
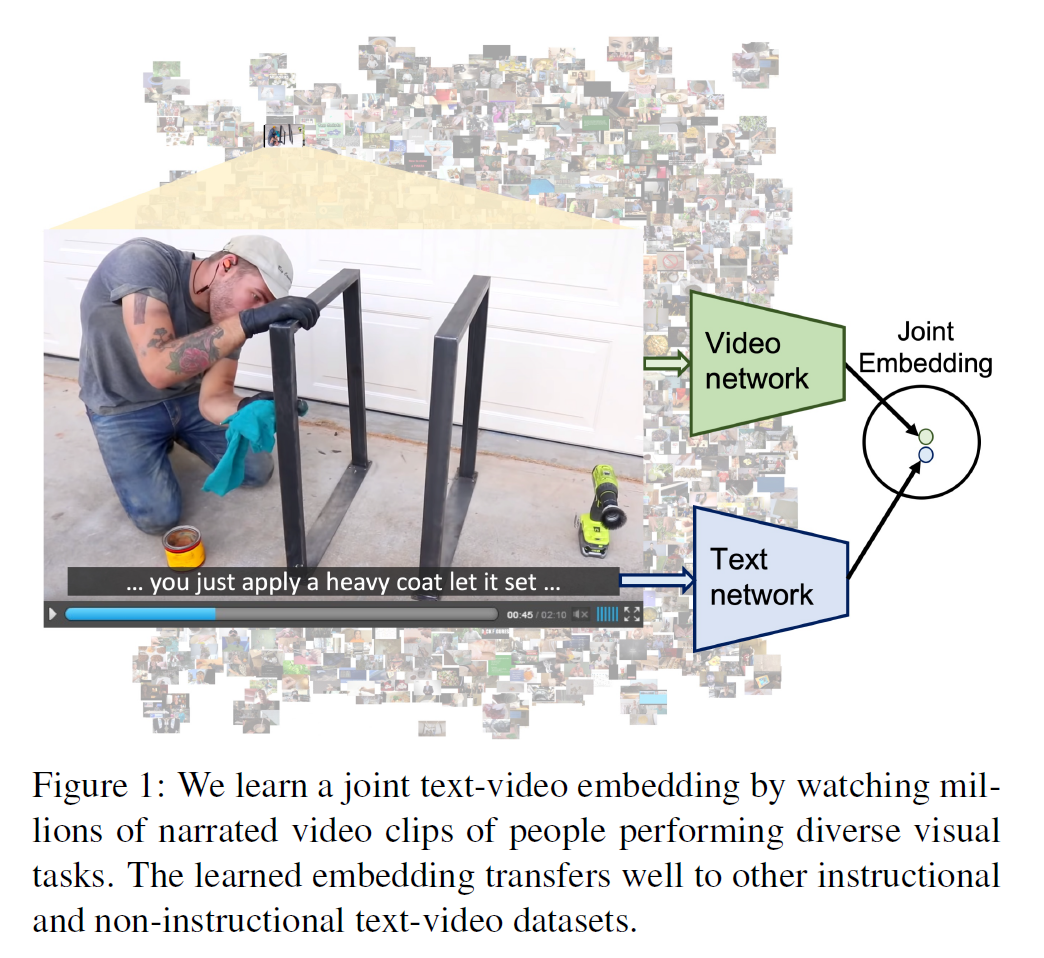
HowTo100M 설명(HowTo100M - Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips, Antoine Miech et al, 7 Jun 2019, 1906.03327)
18 Aug 2021 | Paper_Review Dataset목차
- HowTo100M - Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips
이 글에서는 2019년 ICCV에 발표된 HowTo100M - Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips 논문을 살펴보고자 한다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
HowTo100M - Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips
논문 링크: HowTo100M - Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips
데이터셋, 코드 및 모델: Project webpage
초록(Abstract)
Text-video 임베딩을 학습하는 것은 대개 video clip과 수동으로 만든 caption을 필요로 한다. 그러나 이러한 데이터셋은 만드는 것이 매우 비싸며 오래 걸리고 따라서 큰 규모의 데이터셋을 얻기 힘들다. 본 연구에서, 이러한 임베딩을 video에서 학습하는 대신 쉽게 얻을 수 있는 자동생성된 narration을 annotation으로 사용한다. 이 논문이 기여한 바는,
- HowTo100M 데이터셋 제안: 23k개의 다른 visual task를 묘사하는 절차적 web video에서 얻은 136M개의 video clip을 포함
- 위 데이터로 학습한 Text-video 임베딩이 text-to-video retrieval과 action localization에서 SOTA로 이끔을 보임
- 이 임베딩이 Youtube video나 movie 등 다른 domain에서 잘 transfer되는 것을 보임
1. 서론(Introduction)
실세계를 이해하고 상호작용하는 것은 시각적(영상) 정보와 언어(텍스트) 정보를 이해하고 상호작용하는 것과 매우 유사성이 높다. 그러나 text-to-video retrieval, video captioning, VQA 등의 task는 여전히 AI 시스템에게 있어 상당히 어려운 과제이다.
언어를 묘사하는 visual concept을 다루는 일반적인 방법은 text와 video를 공통 임베딩 공간으로 mapping하여 관련된 text와 video clip들이 비슷한 곳에 모여 있게 하는 것이다. 그러나 이러한 방법은 매우x2 큰 데이터셋을 필요로 하지만, 현존하는 데이터셋(MSR-VTT, DiDeMo, EPIC-KITCHENS) 등은 수동 생성한 annotation이 수천~수만 정도의 규모밖에 되지 않으며 그 품질 또한 낮은 경우도 있다.
본 연구에서는 video와 language의 결합표현을 학습할 수 있는 video clip과 text caption 쌍을 얻는 방법을 탐색하였다. YouTube에서 narrated instructional video는 규모가 크고 대량의 visual/language 데이터를 얻을 수 있다. Instructional video는 대개 narration을 포함하며 명시적으로 영상의 내용을 설명하기에 학습용으로 적합하다.
따라서 YouTube에서 23k 종류 이상의 서로 다른 task를 수행하는 것을 묘사하는 1.22M개의 narrated instructional video를 수집하였다. 각 clip은 자동 생성된 narration 형식으로 text annotation와 연결되어 있다.
기여한 바가 적혀 있는데, 이는 초록의 내용과 같다.
2. 관련 연구(Related Work)
Visual/textual cue의 이해에 기반한 여러 CV task가 제안되어 왔다.
Vision, language and speech
Visual/Textual cue가 서로 비슷한 경우에만 공통 공간 내에서 인접하게 하는 방식이 일반적이다. 이들은 대부분 잘 annotated된 데이터셋을 필요로 하기에 상당히 비용이 비싸다.
