
ViViT(Video ViT, ViViT - A Video Vision Transformer), MTN, TimeSFormer, MViT 논문 설명
10 Dec 2021 | Transformer ViT Google Research Facebook Research목차
- ViT(An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)
- Video transformer network
- ViViT: A Video Vision Transformer
- TimeSFormer: Is Space-Time Attention All You Need for Video Understanding?
- Multiscale vision transformers
이 글에서는 Transformer를 기반으로 Vision 문제를 푸는 모델인 ViViT(Video ViT: ViViT - A Video Vision Transformer), MTN, TimeSFormer, MViT 논문을 간략하게 정리한다.
ViT(An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)
논문 링크: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Github: https://github.com/google-research/vision_transformer
- 2020년 10월, ICLR 2021
- Google Research, Brain Team
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, et al.
ViT에 대한 설명은 여기를 참고하자.
Video transformer network
논문 링크: Video transformer network
VTN 논문에서는 사전학슬된 ViT 위에 tempoarl attention encoder를 추가하여 Video Action Recognition에서 좋은 성능을 내었다.
ViViT: A Video Vision Transformer
논문 링크: ViViT: A Video Vision Transformer
Github: https://github.com/google-research/scenic/tree/main/scenic/projects/vivit
- 2021년 3월, ICCV 2021
- Google Research
- Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid
위의 ViT 논문의 아이디어를 그대로 가져와 Video에 적용한 논문이다.
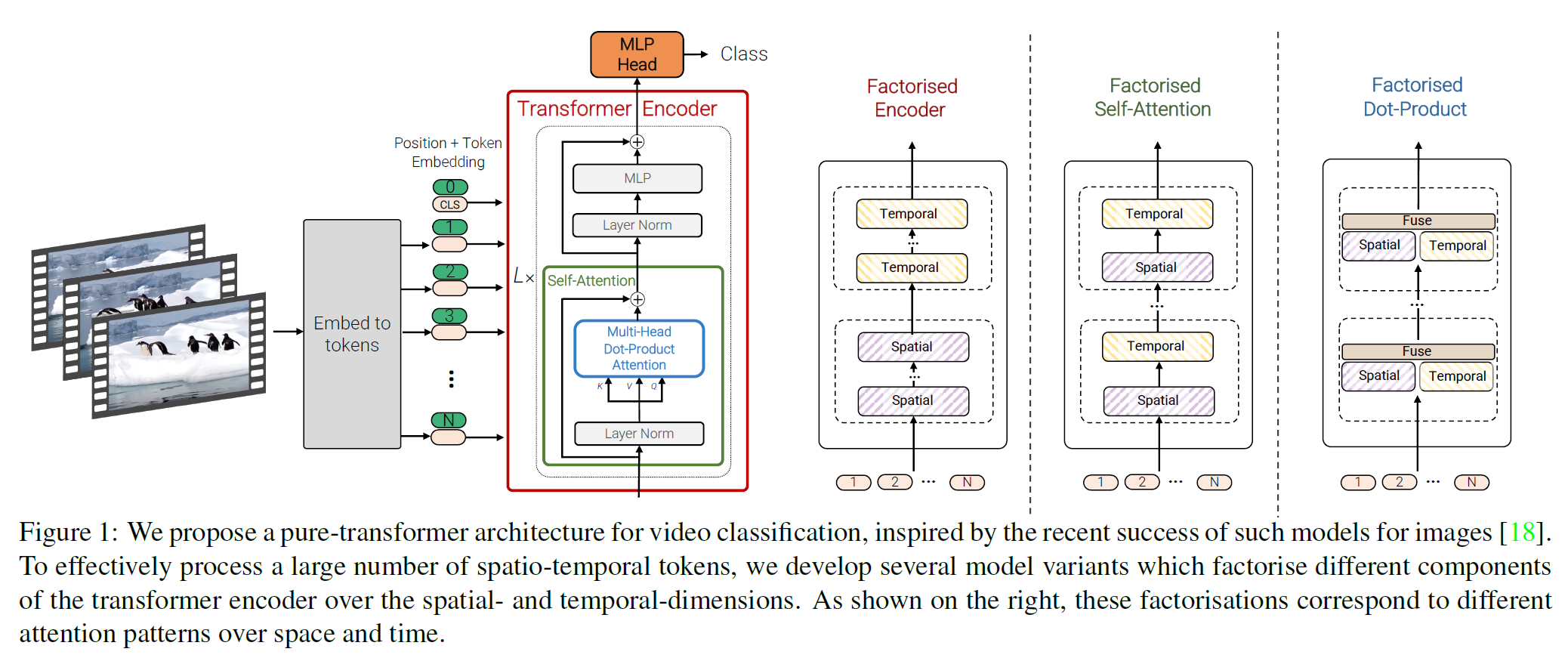
- 비디오의 각 frame을 $n_w \times n_h$ patch로 나누어 각 patch들은 Transformer Encoder에서 contextualize된다.
