
Swin Transformer - Hierarchical Vision Transformer using Shifted Windows 논문 설명
14 Dec 2021 | Transformer Swin Transformer Microsoft Research목차
이 글에서는 Microsoft Research Asia에서 발표한 Swin Transformer 논문을 간략하게 정리한다.
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
논문 링크: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Github: https://github.com/microsoft/Swin-Transformer
- 2021년 3월(Arxiv), ICCV 2021 best paper
- Microsoft Research Asia
- Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo
Computer Vision 분야에서 general-backbone으로 사용될 수 있는 새로운 Vision Transformer인 Shifted WINdow Transformer이다.
Abstract
Transformer는 원래 자연어를 처리하기 위한 것인데 이를 Vision 분야로 가져왔다. 이 과정에서 어려운 점은 이미지의 경우 visual entity의 크기(scale)와 해상도가 매우 다양하다는 문제가 있다는 것이다. 이를 위해 제안한 hierarchical Shifted WINdow 방식은, 기존 self-attention의 제곱에 비례하는 계산량을 선형 비례하게 줄이면서도 다양한 scale을 처리할 수 있는 접근법이다. 이로써 image classification, object detection, semantic segmentation 등 다양한 범위의 vision task에서 훌륭한 성과를 보였다.
1. Introduction
이미지 관련 분야는 CNN을 통해, NLP 관련 분야는 Transformer를 통해 발전해왔다. 이 논문에서는 Transformer를 vision 분야에 효율적으로 적용하는 방법을 연구한다(사실 이러한 시도 자체는 ViT에서 있었다). 기존의 Transformer와 ViT는 고정된 크기의 token만을 사용하기 때문에 고해상도, 다양한 크기의 entity를 갖는 이미지 분야에서는 적합하지 않다.
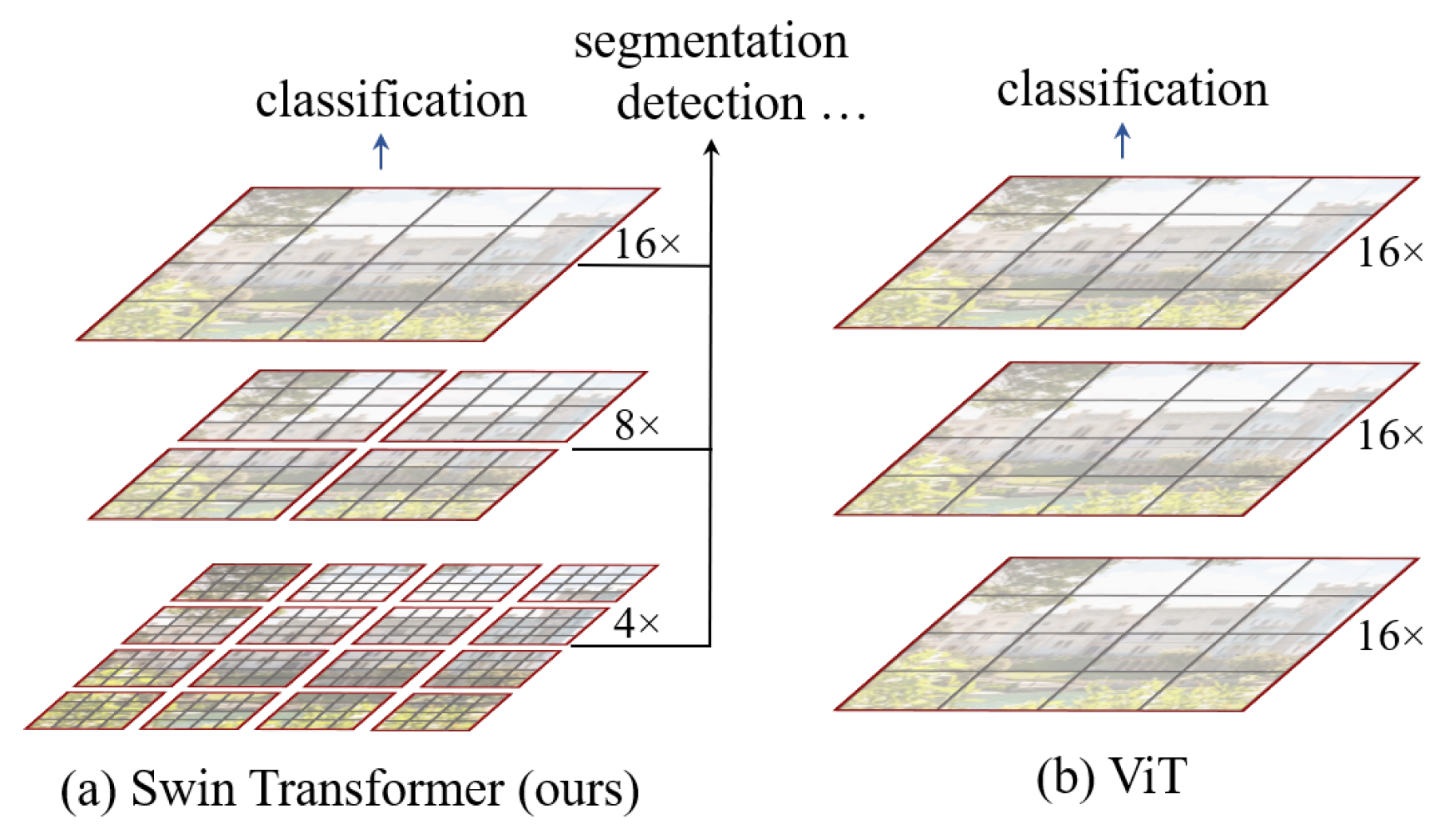
따라서 이 논문에서는 Shifted WINdow 기법을 사용하는 Swin-Transformer를 제안한다. 위 그림 1과 갈이, 이는
- 작은 크기의 patch 안에서만 self-attention을 수행하고
- layer를 통과하면서 인접한 patch들을 점점 합치면서 계산한다.
