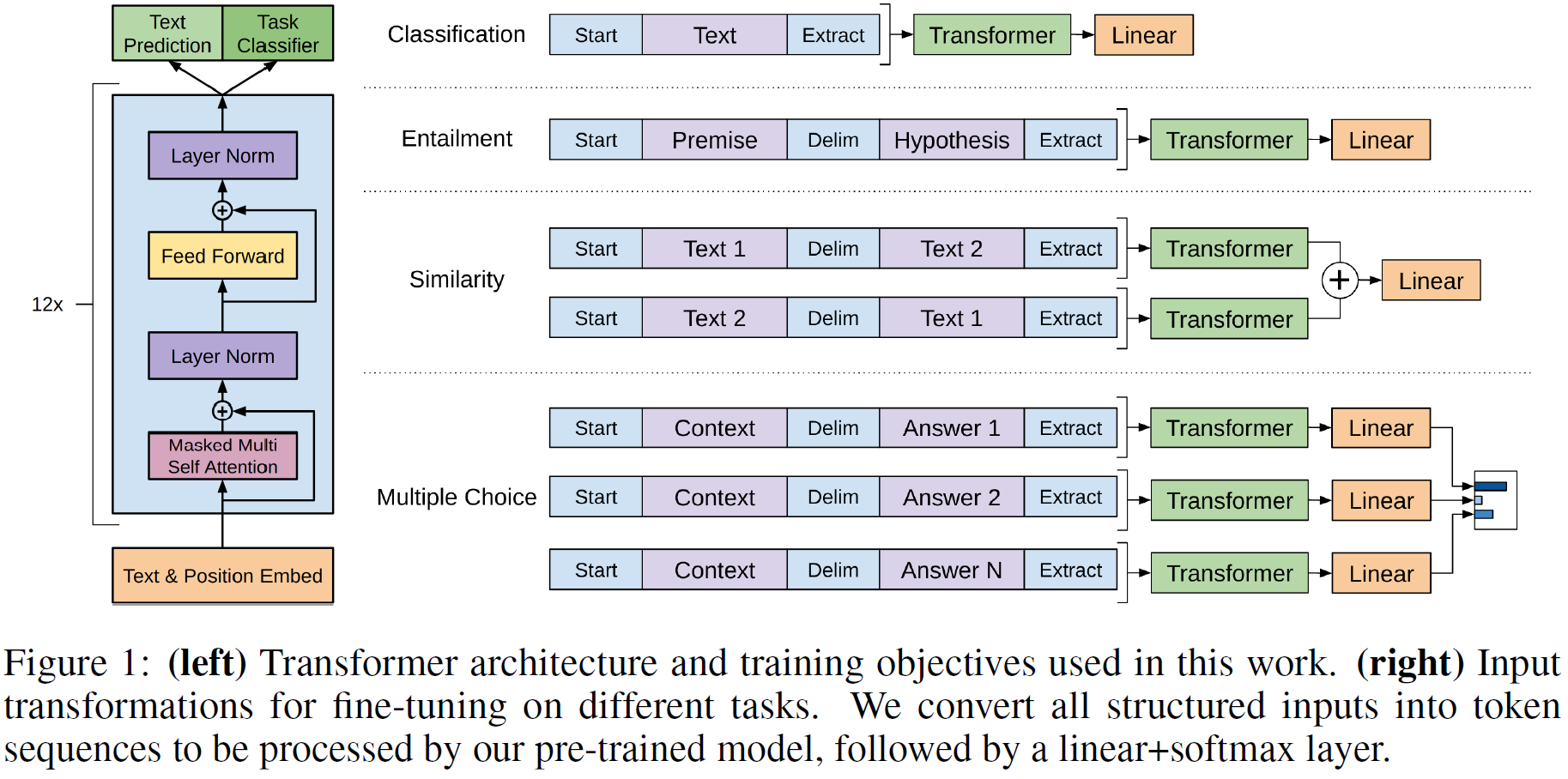
3.3. Task-specific input transformations
텍스트 분류와 같은 몇몀 과제에 대해서는 모델 미세조정을 위에서 언급한 방법으로 직접 할 수 있다. 그러나 질답과 원문함의와 같은 과제에서는 입력 형태가 문장의 2~3개 쌍인 등 많이 다르므로 이를 처리해주어야 한다. 그 방법은 아래 Figure 1에 나와 있는데, 질문/텍스트/선택지/가정/전제 등을 하나씩 따로 구분자(delimiter)로 구분하여 하나로 연결하는 방식을 쓴다. 구체적인 방법은 다음과 갈다.
Textual entailment
함의 문제에서는 전제 $p$와 가정 $h$를 구분자 $로 연결하였다.