본 논문에서는 수동으로 annotation을 일절 하지 않고 자동 생성된 narration만을 사용한다. Spoken text를 사용하는 모델이 있었지만 음성 녹음이 안 되어 있거나 그 규모가 매우 작은 편이었다.
Learning from instructional videos
복잡한 과제를 해결하는 학습 과정으로써 최근 주목받고 있다. Visual-linguistic reference resolution, action segmentation 등의 task에서 여러 모델이 제안되었으나 역시 적은 수의 미리 지정된 label에서 추출한 trasncription만이 존재했다.
이후 WikiHow, COIN, CrossTask 등의 데이터셋이 만들어졌고 이들은 대개 YouTube에서 대량의 영상 정보를 획득하였다. HowTo100M도 비슷하게 YouTube에서 영상을 얻었으나 그 양이 전례없이 매우 방대하다.
Large scale data for model pretraining
Noisy할 수도 있는 web data로부터 얻은 대규모 데이터셋은 language 및 vision 모델에서 유망한 부분이다. BERT, GPT-2 등은 대규모 데이터를 사용하여 많은 task에서 SOTA를 달성하였다. GPT-2와 WebText는 Reddit에서 얻은 40GB의 text를 사용하여 좋은 결과를 얻었다.
이에 영감을 받아 video와 language의 공통 임베딩을 학습하고자 하였다. YouTube에서 얻은 1M 이상의 영상을 사용하여, 미세조정 없이도 instructional video에서 이전 결과를 넘을 뿐 아니라 non-instructinoal video에 대해서도 잘 작동한다.
3. The HowTo100M dataset
요리, 수공예, 개인 생활/관리, 원예 등의 활동에 대한 내용을 포함하는 1.22M개의 영상을 포함한다. 각 영상은 (올린 사람이 만들었을) 자막 혹은 ASR로 자동 생성된 narration을 가진다.
3.1 Data collection
Visual tasks
- Instructional video는 어떻게 특정 활동을 수행하는지를 묘사하기 때문에 어떤 활동이 있는지를 먼저 WikiHow(“어떻게 무엇을 하는가”라는 12만 개의 article 포함)에서 가져왔다.
- 많은 영상들 중 추상적인 것(“선물 선택하기”)보다는 “시각적인” 활동(“땅콩버터 만들기”)에 초점을 맞추었다. Task는 12종류로 한정하였고 관계/경제/사업 등 추상적인 task는 제외하였다.
- “물리적인” 활동이 포함되는 것(make, build, change)을 남기고 그렇지 않은 것(be, accept, feel)은 반자동으로 제거하였다.
- 최종적으로 23,611개의 visual task가 생성되었다.

Instructional videos
How to <task name> 형태의 제목을 가지며 영어 자막(사람이 올렸거나 혹은 YouTube API인 ASR로 얻은 것)을 가지는 영상을 찾았다. 이후 다음 과정을 통해 품질과 일관성을 높였다.
- 검색 결과의 상위 200까지만 사용하고 나머지는 관련성이 별로 없을 가정하에 제외함
- 조회수 100 미만의 영상은 제외
- 100 단어 이하의 영상은 배울 것이 별로 없으므로 제외
- 2,000초 이하의 영상만 사용
- 중복 영상(동일 ID) 제거
3.2 Paired video clips and captions
자막은 text의 뭉치들로 이루어져 있으며 때때로 완전한 문장의 형태가 아닌 경우도 있다. 각 줄은 영상의 특정 구간과 연관된다(특히 그 자막이 읽히는 부분). 각 자막을 caption으로 사용하여 video clip의 연관된 구간과 쌍을 만든다(그림 2).
MSR-VTT와 같은 clip-caption 쌍으로 구성된 다른 데이터셋과 달리 HowTo100M은 자동으로 만든 narration을 사용한다. 그래서 (아마도) 약하게 짝을 이룬(weakly paired) 것으로 생각된다. 영상에서는 구독자와 소통하는 등 주제와 상관 없는 내용이 있을 수도 있고 문장도 완전하지 않거나 문법적으로 틀릴 수도 있다. 임의로 400개의 clip-caption 쌍을 선택해서 확인한 결과 자막에 포함된 물체나 행동 등이 적어도 한 번 나올 확률은 51%였다.
Statistics
12개의 분류로 나누어져 있으며 예시는 그림 2에서 볼 수 있다. 자세한 내용은 부록 A에 있다.
각 데이터셋의 clip-caption의 개수는 표 1에서 볼 수 있다.
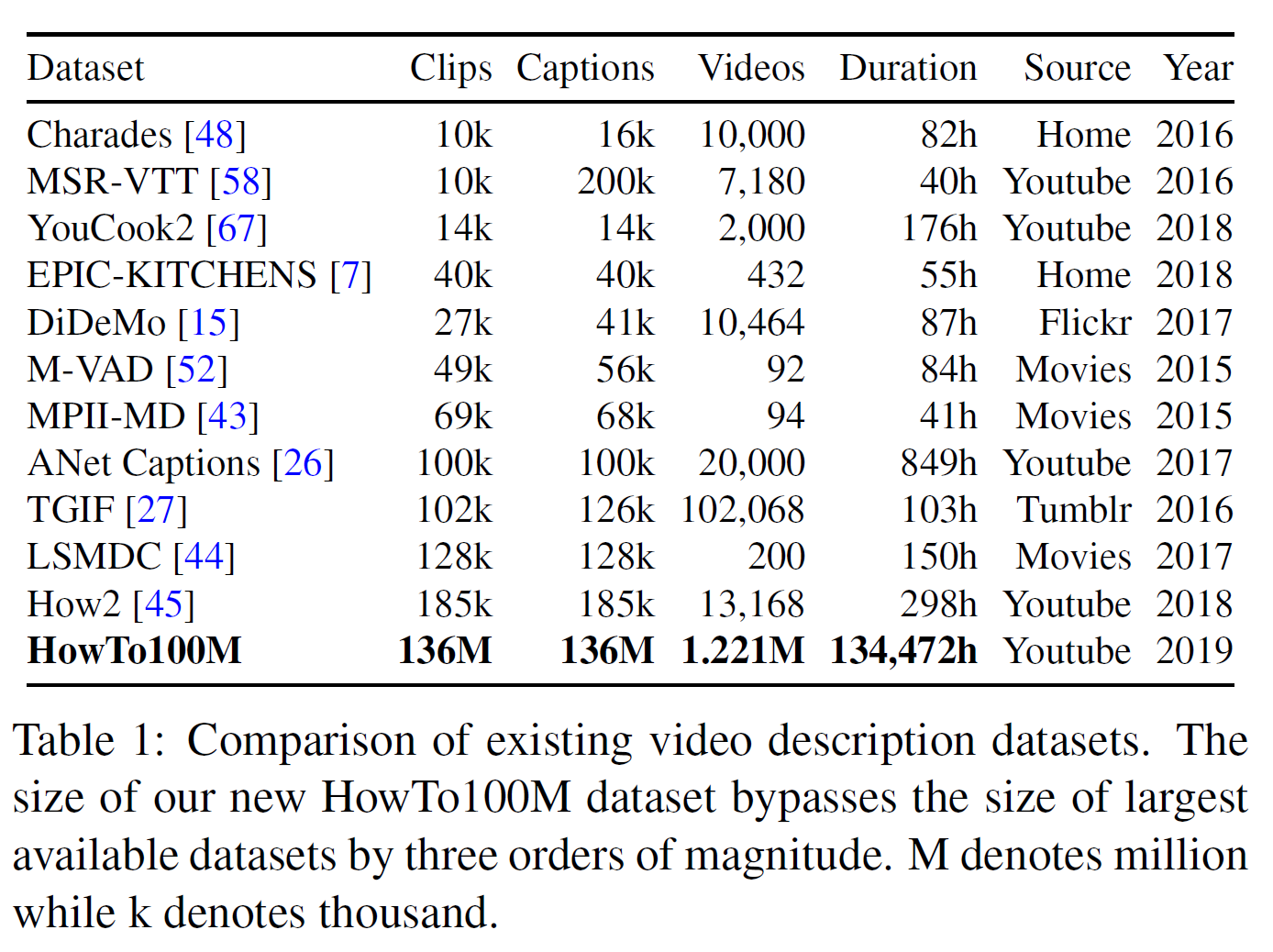
HowTo100M은,
- 다른 데이터셋에 비해 훨씬 크다.