이러한 구조 덕분에 FPN이나 U-Net처럼 계층적인 정보를 활용한 여러 테크닉도 사용할 수 있다. 가장 작은 window 안의 patch 수는 고정되어 있기 때문에 이미지 크기에 선형 비례하는 계산량만 필요로 한다. 이러한 이점 덕에 여러 vision task에서 backbone net으로 사용할 수 있다.
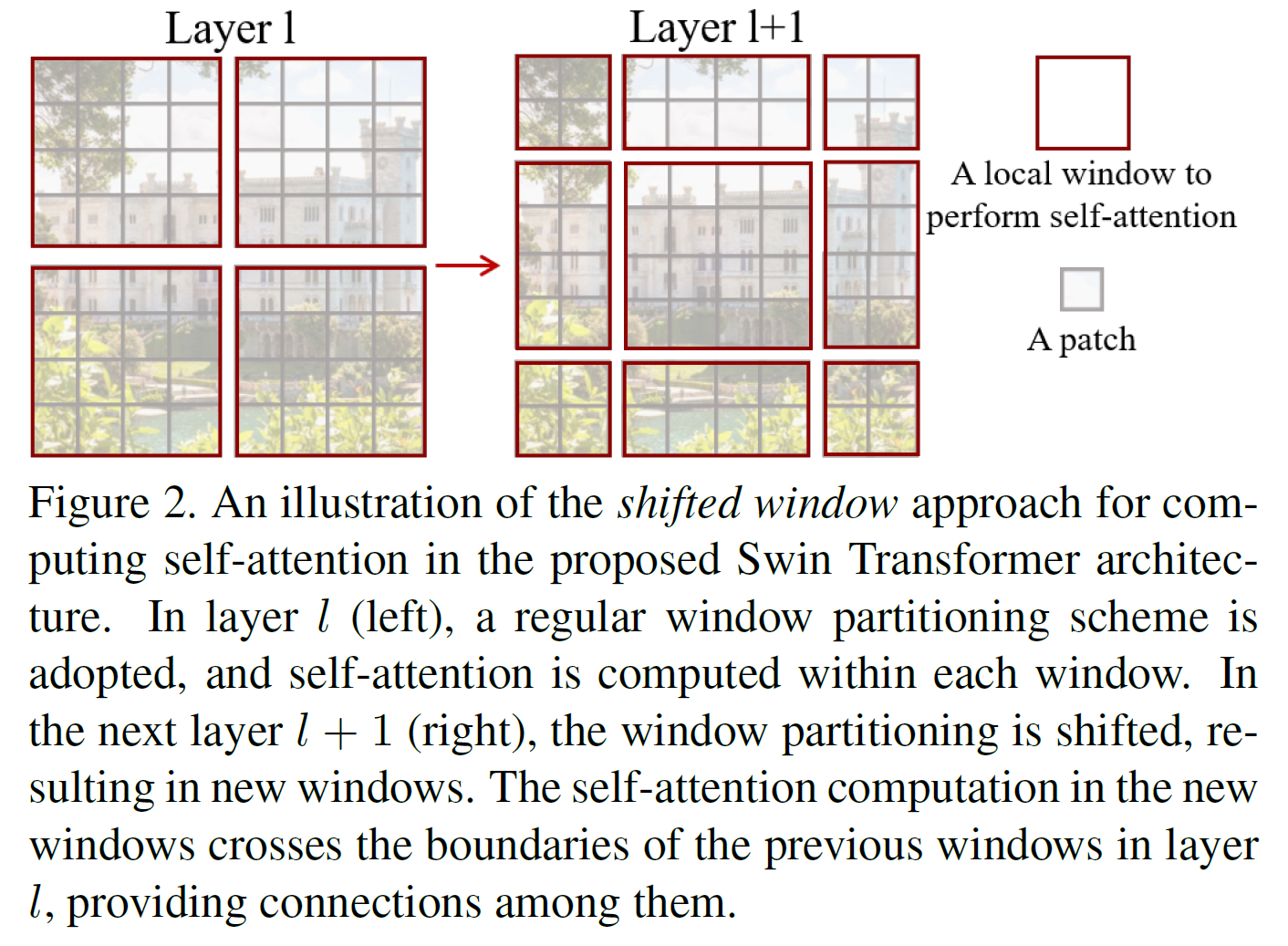
또 하나의 핵심 구조는 다음과 같다. 위와 같이 window를 나누어서 계산을 수행하면 각 window의 경계 근처 pixel들은 인접해 있음에도 self-attention 계산이 수행되지 않는데, 이를 위해 window 크기의 절반만큼 shift하여 비슷한 계산을 수행한다.