Similarity
두 개의 텍스트 사이에 순서가 딱히 없으므로 텍스트 두 개를 다른 순서로 이어붙여 총 2개를 입력으로 쓴다. 이는 각각의 Transformer에 입력으로 들어간다.
Question Answering and Commonsense Reasoning
문맥 문서 $z$, 질문 $q$, 가능한 답변 ${a_k}$이라 하면, [z; q; $; a_k]로 연결하고 입력의 개수는 답변의 개수만큼 생성된다.
4. 실험(Experiments)
4.1. Setup
Unsupervised pre-training
언어모델을 학습하기 위한 dataset으로 7천 개의 다양한 분야의 미출판 책에 대한 내용을 포함하는 BooksCorpus를 사용한다. 이는 특히 넓은 범위에 걸친 언어적 정보를 포함하기에 중요하다. 대안이 되는 dataset으로는 ELMo에서 사용된 1B Word Benchmark가 있다. 이는 크기는 비슷하지만 문장들이 서로 섞여 있어 장거리 의존정보가 파괴되어 있다.
사용하는 dataset 정보는 아래와 같다.

Model specifications
Transformer의 세부 세팅을 대부분 따르지만, Encoder-Decoder 중 Decoder만 사용한다. 이 decoder는 원본은 6번 반복되지만, GPT는 12번 반복한다.
| Parameter | Descrption |
|---|---|
| State dimension | decoder: 768, inner state: 3072 |
| Batch size | 64 random sample $\times$ 512 token/sample |
| Schedule | 100 epochs, |
| Optimizer | Adam |
| Learning Rate | 0~2000 step까지 2.5e-4까지 증가, 이후 cosine 함수를 따라 0으로 서서히 감소 |
| warmup_steps | 4000 |
| Regularization | L2($w=0.01$) |
| Activation | GELU(Gaussian Error Linear Unit) |