- 자동 생성된 annotation을 사용하여 자막의 품질이 깨끗하지 않다.
- 평균적으로 하나의 영상은 110개의 clip-caption 쌍을 만들며 clip당 4초, 4단어 정도이다.
- 100개를 임의로 확인한 결과 71%는 instructional한 영상, 12%는 vlog, 7%는 리뷰나 광고였다.
- vlog나 리뷰, 광고는 시각적인 내용과 narration 사이의 관련성이 있을 수 있다.
- non-instructional video를 특별히 제거하지는 않았는데, 공통 임베딩을 학습하는 데 도움을 줄 수 있어서다.
4. Text-video joint embedding model
$n$개의 video clip과 연관된 caption $\lbrace (V_i, C_i) \rbrace^n_{i=1}$이 주어진다.
\[\mathbf{v} \in \mathbb{R}^{d_v}, \mathbf{c} \in \mathbb{R}^{d_c}\]목적은 video와 caption feature를 $d$차원의 공통 공간으로 mapping하는 함수를 만드는 것이다.
\[f : \mathbb{R}^{d_v} \rightarrow \mathbb{R}^{d}, \quad g : \mathbb{R}^{d_c} \rightarrow \mathbb{R}^{d}\]cosine 유사도는 caption $C$가 video clip $V$를 묘사하면 큰 값을 갖는다.
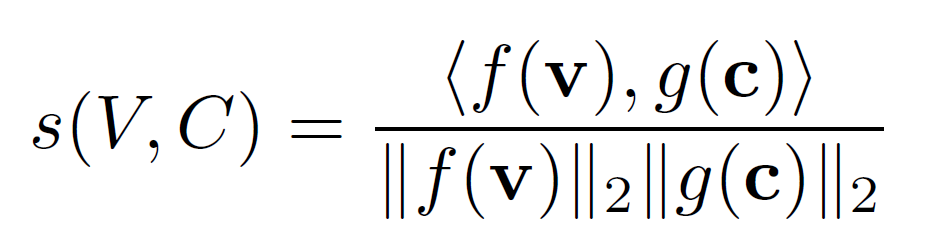
비선형 embedding 함수를 사용한다. $W$는 학습가능한 parameter이고 $\circ$는 내적을 의미한다.
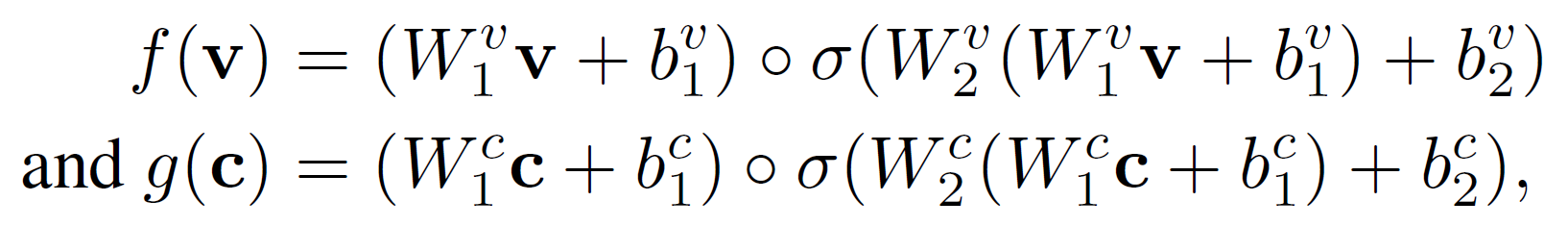
실험에서는 $d$는 모두 4096을 사용하였고 총 parameter 개수는 67M개이다.
위 식의 오른쪽 부분은 선형 FC layer로 거기에 gating function을 더해 출력 범위는 $0\sim1$이 된다. 결과적으로 embedding function은 입력 벡터간 비선형 곱연산 상호작용을 모델링한다.
Loss
max-margin ranking loss를 사용한다. 각 반복 동안 mini-batch $\mathcal{B}$의 caption-clip 쌍 $(V_i, C_i)_{i \in \mathcal{B}}$에 대해서 손실함수는
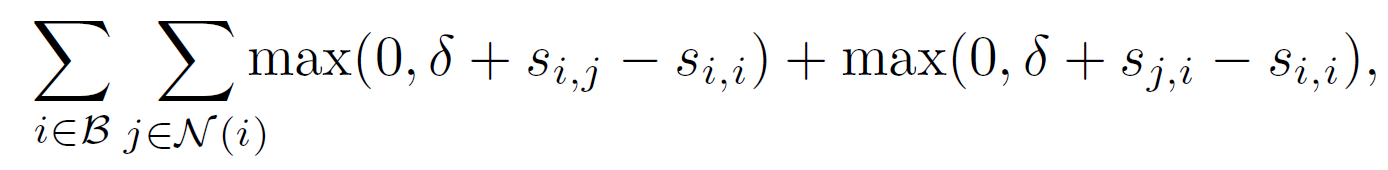
이다.
\[\mathcal{B}=\lbracei_1, ..., i_b \rbrace \subset \lbrace1, ..., n \rbrace\]- $s_{i,j}$는 video clip과 caption 간 유사도 점수이다.