여기서 이러한 shifted window 방식은 기존의 sliding window 방식에 비해 더 효율적이다, 그 이유는
- self-attention 계산을 수행할 때, sliding window 방식에서는 각각 다른 query pixel에 대해 다른 key sets에 대해 계산을 수행해야 해서 일반적인 하드웨어에서 low latency 문제를 경험하게 된다.
- 이와 달리 shifted window 방식은 window 내의 모든 query patch는 같은 key set을 공유하기 때문에 하드웨어 상에서 memory access 면에서 latency가 더 적기 때문이다.
결과적으로, Swin Transformer는 Image Classification, Object Detection, Semantic Segmentation에서 ViT, DeiT, RexNe(X)t를 능가하였다.
2. Related Work
CNN and variants: CNN, VGG, GoogleNet, ResNet, DenseNet, HRNet, EfficientNet 등 여러 논문이 수 년에 걸쳐서 빠르게 발전해왔다. 위의 논문들에 대해서는 여기를 참고하자.
Self-attention based backbone architectures: ResNet 기반 conv layer를 self-attention layer로 대체하는 시도가 있었으나 sliding window 방식으로 인핸 memory access 문제가 있었다. 전술했듯이 이 논문에서는 shifted window 방식을 사용하여 이를 해결했다.
Self-attention/Transformers to complement CNNs: CNN을 self-attention이나 Transformer로 보강하는 연구도 있었다. 최근에는 Transformer를 object detection이나 segmentation에 사용하기도 하였다.
Transformer based vision backbones: 말 그대로 Transformer를 vision 분야에다 적용시켜 backbone으로도 사용할 수 있는 건데 ViT와 DeiT 및 그 후속 논문들이 대표적이다.
3. Method
3.1. Overall Architecture
Swin Transformer는 4가지 버전이 있는데(Tiny, Small, Base, Large) 아래는 T 버전의 전체 구조이다.
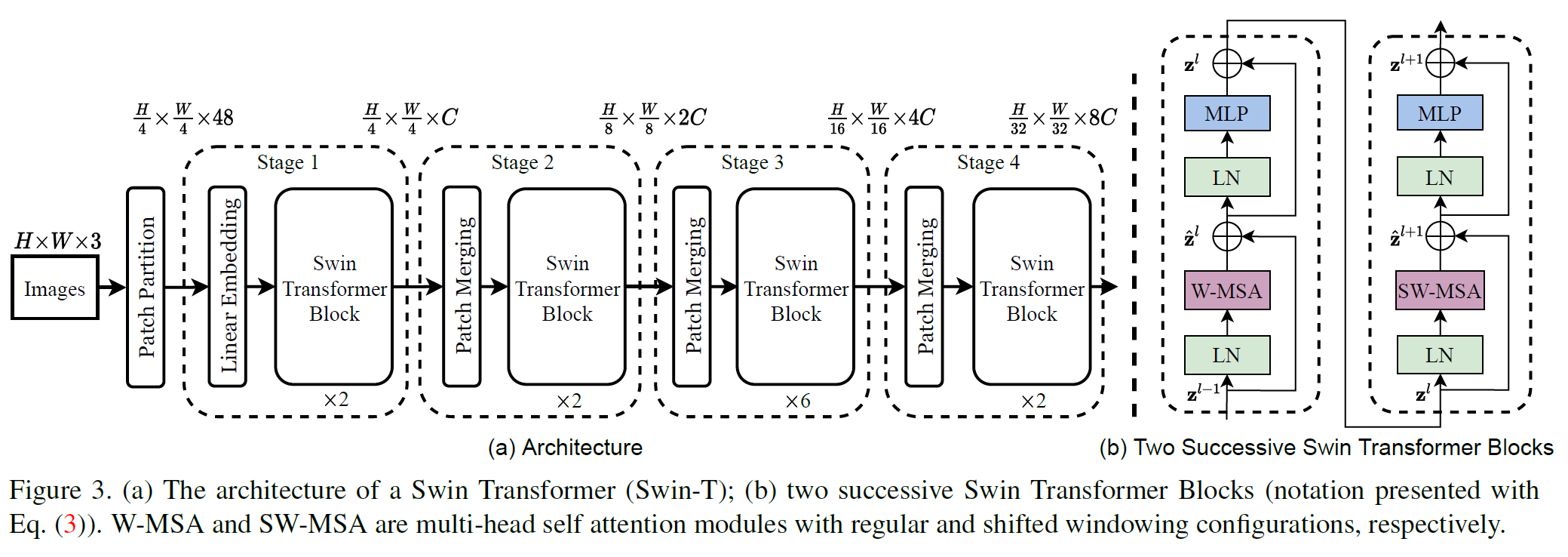
- 맨 앞에 Patch partition 과정이 있다. 여기서는 먼저 ViT와 같은 patch 분리 모듈을 통해 입력 RGB 이미지를 겹치지 않는 patch들로 나눈다.