- $n_h$: # of rows
- $n_w$: # of columns
- $n_t$: # of frames
- 그러나 attention 계산량이 매우 많다.
- 총 patch 수가 ($n_t \times n_h \times n_w$)
- 따라서 계산은 ($n_t^2 \times n_h^2 \times n_w^2$)
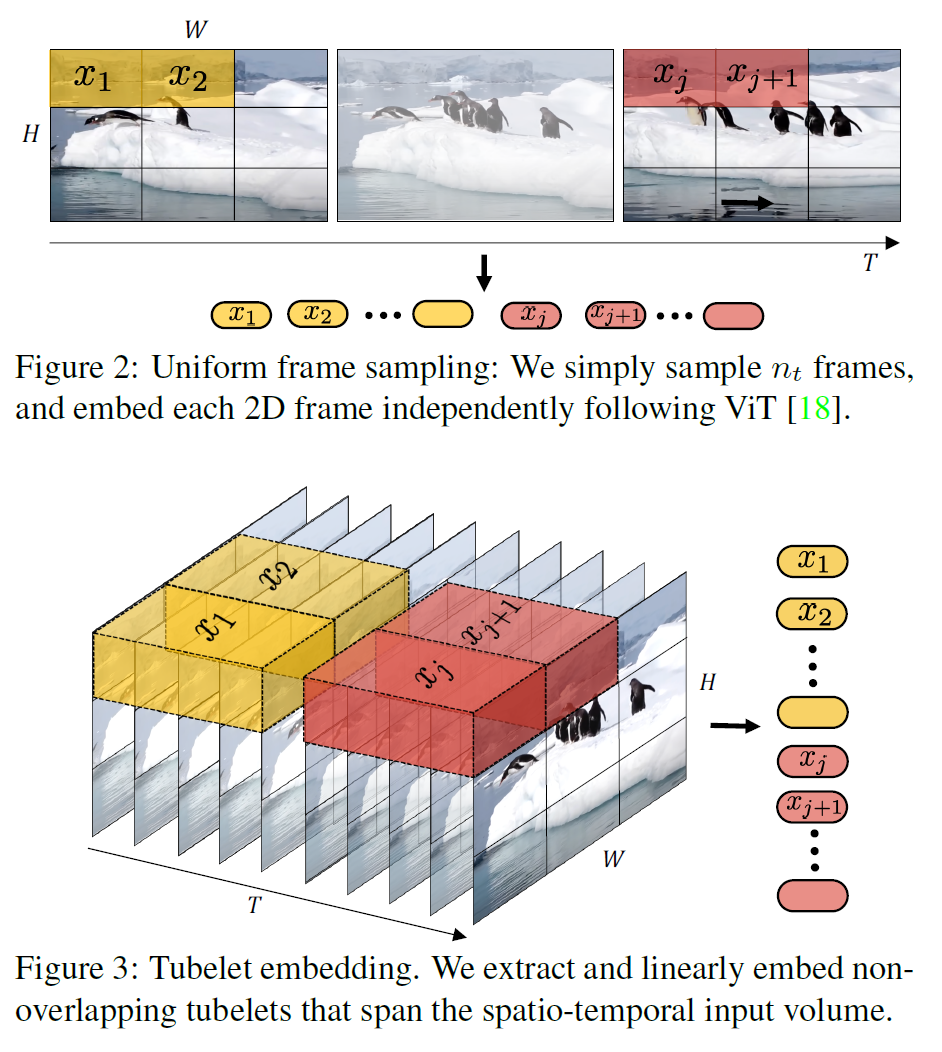
- 따라서 전체 frame 대신 일부만 균등선택하여 계산한다(uniformly frame sampling)
- 또한 Tubelet embedding을 사용한다. 토큰화 중에 미리 spatio-temporal info를 합친 다음 계산하면 계산량을 줄일 수 있다.
이 논문에서는 생각할 수 있는 여러 개의 모델을 설명한다. 하나씩 살펴보자.
Model 1: Spatio-temporal attention
사실상 brute-force 모델에 가깝다. 모든 spatio-temporal token을 forward한다.