논문에는 안 나와있지만 모델의 크기는 parameter가 117M개이다.
Fine-tuning details
비지도 사전학습에서 사용한 hyperparameter를 그대로 사용했다. $p=0.1$의 dropout을 추가했다.
learning rate는 6.25e-5와 batch size는 32, 미세조정은 3 epoch 동안 진행되었으며 learning rate decay는 warmup을 포함해 각 학습당 0.2%였고, $\lambda=0.5$이다.
4.2. Supervised fine-tuning
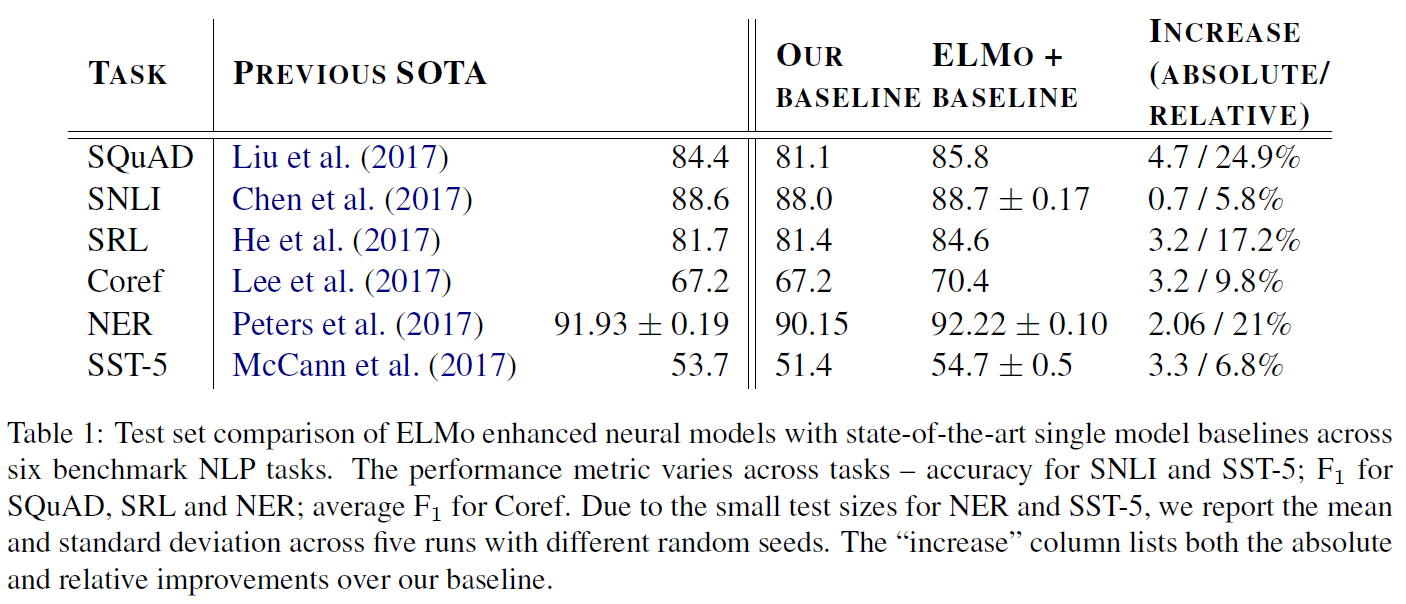
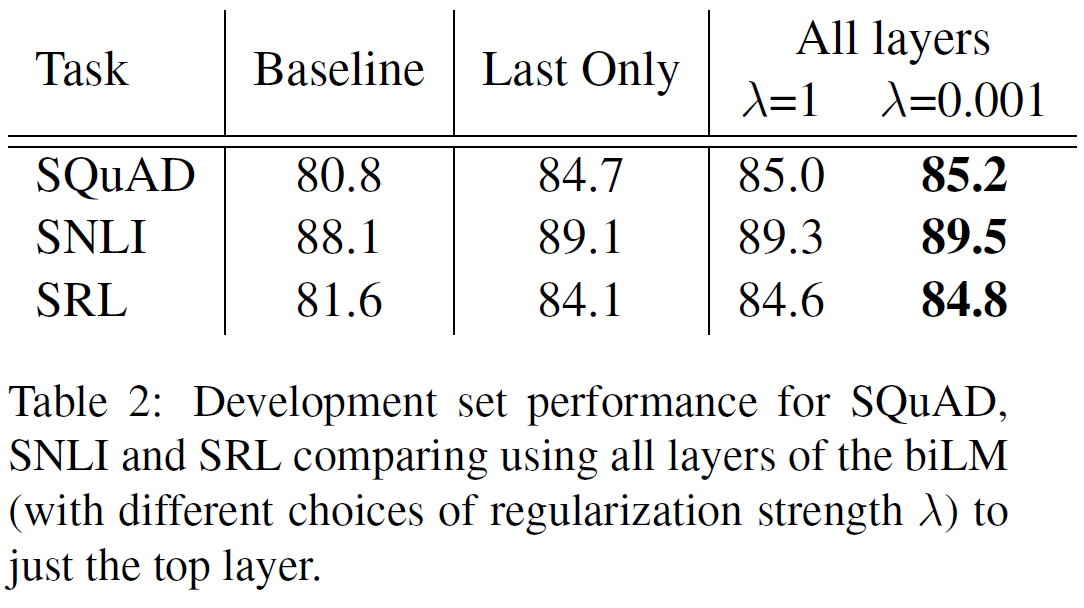
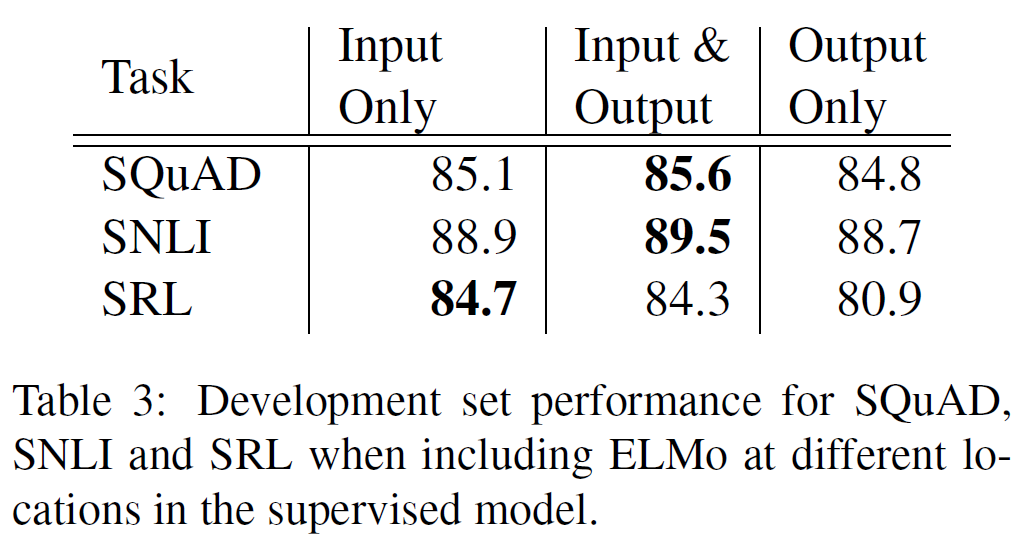
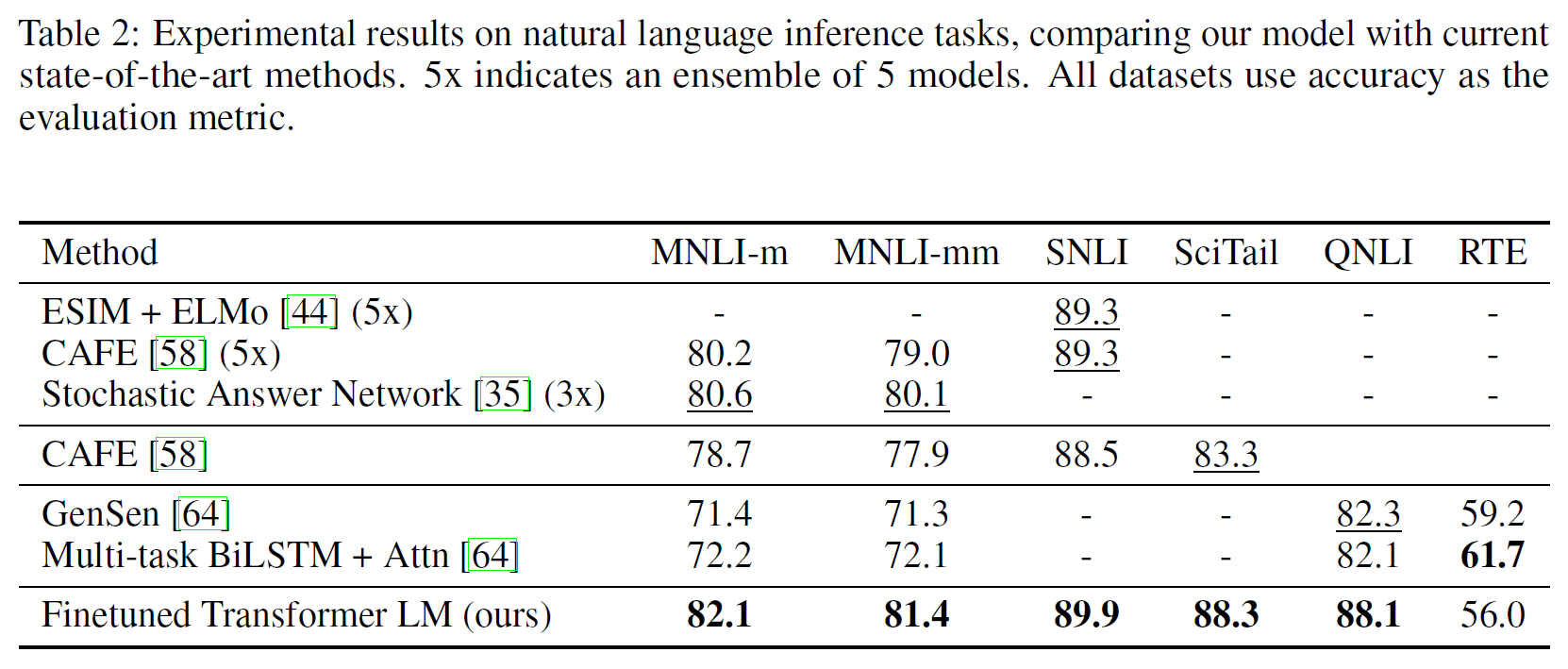
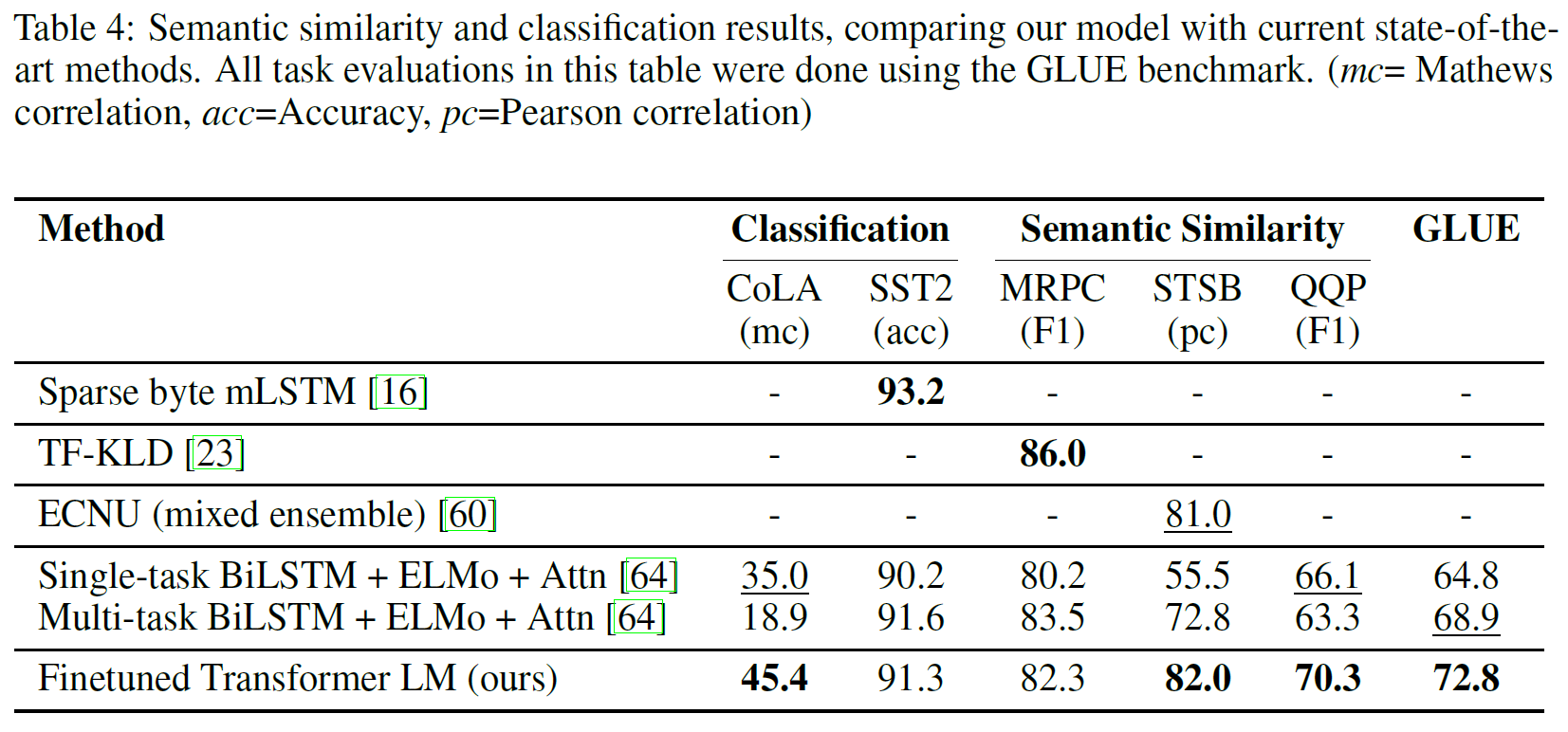