- 각 patch는 하나의 “token”과 같으며 그 feature는 raw pixel RGB 값을 이어붙인 것이다.
- 이 논문에서는 각 patch의 크기는 $4 \times 4$이며, 따라서 feature는 $4 \times 4 \times 3 = 48$이 된다.
- Stage 1:
- 이후 Linear Layer를 통해 $H/4 \times W/4 \times 48$ 텐서를 $H/4 \times W/4 \times C$ 텐서로 변환한다. 생긴 걸 보면 $1 \times 1$ conv 같지만 Linear Layer가 맞다.
- Swin Transformer Block이 이제 등장한다. 얘는 위 그림의 (b)에서 볼 수 있는데, 일반적인 MSA(Multi-head Self Attention) 대신 W-MSA(Window MSA)와 SW-MSA(Shifted Window MSA)라는 것을 사용한다. 이건 다음 섹션에서 설명한다. Activation function으로는 GELU를 사용한다.
- Stage 2~4에서는 Patch Merging이 있다.
- 이건 맨 처음 $4 \times 4$ 크기의 작은 patch들을 점점 합쳐가면서 더 넓은 부분을 한번에 보려는 과정이다.
- 먼저 인접한 $2 \times 2$개의 patch를 concat한다. 그러면 채널 수가 4배로 된다.
- 이를 linear layer를 써서 2C로 맞춘다. 따라서 Patch Merging을 통과하면 해상도는 $2 \times 2$배 줄고 채널은 2배로 늘어난다.
- 이렇게 hierarchical한 구조로 각 단계마다 representation을 갖기 때문에 다양한 scale의 entity를 다루어야 하는 image 분야에서 괜찮은 성능을 낼 수 있는 것이다. 어떻게 보면 생긴 게 VGGNet이나 ResNet과 비슷하므로, 여러 vision task에서 이 Swin Transformer를 backbone으로 사용할 수 있다.
- 참고로, (b)는 거의 비슷한 Swin Transformer를 2개 붙여 놓은 것이기 때문에, (a) 부분에서 $\times2$, $\times6$이라 되어 있는 부분은 각각 (b)를 1번, 3번 붙여 놓은 것이다.
3.2. Shifted Window based SelfAttention
위에서도 말했듯이 기존 Self-Attention은 모든 부분의 쌍에 대해 연산해야 하므로 계산량이 제곱에 비례한다. 이를 해결하고자 한다.
Self-attention in non-overlapped windows
사실 같은 내용이다.
- 가장 작은 patch는 $4 \times 4$ pixel로 구성되어 있다.
- Window는 $M \times M$개의 patch로 구성된다. 이 논문에서는 $M=7$로 고정이다.
- 이미지는 이 Window가 $h \times w$개 있다. 이미지의 해상도는 $4Mh \times 4Mw$임을 알 수 있다.
즉 이미지 해상도가 $224 \times 224$라면, 첫번째 layer에서 patch의 크기는 $4 \times 4$이고, 이 patch를 $7 \times 7$개 모은 Window가 $h \times w = 8 \times 8$개가 존재한다.
이렇게 하면 그냥 MSA에 비해 많이 줄어든다.
- $\Omega(\text{MSA})$ : $4hwC^2 + 2(hw)^2C$
- $\Omega(\text{W-MSA})$ : $4hwC^2 + 2M^2hwC$
$M=7$으로 고정이므로 이미지 크기에 선형으로 비례한다.
Shifted window partitioning in successive blocks
위의 Window 방식이 좋기는 한데, Window 경계에 있는 patch들은 서로 인접해 있음에도 attention 계산을 수행할 수 없게 된다. 이를 위해 Window를 $\lfloor M/2 \rfloor$만큼 cyclic하게 shift한 다음에 비슷한 계산을 수행한다.
즉, Swin Transformer block은 다음과 같은 과정을 따른다. Layer Norm은 생략하고 설명하면(그림 3b와 같은 부분이다),
- 이전 layer의 입력이 들어오면
- W-MSA를 수행한다.
- MLP에 통과시킨다.
- SW-MSA를 수행한다: 이는 Cyclic Shift를 시키고 W-MSA 계산을 수행하는 것과 거의 같다. 그 다음엔 Cyclic shift 했던 것을 다시 되돌린다(Reverse cyclic shift).
- MLP에 통과시킨다.
- 그러면 이제 Swin Transformer block의 output이 나온다. 이는 다음 layer로 전달될 것이다.
물론, residual connection도 있는데 이는 그림을 보면 쉽게 이해할 수 있다.