- $\mathcal{N}_i$는 caption-clip $i$에 대한 negative pair이다.
- $\delta$는 margin이다. 실험에서는 $\delta=0.1$이다.
Sampling strategy
Negative pair $ \lbrace(V_i, C_i) : i \ne j \rbrace$ 의 절반은 같은 원본 YouTube 영상에서 만들어졌고, 나머지 절반은 서로 다른 영상에서 가져온 것이다. 본 논문에서 intra-negative sampling을 적용하여 학습된 embedding이 주제와 관련 없는 배경보다는 상관이 있는 부분에 중점을 두도록 하였다. 부록 C에서 positive에 대한 설명을 볼 수 있다.
또한 학습 데이터 자체가 일부 noisy하기 때문에 더 이상의 sampling 방식은 성능 개선으로 이어지지 않았다.
Clip and caption representation
clip feature $\mathbf{v}$는 temporally max-pooled pre-extracted CNN feature로 구성된다. caption feature $\mathbf{c}$는 미리 계산된 단어 임베딩 위에 있는 얕은 1D-CNN의 출력값이다. 자세한 내용은 5.1절을 참조한다.
5. 실험(Experiments)
어떻게 강력한 video-text 표현을 학습할 수 있는지 설명한다. CrossTask, YouCook2, MSR-VTT, LSMDC 등에서 실험한 결과를 보고한다.
실험 결과는,
- CrossTask, YouCook2 등 instructional 영상 데이터셋에서는 HowTo100M에서 학습된 off-the-shelf 임베딩이 매우 작고 수동으로 만든 데이터셋에 비해 훨씬 좋다.
- 일반적인 YouTube 영상을 모아놓은 MSR-VTT 같은 데이터셋에서, HowTo100M 임베딩은 MSR-VTT에서 학습된 모델과 비등한 성능을 보여준다.
- MSR-VTT의 일부만 갖고 미세조정한 HowTo100M 모델이 SOTA를 능가한다.
- LSMDC에서 미세조정한 임베딩은 domain의 큰 차이에도 불구하고 video, script에 대한 일반화 성능이 뛰어나다.
- HowTo100M의 규모의 중요성을 증명한다.
5.1. Implementation details
Video features
사전학습한 2D/3D CNN에서 frame/video 수준 feature를 추출한다.
- 2D는 1초당 1 frame 비율로 ImageNet으로 사전학습한 Resnet-152를 사용한다.
- 3D는 1초당 1.5 feature 비율로 Kinetics로 사전학습한 ResNeXt-101 16frames 모델을 사용한다.
Temporal max-pooling으로 더 긴 video clip에 대한 feature를 aggregate하고 2D와 3D feature를 이어 붙여서 각 clip당 4096차원의 벡터를 최종 생성한다.
Text pre-processing
- 일반적인 영어 stop-word를 제거한다.
- GoogleNews의 사전학습된 word2vec을 사용한다.
Training time
- feature 추출 이후 전체 데이터셋에 대해 임베딩 모델을 학습하는 것은 상대적으로 시간이 적게 걸리며 하나의 Tesla P100 GPU에서 3일이 걸리지 않았다.
5.2. Datasets and evaluation setups
Action step localization
CrossTask는 18개의 task, 수동 생성한 action segment annotation이 있는 2.7k개의 instructional video를 포함한다. 또한 각 task당 짧은 자연어 설명으로 된 action step 순서를 제공한다. HowTo100M에서 학습한 모델을 CrossTask의 video의 모든 frame과 action label의 유사도를 계산하여 step localization을 수행한다.
Cross-task weakly supervised learning from instructional videos에서와 같은 평가 방식을 사용한다.
Text-based video retrieval
자연어 query를 사용하여 video clip retrieval task에서도 실험하였다. Textual description이 주어지면, 수많은 video 중에서 이를 표현하는 video clip을 찾는 문제이다. R@1, R@5, R@10 과 median rank(MR)로 평가기준을 사용하였다.
- YouCook2: YouTube에서 모은 요리 영상 데이터셋으로 89개의 recipe, 14k개의 clip을 포함하며 모두 수동 생성한 annotation을 포함한다. text set clip이 주어지지 않으므로 3.5k개를 validation set으로 사용한다. HowTo100M에 있는 일부 annotation은 제거하였다.
- MSR-VTT: 음악, 영화, 스포츠 등 20가지 분류를 묘사하는 257개의 video query에서 모든 일반 영상들로 200k개의 clip 및 수동 생성된 annotation을 포함한다.
- LSMDC: 101k개의 영화 clip-caption으로 이루어진 데이터셋으로 자막 또는 audio description이 연결되어 있다. 1000개의 쌍을 test set으로 사용했다.
5.3. Study of negative pair sampling strategy
임베딩을 학습할 시 negative caption-video 쌍을 샘플링하는 전략을 실험해 보았다.

같은 영상에서 negative를 찾는 intra-negative 방식이 좋다는 것을 알 수 있다. 이는 MSR-VTT이나 LSMDC보다 더 fine-grained한 데이터셋인 YouCook2와 CrossTask에서 더 두드러진다.
5.4. Scale matters
실제로 HowTo100M과 같은 대규모 데이터셋이 필요한지를 알아본다. 그래서 데이터셋 중 일부분만 사용하여 사전학습을 시킨 다음 다른 데이터셋에 대해 실험한 결과는 다음과 같다.