자연어추론, 질답, 의미유사성, 문서분류에 대해 평가를 진행하였으며 이 중 일부는 GLUE benchmark에 포함되어 있다. 결과는 아래 Table 2, 3에 있다.
Natural Language Inference
Image caption(SNLI), 문서화된 음성, 대중소설, 정부 보고서(MNLI), 위키피디아 기사(QNLI), 과학시험(SciTail), 뉴스기사(RTE) 등의 다양한 데이터로 실험하였다. 각 0.6~5.8% 정도 성능이 향상되었다.
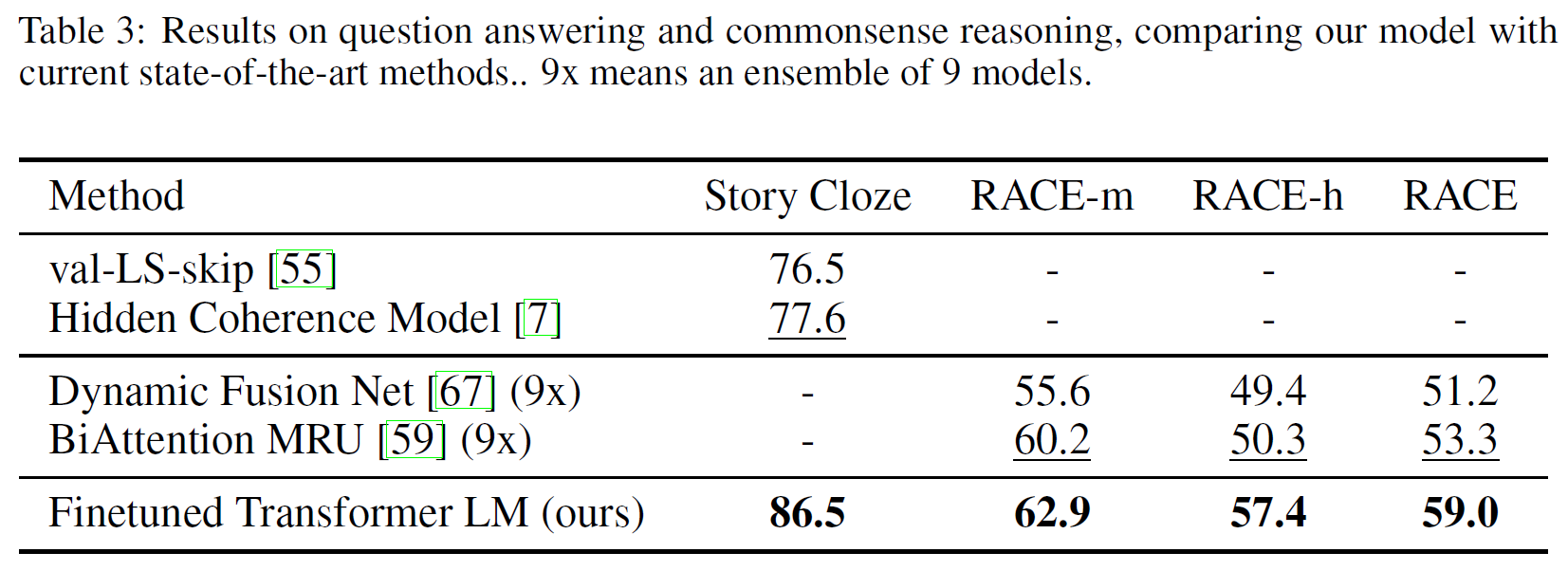
Question answering and commonsense reasoning
중고등학교 시험에서 나온 영어지문과 관련 질문으로 구성된 RACE dataset으로 진행하였다. 또 Story Cloze에 대해서도 진행했는데 이는 무려 8.9%까지 높은 성능을 내며 결과를 종합했을 때 GPT가 넓은 범위에 걸친 문맥 정보도 잘 포착해냄을 알 수 있다.