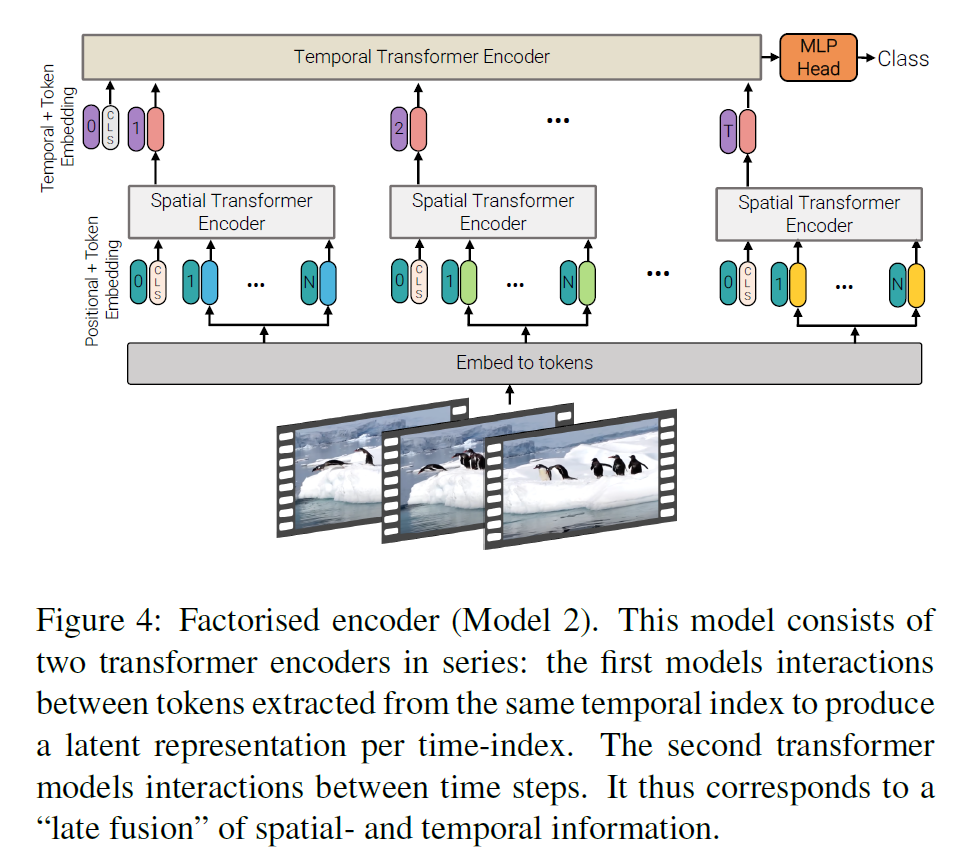
Model 2: Factorised encoder
- 모든 spatio-temporal token에 대해 계산을 진행하는 대신, 일단 spatio token에 대해서만 계산을 진행한다(by ViT).
- 각 frame을 embedding으로 바꾼 뒤 Temporal Transformer Encoder에 태운다.
- 이러면 계산량은 다음과 같다: $(n_h^2n_w^2 + n_t^2)$
Model 3: Factorised self-attention
- 모든 token 쌍에 대해 Multi-head Self-attention을 수행하는 대신, 먼저 spatial 부분에 대해 self-attention을 수행한다. 그리고 Temporally하게 self-attention을 수행한다.
- Naive model(Model 1)과 같은 수의 Transformer layer를 갖는다.
[CLS]token은 사용되지 않는다.