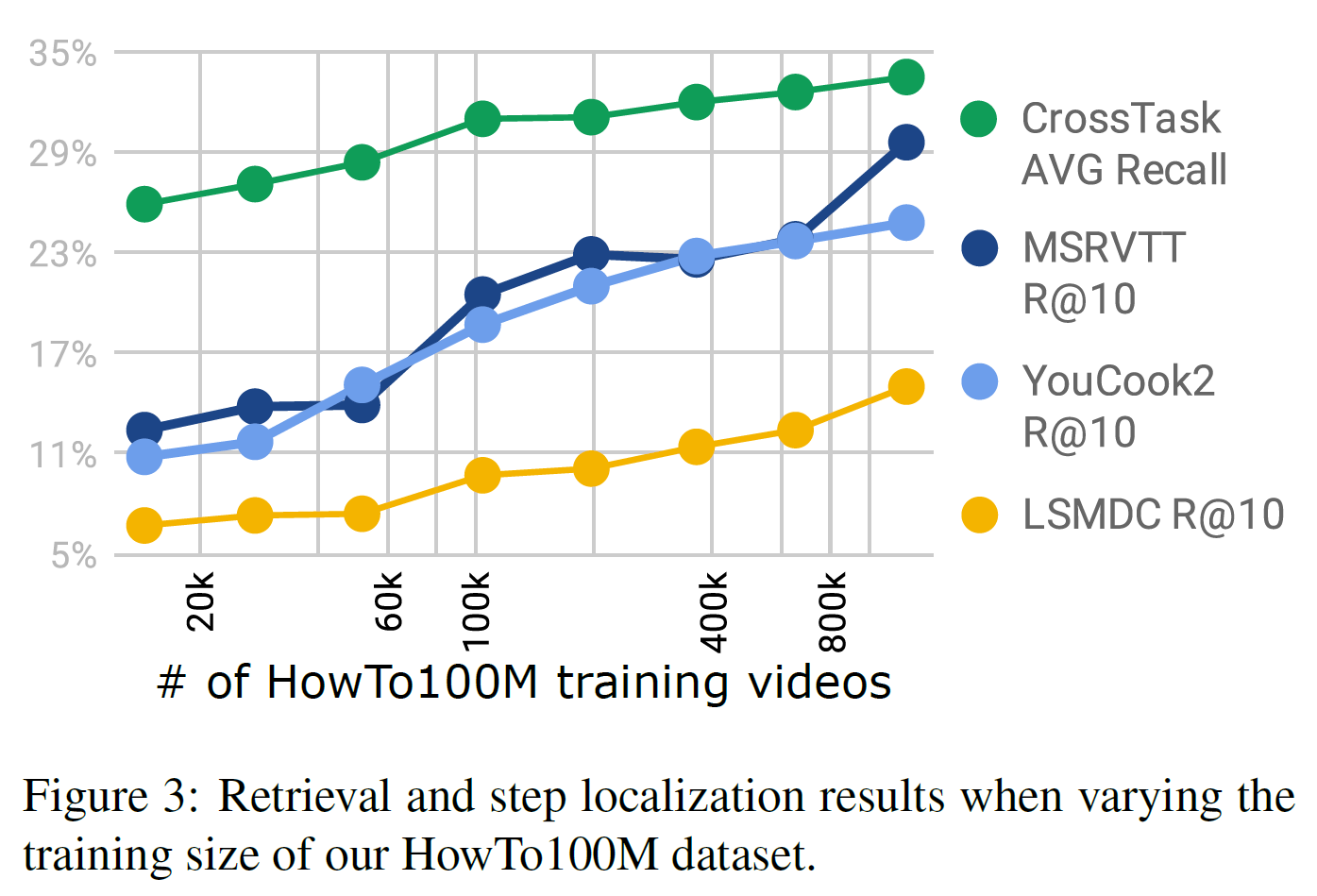
학습에 사용한 영상의 수가 많을수록 성능이 좋기 때문에, 대규모 데이터셋의 필요성이 입증되었다. 그리고 수렴하는 것도 관찰되지 않았기 때문에 더 많은 데이터를 모아 성능을 더욱 향상시킬 가능성도 있다.
5.5. Comparison with state-of-the-art
CrossTask
현재 SOTA인 약한 지도학습 방식의 모델과 비교하여 HowTo100M에서 학습한 off-the-shelf 임베딩을 비교한다. 기존 모델은 step localization에 최적화되었던 것임에도 본 논문의 모델이 한 task를 제외하고 모든 task에서 성능이 더 좋다.
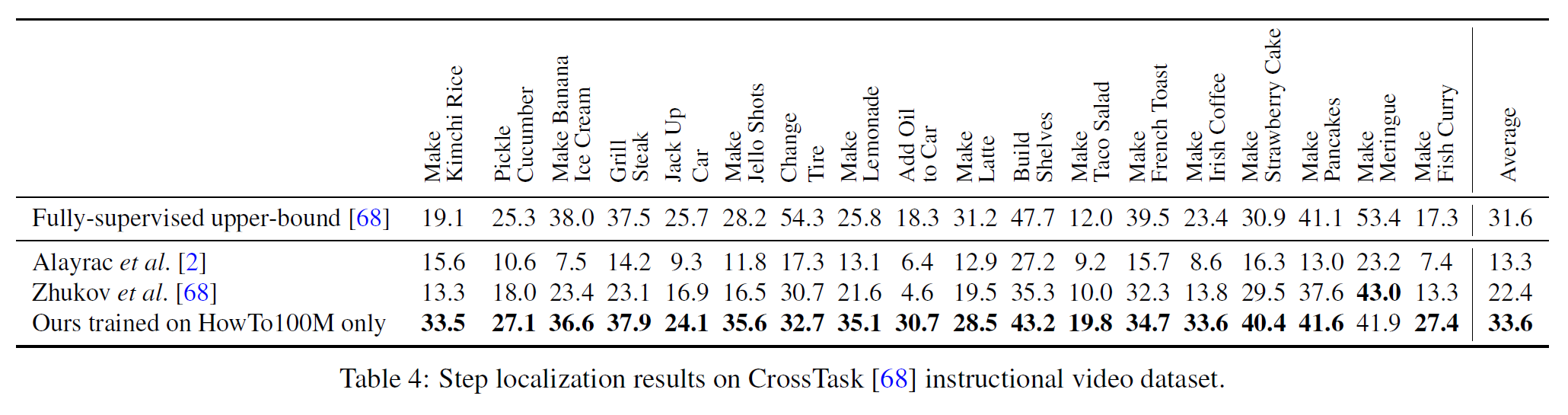
따라서 대용량의 narrated video로 학습하는 방식이 annotation이 있더라도 소규모의 데이터셋으로 학습하는 것보다 더 낫다고 결론내릴 수 있다.
YouCook2
이후 실험에서는
- HowTo100M로만 학습한 모델
- MSR-VTT로만 학습한 모델
- HowTo100M에서 사전학습하고 MSR-VTT에서 미세조정한 모델
위 3가지를 실험에 사용하였다.
공식 benchmark가 없어서 HGLMN FV CCA embedding 모델을 사용하였다.
결과는 YouCook2에서 직접 학습한 모델보다 더 좋으며 R@10에서 13.7%의 향상이 있기도 했다.