Semantic Similarity
QQP에 대해서는 BiLSTM + ELMo + Attention을 사용한 모델보다도 특히 성능이 향상되었다.
Classification
두 개의 다른 텍스트 분류 과제에 대해서도 평가를 진행했다. CoLA(The Corpus of Linguistic Acceptability)는 어떤 문장이 문법적으로 옳은지를 전문가가 평가한 답변과, 학습된 모델에 대한 언어적 편향에 대한 테스트를 포함한다. SST-2(The Stanford Sentiment Treebank)는 표준 이진 분류 문제이다. CoLA에 대해서는 35.0 $\to$ 45.4점으로, SST-2에서는 68.9 $\to$ 72.8점으로 상승하였다.
종합하면, 12개의 task 중 9개에서 state-of-the-art를 달성하였다.
5. 분석(Analysis)
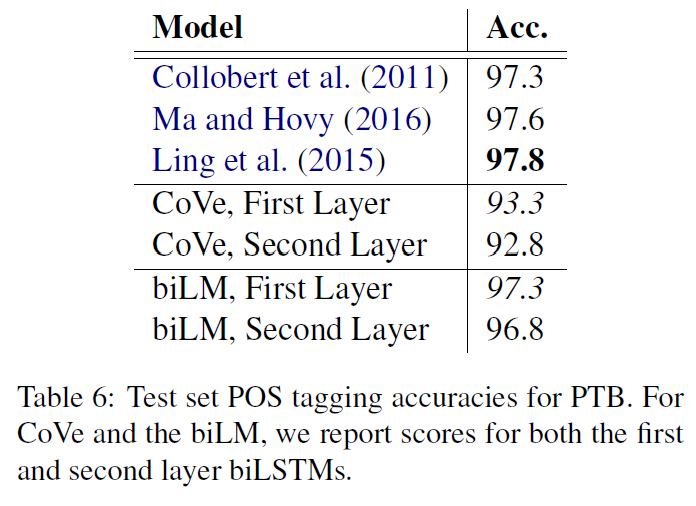
Impact of number of layers transferred
아래 Figure 2의 왼쪽은 layer의 수를 다르게 하면서 RACE와 MultiNLI에 대해 실험을 진행한 것인데, transferring embedding이 성능 향상을 가져오며, 각 transformer layer 당 9%까지 향상시킨다(on MultiNLI)는 내용이다. 이는 사전학습된 모델의 각각의 layer가 문제를 푸는 데 있어 유용한 기능을 포함한다는 것을 의미한다.