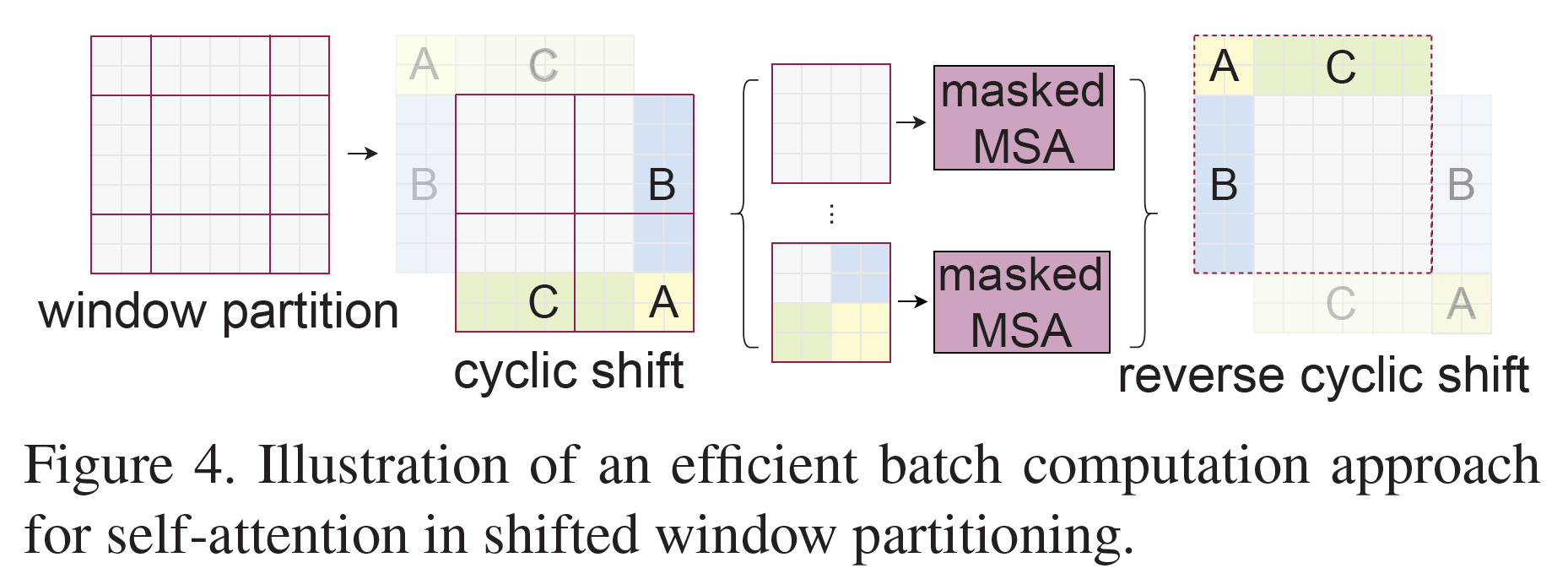
Efficient batch computation for shifted configuration
Window를 shift하고 나면 우측과 하단 경계에 있는 Window들은 $M \times M$보다 크기가 작아진다.
SW-MSA 과정에서 Cyclic shift를 하면 전체 이미지의 반대쪽 경계에 있던 부분(A, B, C로 표시)끼리 연산을 하게 되는 것을 막기 위해 해당 부분을 mask 처리한다.
참고: zero padding으로도 할 수는 있는데 연산량이 증가하므로 이 논문에서는 쓰지 않았다.
Relative position bias
기존 Transformer에서는 Sinusodal 함수를 사용해서 positional encoding을 추가했었다.
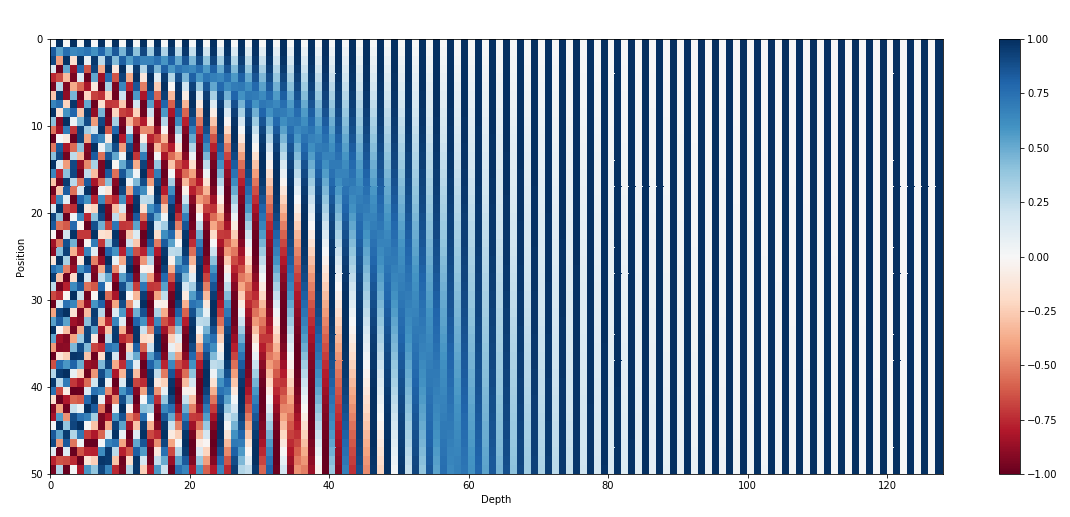
이것보다는 상대좌표의 차이를 넣어주는 것이 성능 상으로 더 좋다고 한다. 그리고 아래 식과 같이 더해주는 부분도 Attention 연산 중으로 옮겨온 것을 알 수 있다.
\[\text{Attention}(Q, K, V) = \text{SoftMax}(QK^T / \sqrt{d} + B)V\]$B \in \mathbb{R}^{(2M-1) \times (2M-1)}$가 relative position bias이다.