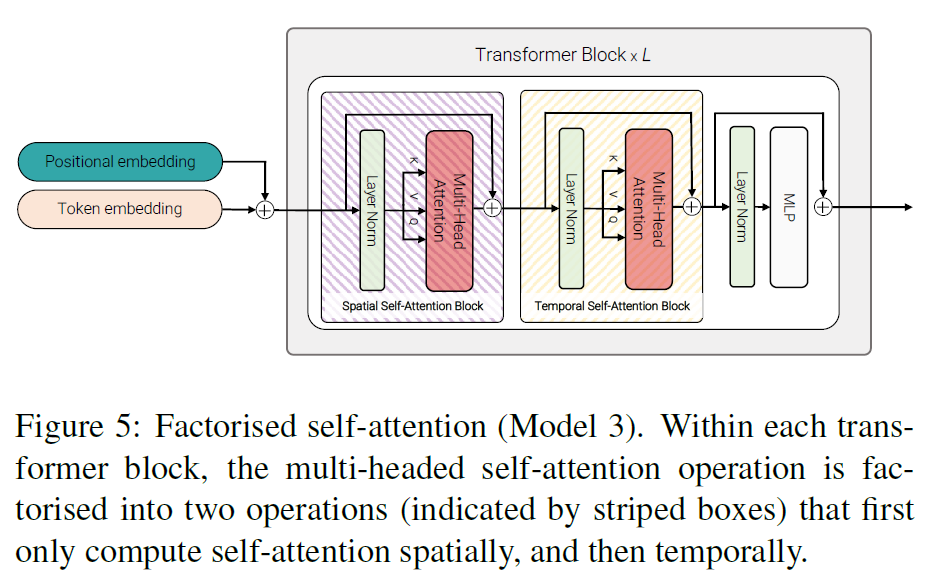
Factorisesd self-attention은 다음과 같이 정의된다.
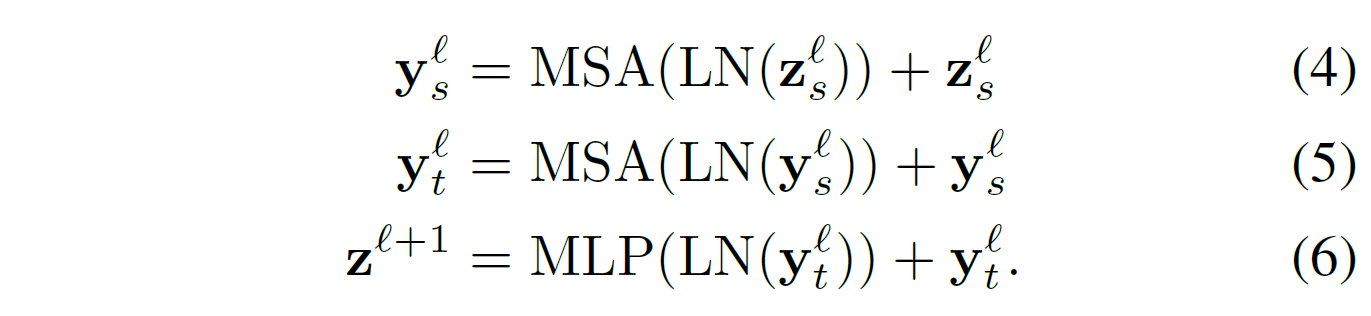
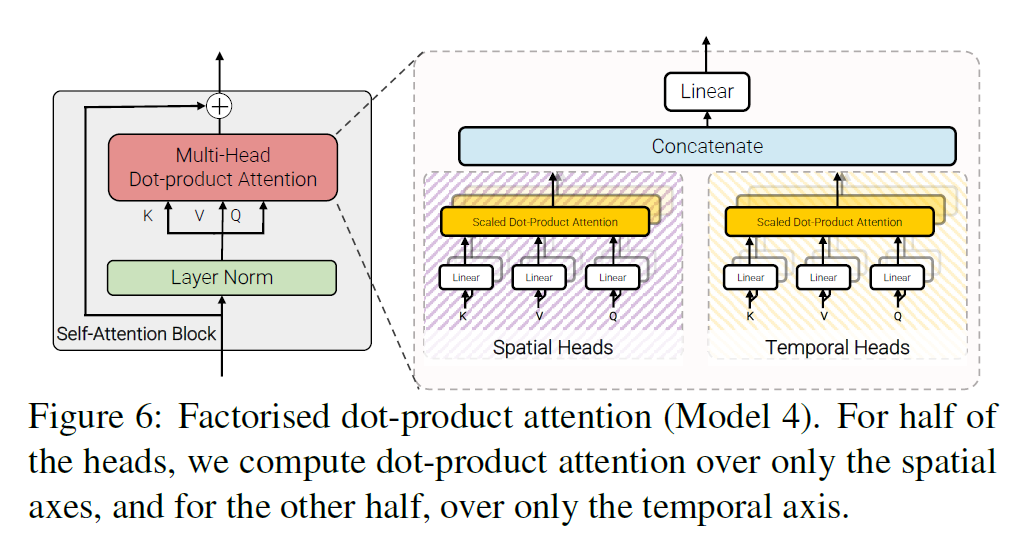
Model 4: Factorised dot-product attention
Transformer가 multi-head 연산을 포함한다는 것을 기억하자.