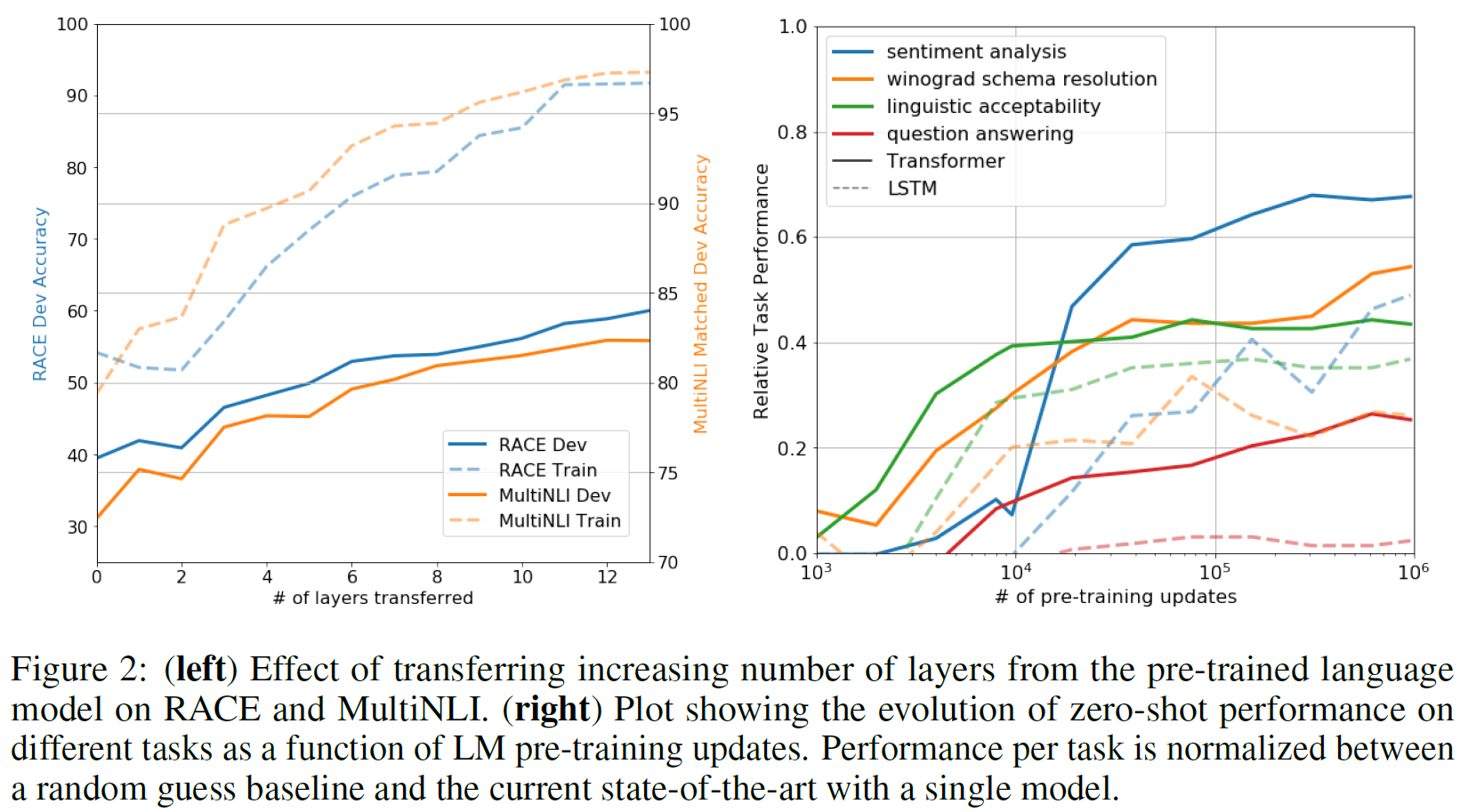
Zero-shot Behaviors
저자는 근본적인 generative model이 LM capability를 향상시키기 위해 많은 task를 수행하는 법을 배울 수 있고, LSTM과 비교해서 transformer의 attentional memory가 transfer에 도움이 된다고 가정하였다
Transformer를 통한 언어모델의 사전학습이 효과적인지에 대한 가정이 하나 있다. 기반 생성모델은 언어모델링 역량을 향상시키기 위해 평가에 포함된 여러 과제를 수행하는 것을 학습하였으며, Transformer의 attentional memory는 LSTM에 비해 전이를 더 원활하게 해 준다는 것이다. 지도 미세조정 없이 과제를 수행하기 위해 기반 생성모델을 사용하는 일련의 체험적 해결책(heuristic solutions)을 사용했다. 이 결과를 위 Figure 2의 오른쪽 부분에 시각화하였다.
이 체험적 해결책의 성능은 안정적이며 학습에 따라 꾸준히 증가하는 것으로 보아 생성적 사전학습은 과제와 관련된 넓은 범위의 기능성(functionality)의 학습을 뒷받침한다. 또한 LSTM은 zero-shot 성능에서 큰 편차를 보여 Transformer 구조의 귀납적 편향이 전이를 돕는다고 할 수 있다.