3.3. Architecture Variants
Swin Transformer도 ViT, DeiT와 비슷하게 Base model이 있다. Tiny는 4배 작고, Small은 절반, L은 2배 크다.
- Swin-T: $C = 96$, layer numbers = {2, 2, 6, 2}. ResNet-50(DeiT-S)와 크기가 비슷하다.
- Swin-S: $C = 96$, layer numbers = {2, 2, 18, 2}. ResNet-101과 크기가 비슷하다.
- Swin-B: $C = 128$, layer numbers = {2, 2, 18, 2}
- Swin-L: $C = 192$, layer numbers = {2, 2, 18, 2}
$C$는 채널 수이고, layer 수는 그림 3에서 Swin Transformer Block이 $\times 2, \times 6$만큼 있있던 것을 생각하면 된다.
4. Experiments
- Image Classification으로는 ImageNet
- Object Detection으로는 COCO
- Sementic Segmentation으로는 ADE20K
데이터셋을 사용하였다.
4.1. Image Classification on ImageNet1K
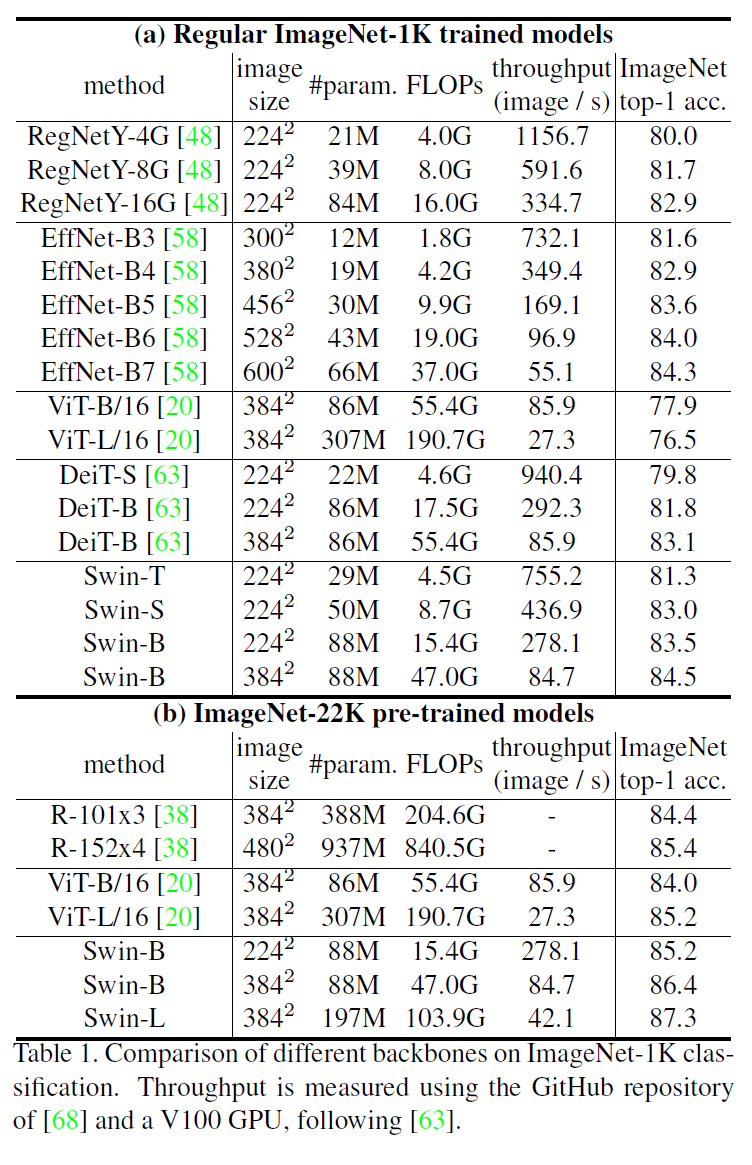
Regular ImageNet-1K으로 학습한 model들의 비교가 (a)이다. Swin-B는 RegNet이나 DeiT에 비해서는 확실히 모델 크기과 계산량 대비 성능이 좋다. EfficientNet과는 비등한 수준이다.
ImageNet-22K로 학습한 모델끼리 비교한 결과는 (b)인데 Swin이 크기와 계산량 대비 확실히 더 성능이 좋다.