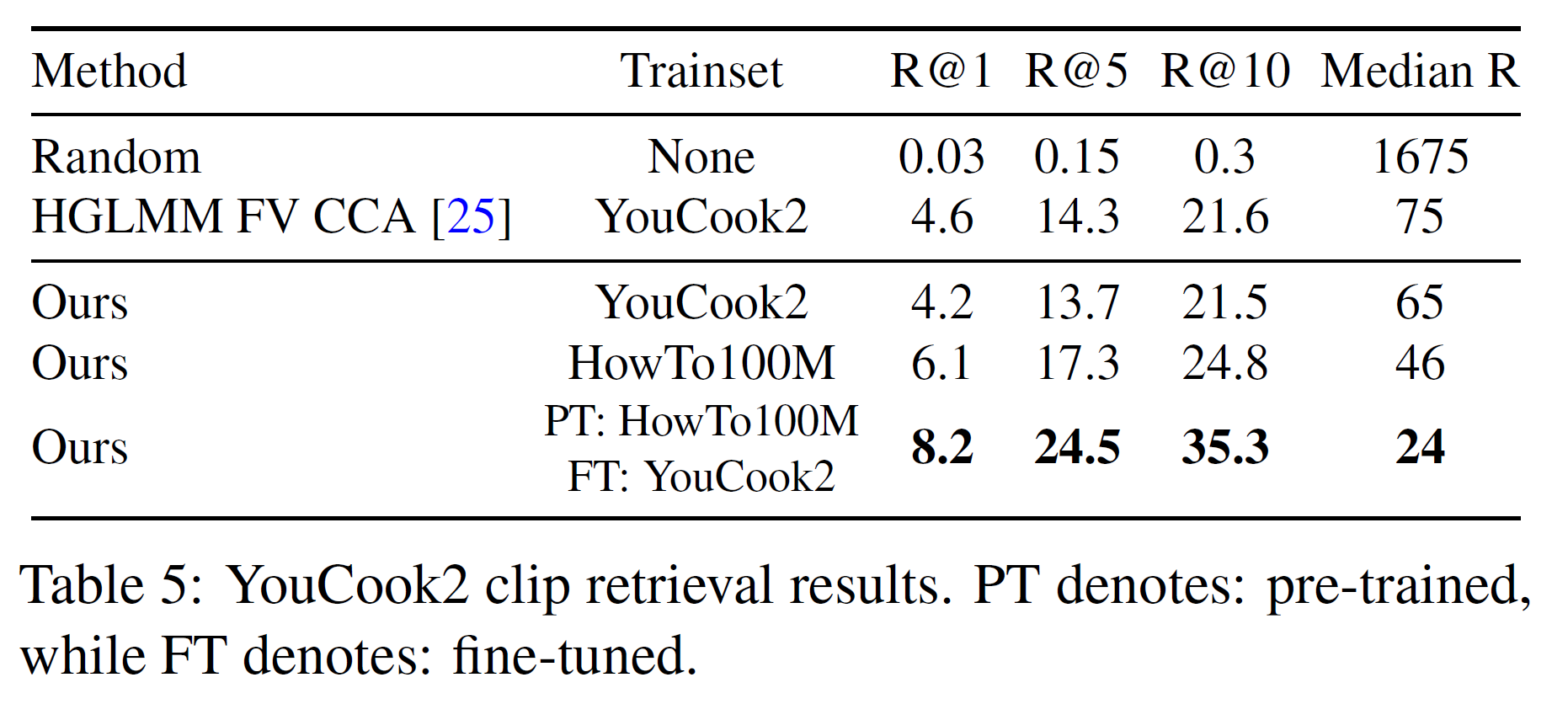
결론은 CrossTask와 비슷하게 HowTo100M 모델이 specific 모델보다 더 성능이 좋다.
MSR-VTT
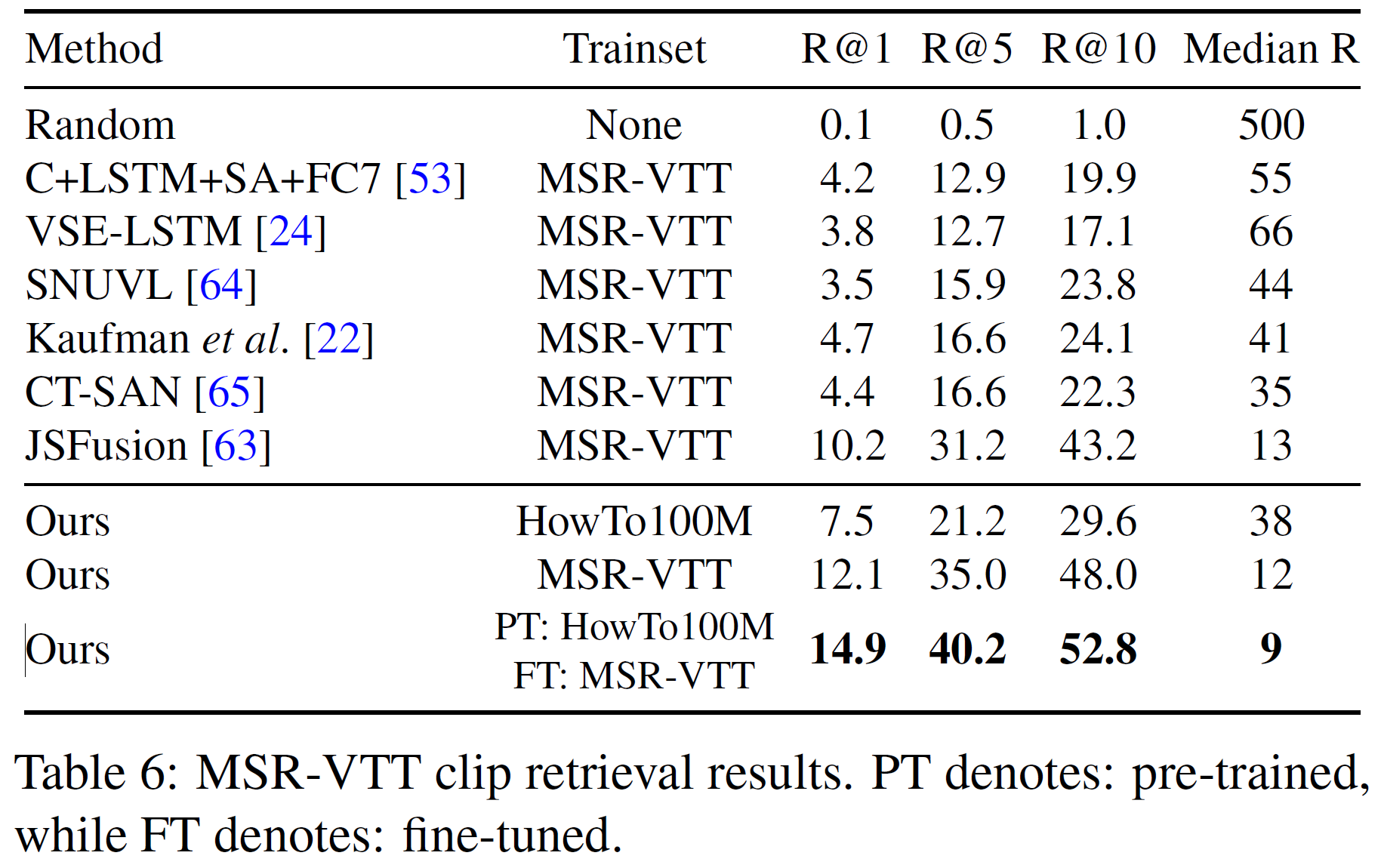
- instructional 영상 데이터셋과는 달리 MSR-VTT에서 직접 학습한 것이 HowTo100M에서 학습한 모델보다 더 좋다. 이는 일반적인 Youtube 영상이 instructional / VLOG 형식의 영상과는 상당히 다르기 때문으로 추측된다.