- 절반의 attention head는 spatial한 부분을 key, value로 다룬다. (Spatial Head)
- $\mathbf{K}_s, \mathbf{V}_s \in \mathbb{R}^{n_h \cdot n_w \times d}, \quad \mathbf{Y}_s = \text{Attention}(\mathbf{Q}, \mathbf{K}_s, \mathbf{V}_s)$
- 나머지 절반은 같은 temporal index에서 key, value를 다룬다. (Temporal Head)
- $\mathbf{K}_t, \mathbf{V}_t \in \mathbb{R}^{n_t \times d}, \quad \mathbf{Y}_t = \text{Attention}(\mathbf{Q}, \mathbf{K}_t, \mathbf{V}_t) $
위의 연산을 수행한 뒤 최종 결과는
\[\mathbf{Y} = \text{Concat}(\mathbf{Y}_s, \mathbf{Y}_t)\mathbf{W}_O\]이 된다.
Experiments
ViT가 매우 큰 데이터셋에서만 좋은 결과를 얻을 수 있었기 때문에, ViT를 initialization으로 사용하였다.
위의 모델들을 실험한 결과는 다음과 같다. 또한, Temporal Transformer의 layer 수에 따라서도 Top-1 Accuracy를 측정한 결과도 있다.
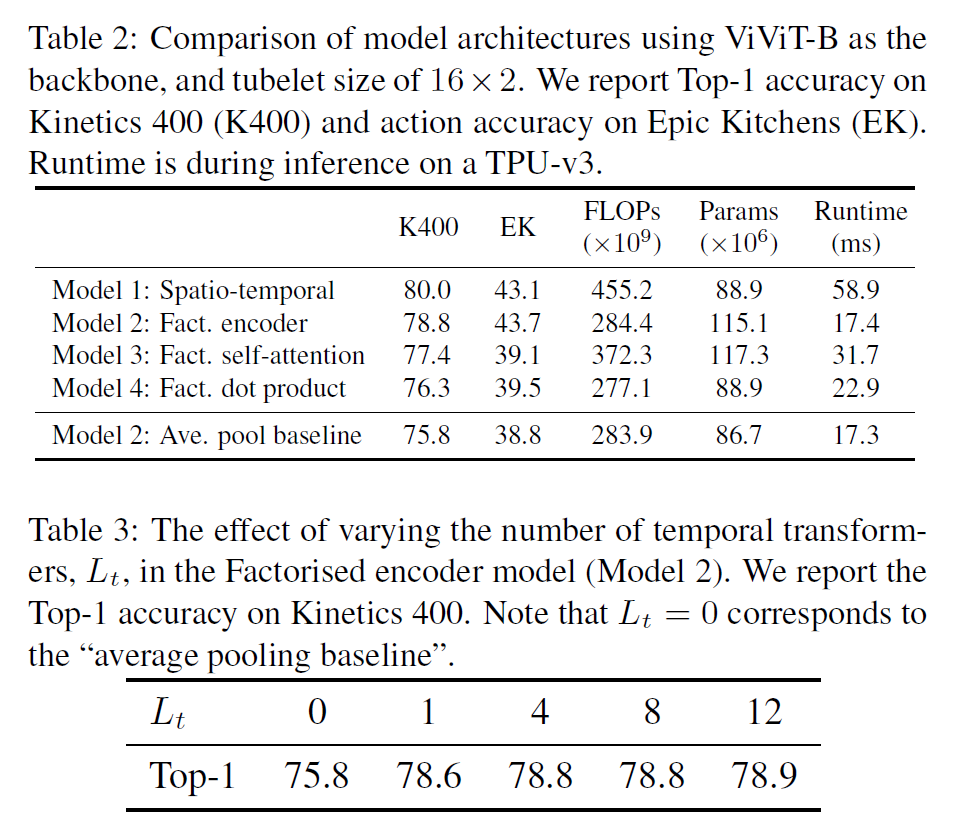
결과가 약간 의외(?)인데, Model 1이 가장 연산이 비싸지만 성능은 제일 좋다. Model 2는 성능이 살짝 낮지만 연산량 대비해서는 꽤 효율적이라 할 수 있다.
TimeSFormer: Is Space-Time Attention All You Need for Video Understanding?
논문 링크: Is Space-Time Attention All You Need for Video Understanding?