4.2. Object Detection on COCO
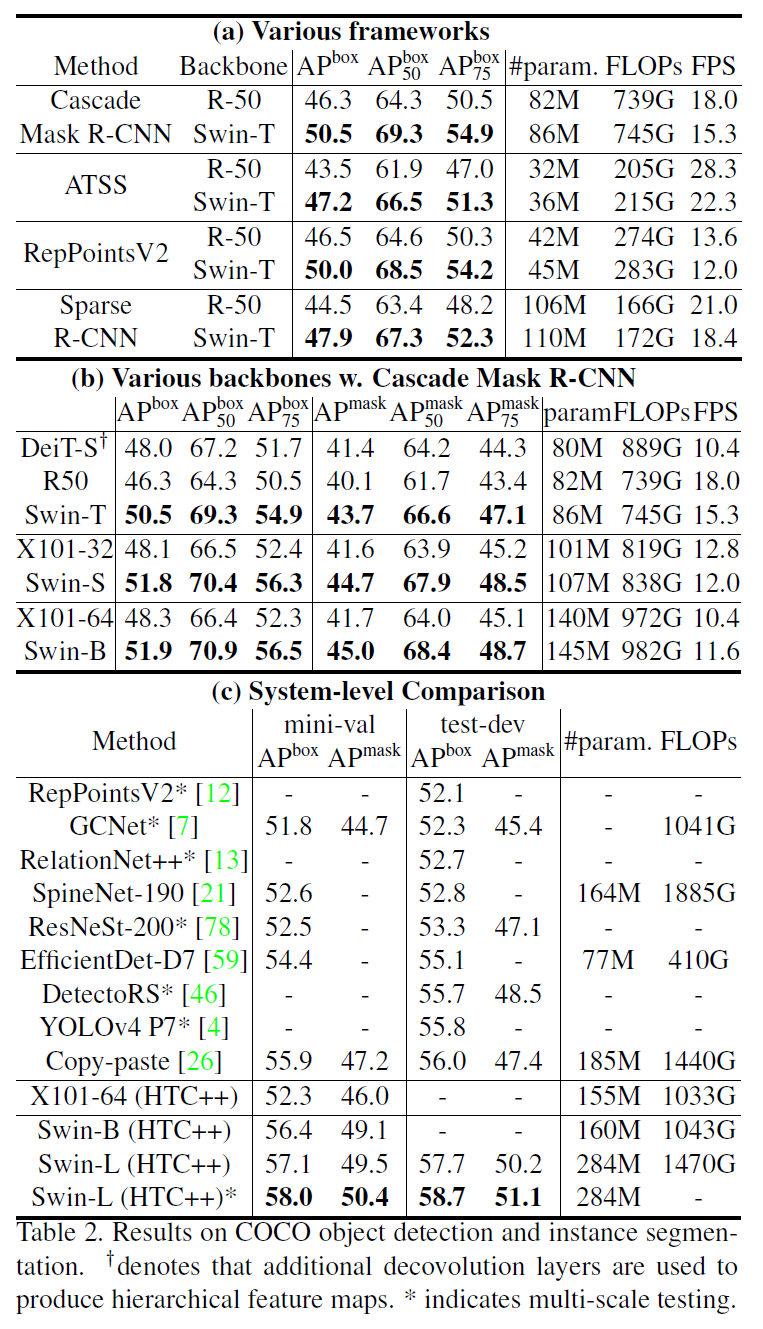
계산량 대비 성능이 Image Classification 때보다 더 크게 앞선다.
4.3. Semantic Segmentation on ADE20K
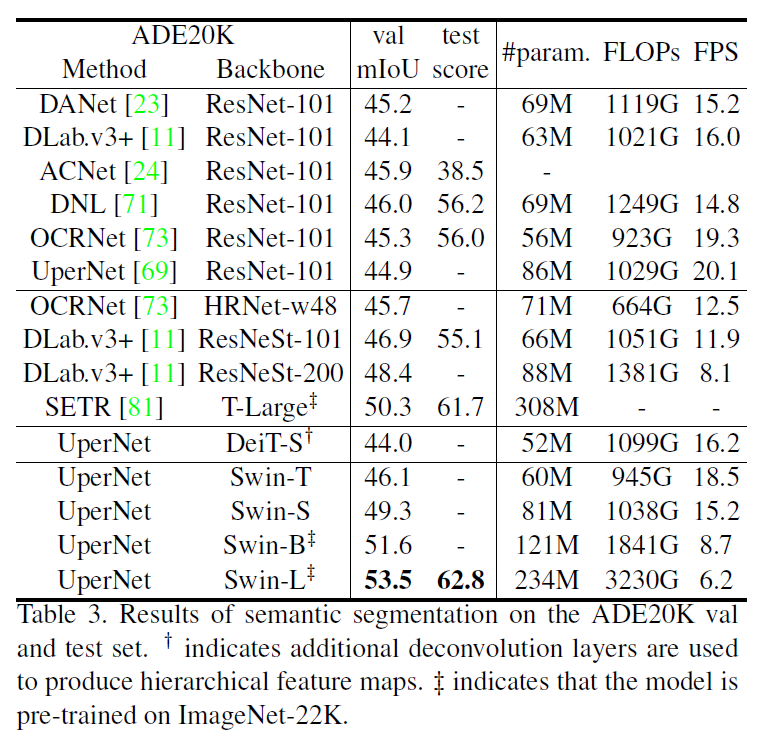
다른 Task(Object Detection, Semantic Segmentation)의 backbone으로 사용했을 때의 성능은 거의 state-of-the-art이다.