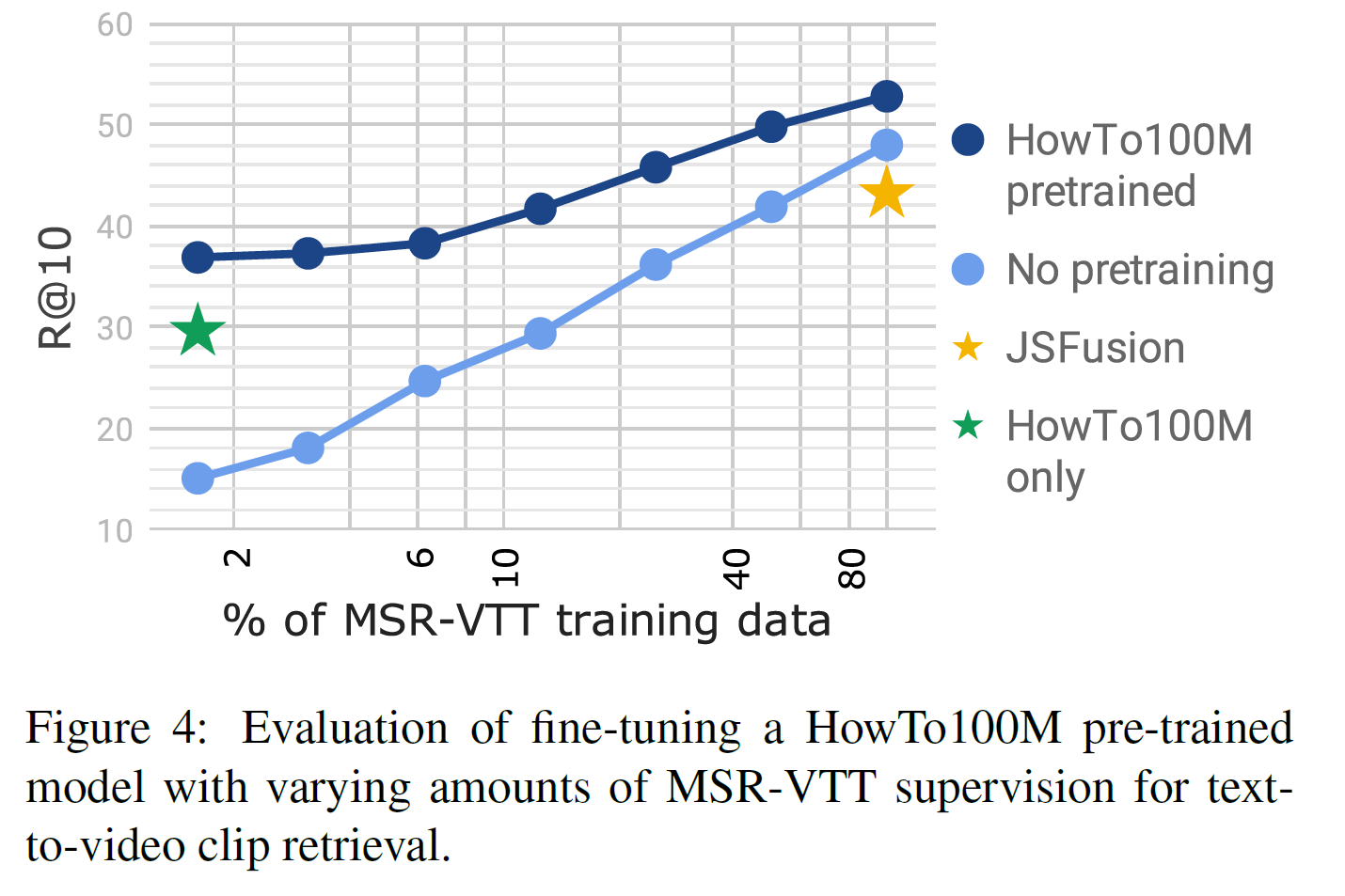
- 사전학습한 데이터의 양에 따른 성능 변화도 측정한 결과는 아래와 같다.
- SOTA 결과는 MST-VTT의 단 20%만 사용한 것과 비등한 수준이다. 이는 훨씬 더 적은 annotation을 사용해도 괜찮다는 뜻이기도 하다.