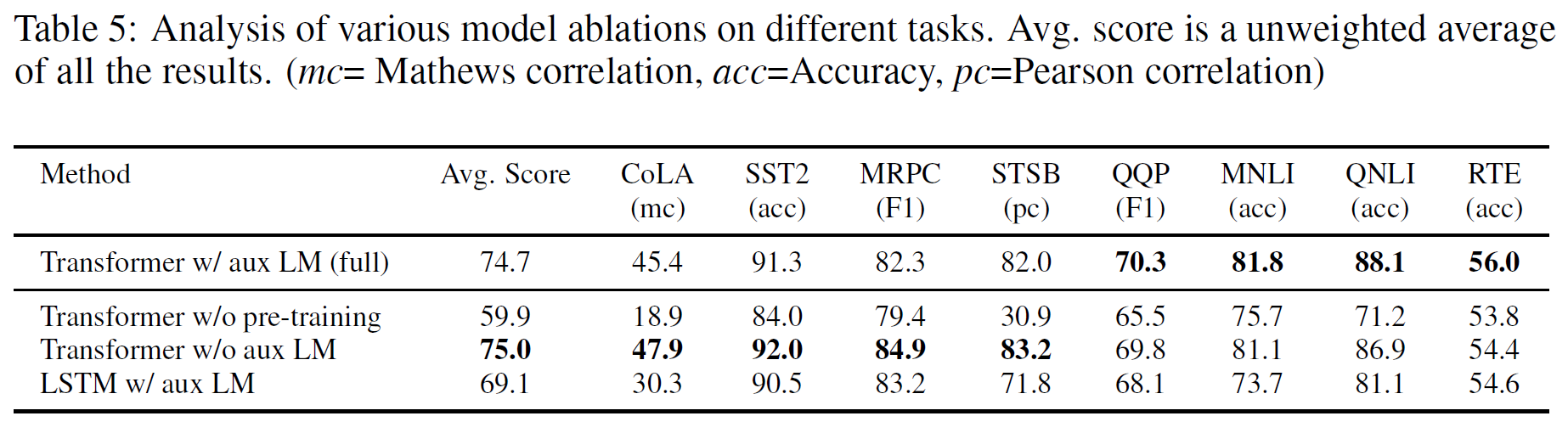
Ablation studies
세 가지 분석을 수행하였다.
- 미세조정 단계에서 보조 LM 목적함수는 NLI task와 QQP에 도움을 주는데, 큰 dataset에서는 이점이 있지만 작은 dataset에서는 그렇지 못함을 보여준다.
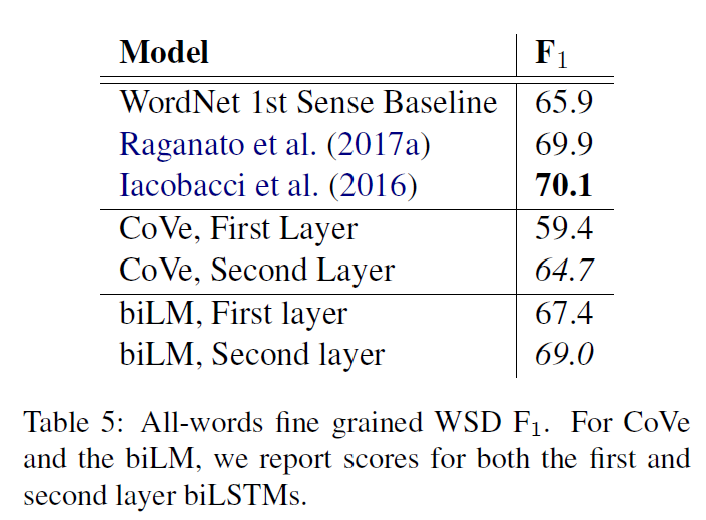
- Transformer을 같은 구조의 2048 unit의 LSTM로 대체하였는데 5.6점의 점수 하락이 있었다. 성능이 좋은 경우는 MRPC 뿐이었다.
- Transformer를 사전학습 없이 바로 지도학습을 하도록 해보았는데, 14.8%의 성능 하락이 있었다.
6. 결론(Conclusion)
생성적 사전학습과 특정과제에 특화된 미세조정을 통해 학습된, 과제에 대해 별다른 지식이 없으며 자연어이해 능력이 뛰어난 단일 모델(framework)를 소개하였다. 넓은 범위에 걸친 언어적 정보를 포함하는 다양한 말뭉치에 대해 사전학습을 진행하여 중요한 일반지식과 질답, 의미유사성 평가, 함의 확인, 문서분류 등의 과제에서 성공적으로 전이되는 장거리 의존성을 처리하는 능력을 학습하여 12개 중 9개의 과제에 대해 state-of-the-art를 달성하였다. 특정 과제에 대한 성능을 높이는 비지도 사전학습은 기계학습연구의 중요한 목표가 되었다.
이 연구는 상당한 성능향상이 정말로 가능하며 어떤 모델(Transformers)과 dataset(장거리 의존성을 포함하는 텍스트)가 이 접근법에 가장 좋은지에 대한 조언을 제공한다. 이 연구가 자연어이해와 다른 분야에 대한 비지도학습에 대한 새로운 연구에 도움이 되기를 희망하며, 나아기 비지도학습이 언제 그리고 어떻게 작동하는지에 대한 우리의 이해를 증진시키기를 바란다.
Refenrences
논문 참조. 71개의 레퍼런스가 있다.
부록은 없다(yeah).