4.4. Ablation Study
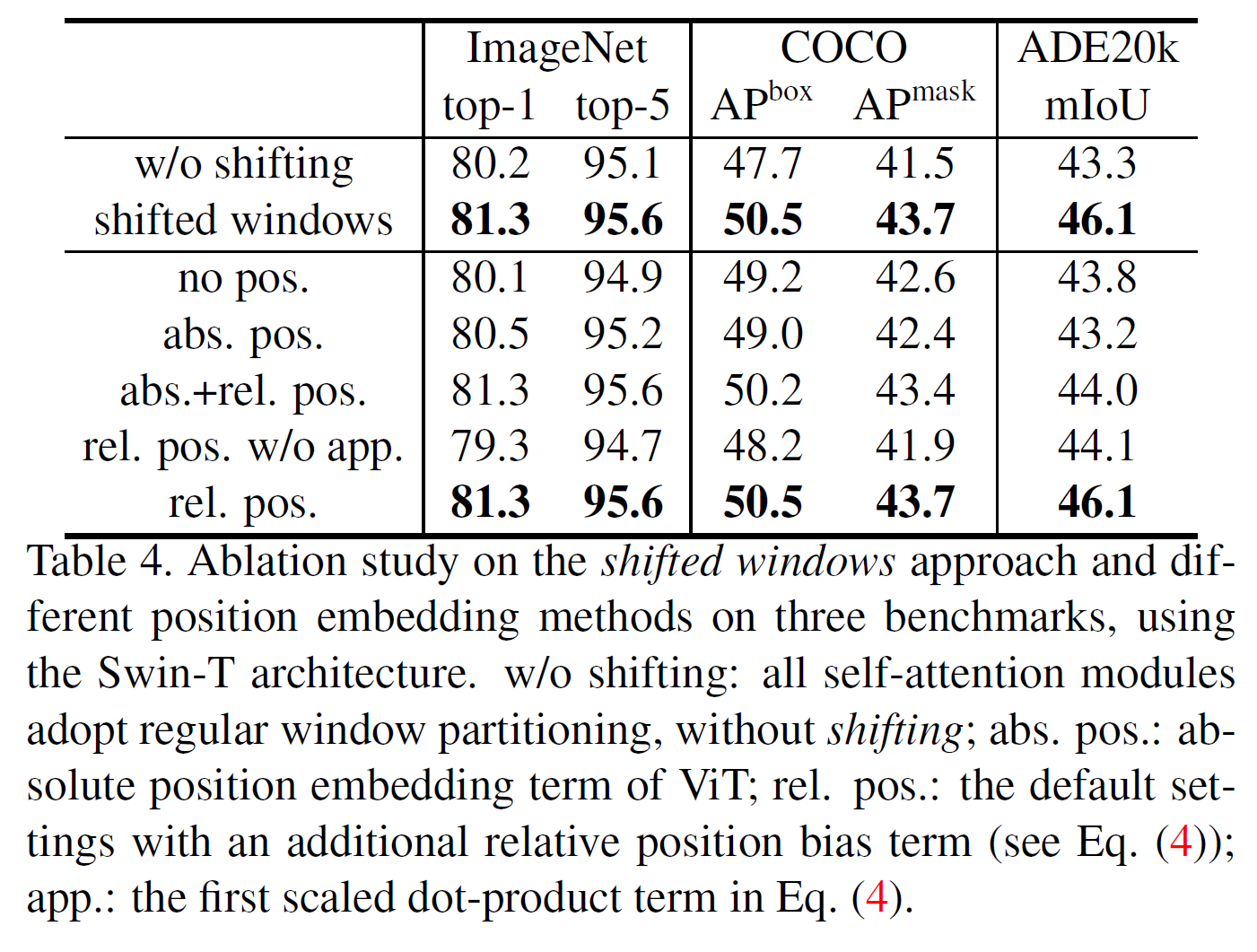
- Shifted windows 기법을 사용한 경우에 모든 task에서 성능이 더 높게 나온다.
- Relative position bias의 효과를 분석하였는데, absolut position을 단독으로 쓰거나 같이 쓰는 것보다 relative position bias만 쓰는 것이 제일 좋다고 한다.
V100 GPU로 계산하면 이 정도의 시간이 걸린다. 꽤 빠르다고 알려진 Performer architecture보다 살짝 더 빠르다.
5. Conclusion
- Swin Transformer는 기존 Transformer 대비 계산량을 줄이면서도 다양한 scale의 이미지를 처리할 수 있다.
- Image Classification, Object Detection, Semantic Segmentation 등 여러 Vision task의 backbone으로 쓸 수 있다.
- Shifted Window 방식은 충분히 효율적이다.