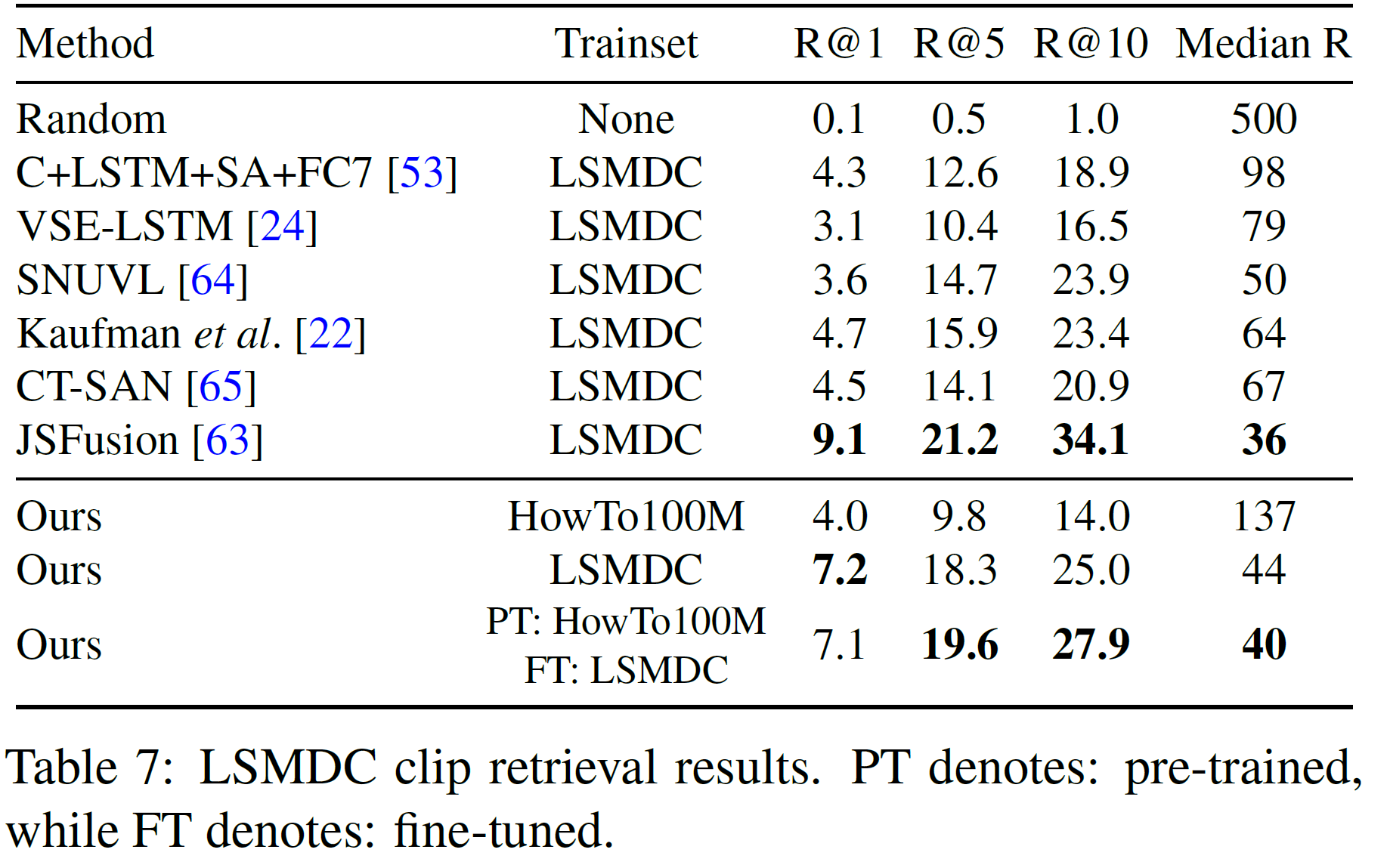
LSMDC
HowTo100M과는 상당히 다른 데이터셋이라 어려운 부분이다. 그렇지만 (논문에 실을 정도니) HowTo100M에서 사전학습 후 LSMDC에서 미세조정하는 모델은 역시 LSMDC에서 직접 학습하는 것보다 더 좋은 결과를 가져다준다.
5.6. Cross-dataset fine-tuning evaluation
HowTo100M에서 사전학습하는 것과 다른 데이터셋에서 사전학습하는 경우와 비교했다.
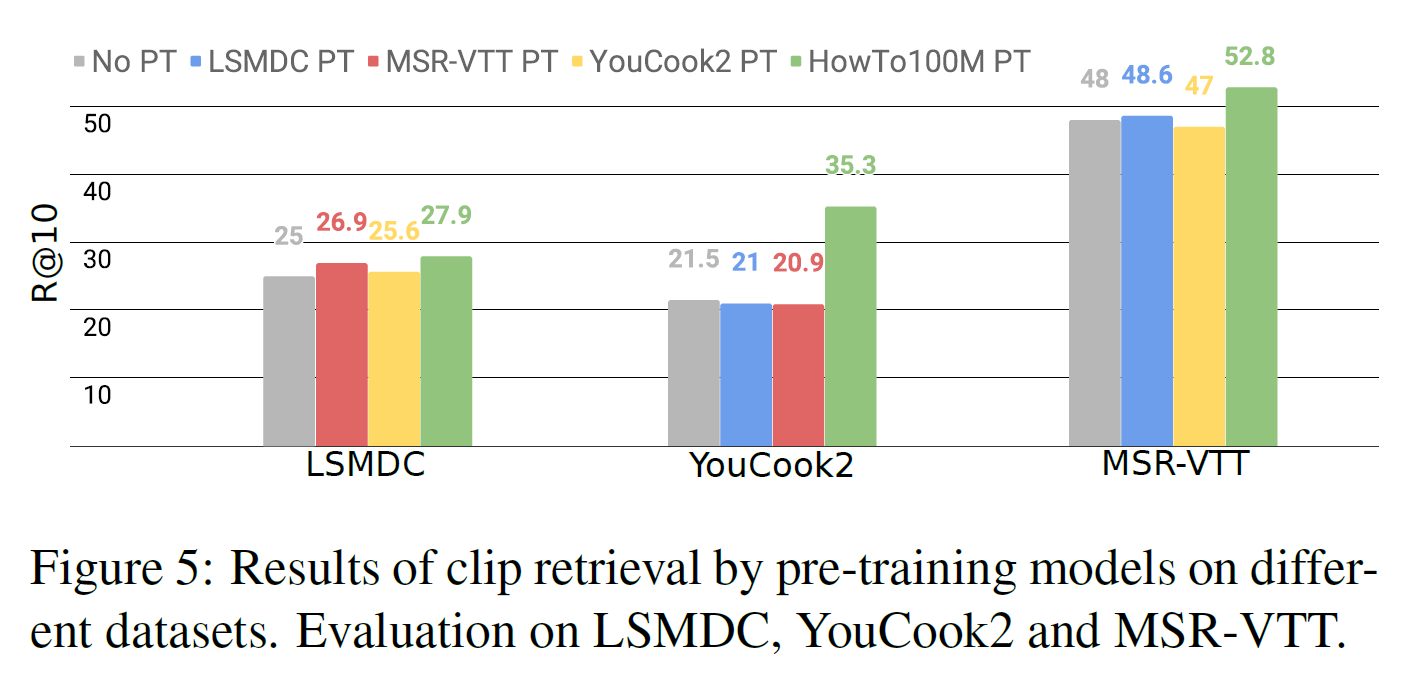
모든 경우 중 HowTo100M에서 사전학습 후 목표 데이터셋에서 미세조정하는 것이 가장 좋다.
5.7. Qualitative results
Video Retrieval의 일부 결과 예시를 가져왔다.

설명에 부합하는 영상을 잘 찾았음을 확인할 수 있다. 데모는 공식 홈페이지에서 볼 수 있다.
6. 결론(Conclusion)
1.2M개 이상의 narrated video에서 얻은 130M개 이상의 clip을 포함하는 HowTo100M 데이터셋을 제시하였다. 데이터 수집 과정은 자동화된 ASR을 사용하여 빠르고 규모를 키우기 쉬우며 수동으로 만들 필요가 없다. 이를 통해 학습한 모델은 다양한 video 관련 task에서 좋은 결과를 얻었으며 데이터, 모델 및 코드를 공개하였다.
참고문헌(References)
논문 참조!