Github: https://github.com/facebookresearch/TimeSformer
- 2021년 6월, ICMl 2021
- Facebook Research
- Gedas Bertasius, Heng Wang, Lorenzo Torresani
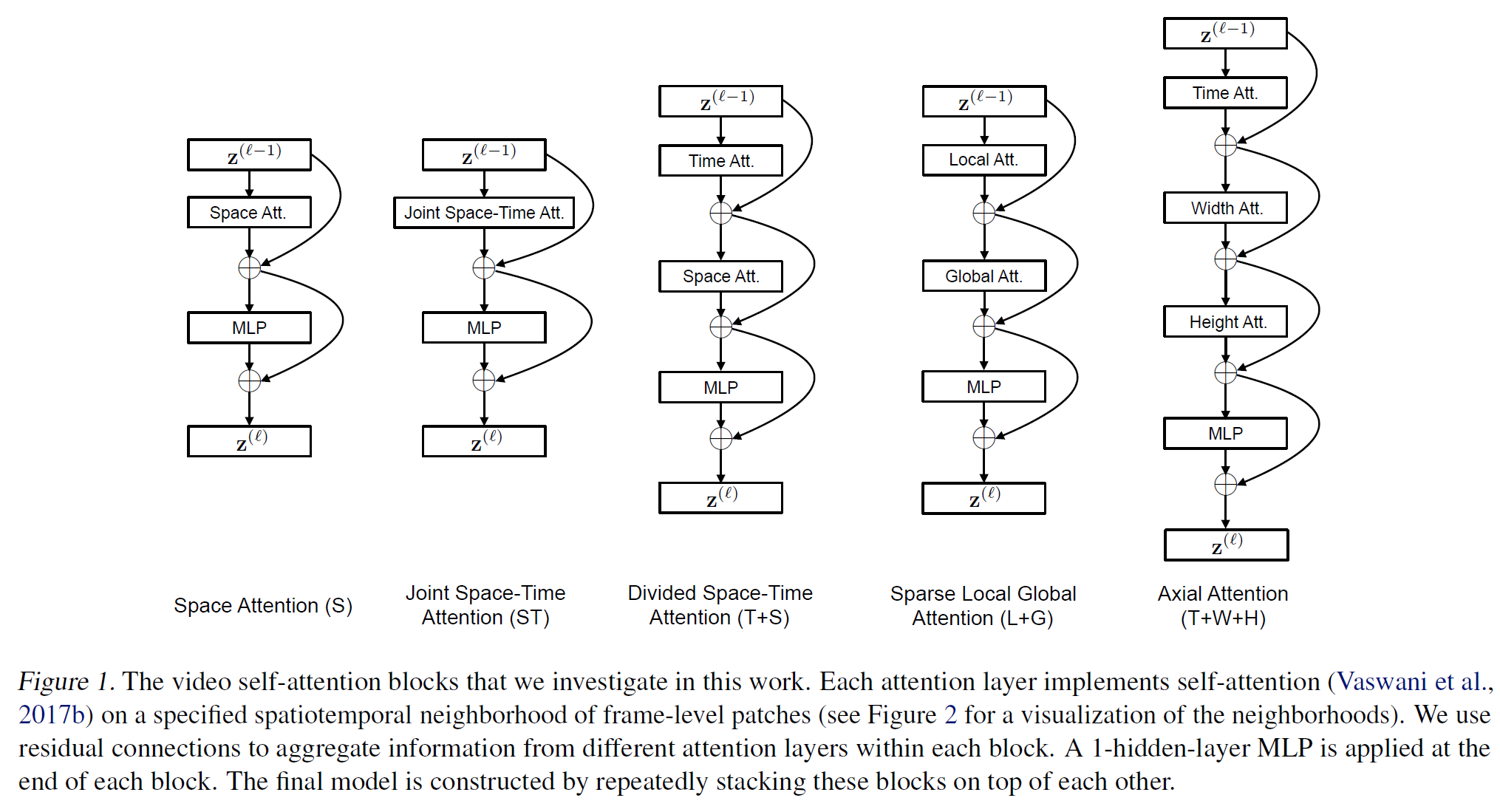
Facebook에서 만든 논문인데 위의 ViViT와 거의 비슷하다. ViT를 Video에 적용시킨 논문이다.

Multiscale vision transformers
논문 링크: Multiscale vision transformers
MViT는 scratch로부터 학습된 video recognition 모델로 spatio-temporal 모델링을 위해 pooling attention을 취함으로써 계산량을 줄이고 SSv2에서 SOTA를 찍었다.
위의 Transformer 기반 Video 모델들은 global self-attention 모듈에 기초한다. 이렇게 하는 대신 Swin Transformer를 기반으로 문제를 해결하는 논문이 최근 올라와 있다.