
Video Swin Transformer 논문 설명
18 Dec 2021 | Transformer Swin Transformer Microsoft Research목차
이 글에서는 Microsoft Research Asia에서 발표한 Video Swin Transformer 논문을 간략하게 정리한다.
Video Swin Transformer
논문 링크: Video Swin Transformer
Github: https://github.com/SwinTransformer/Video-Swin-Transformer
- 2021년 6월(Arxiv)
- Microsoft Research Asia, University of Science and Technology of China, Huazhong University of Science and Technology, Tsinghua University
- Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, Han Hu
Computer Vision 분야에서 general-backbone으로 사용될 수 있는 새로운 Vision Transformer인 Shifted WINdow Transformer이다.
Abstract
Vision community에서는 모델링을 할 때 CNN에서 최근 Transformer로 넘어오고 있다. (그러나) 지금까지의 연구들은 공간적/시간적 차원에서 patch들을 globally connect하는 Transformer layer에 기반을 두고 있다. 이 논문에서는 video Transformer에서 inductive bias of locality를 이용, self-attention을 globally 계산하는 것보다 더 좋은 결과를 가져왔다.
기본적으로 이 논문은 기존의 Swin Transformer을 시간 차원으로 한 차원 더 확장시켜 이미지에서 비디오로 확장한 논문이다. 최종적으로 Video Action Recognition 등 여러 task에서 좋은 성능을 냈다.
1 Introduction
2020년 이전만 해도 이미지와 비디오를 다루는 데에는 CNN을 사용하는 것이 일반적이었다. 비디오의 경우 3D-CNN을 기반으로 하여 C3D, I3D, R3D 등 많은 논문들이 비디오 관련 문제를 풀어냈다.
그러나 최근에는 ViT를 필두로 Transformer를 이 vision 분야에 적용시키는 연구가 시작되었고 ViViT, MTN, TimeSFormer 등이 빠르게 발표되었다. 또 factorization 접근법 등도 같이 사용되었다.
이 논문에서는 비디오에서 인접한 프레임, 인접한 픽셀 사이에는 spatiotemporal locality(즉, 비슷한 곳이나 때에 있는 픽셀은 비슷한 값을 가짐)가 존재하는 점을 이용, 비디오 전체에 걸쳐 self-attention을 수행하는 대신 국지적으로(locally) 연산을 수행하여 더 작은 모델로 계산량을 대폭 줄이는 방법을 제안한다.
Swin Transformer은 spatial locality에 대한 inductive bias 및 계층적 구조를 채용한다. 이 논문(Video Swin Transformer)는 이 Swin Transformer를 시간 축으로 한 차원 확장하여 비디오에 적용시키는 논문이다.
모델은 대규모 이미지 데이터셋에서 사전학습된 강력한 모델로 쉽게 초기화할 수 있는데, learning rate를 임의로 초기화한 head에 비해 (0.1배쯤?) 더 작게 주면 backbone은 이전 parameter를 서서히 잊으면서 자연스럽게 새로운 video input에 최적화되어 더 좋은 일반화 성능을 가지는 것을 저자들은 발견하였다.
결과적으로, 더 작은 모델 크기를 가지면서도 더 높은 성능을 가지는 모델을 만들 수 있었다. Video Recognition Task(Kinetics-400/600)에서 top-1 정확도는 기존 SOTA인 ViViT를 근소하게 앞선다.
2 Related Works
CNN and variants
Vision 분야에서는 CNN이 전통적인 강자이다. 2D CNN을 시간 축으로 한 차원 확장한 3D-CNN을 비디오에 적용한 논문이 다수 발표되었다. 자세한 내용은 해당 링크 참조.
Self-attention/Transformers to complement CNNs
- NLNet은 self-attention을 visual recognition task에 적용한 최초의 시도였다.
- GCNet은 NLNet의 정확도 향상은 global context 모델링에 기초하는 것을 알고 global context block에 집중하여 성능은 거의 비슷하면서 모델 크기는 크게 줄인 모델을 만들었다.
- DNL은 shared global context는 보존하면서 다른 pixel에 대한 다른 context를 학습할 수 있게 하여 degeneration problem을 완화하였다.
Vision Transformers
- ViT, DeiT이 vision task를 CNN에서 Transformer로 풀도록 이끌었다.
- Swin Transformer는 locality에 inductive bias를, hierarchy, translation invariance를 추가하여 다양한 이미지 인식 task에서 backbone으로 쓸 수 있다.
- Transformer 기반 논문의 성공에 힘입어 비디오로 적용한 논문들(VTN, ViViT, MViT 등)이 다수 발표되었다.
3 Video Swin Transformer
3.1 Overall Architecture
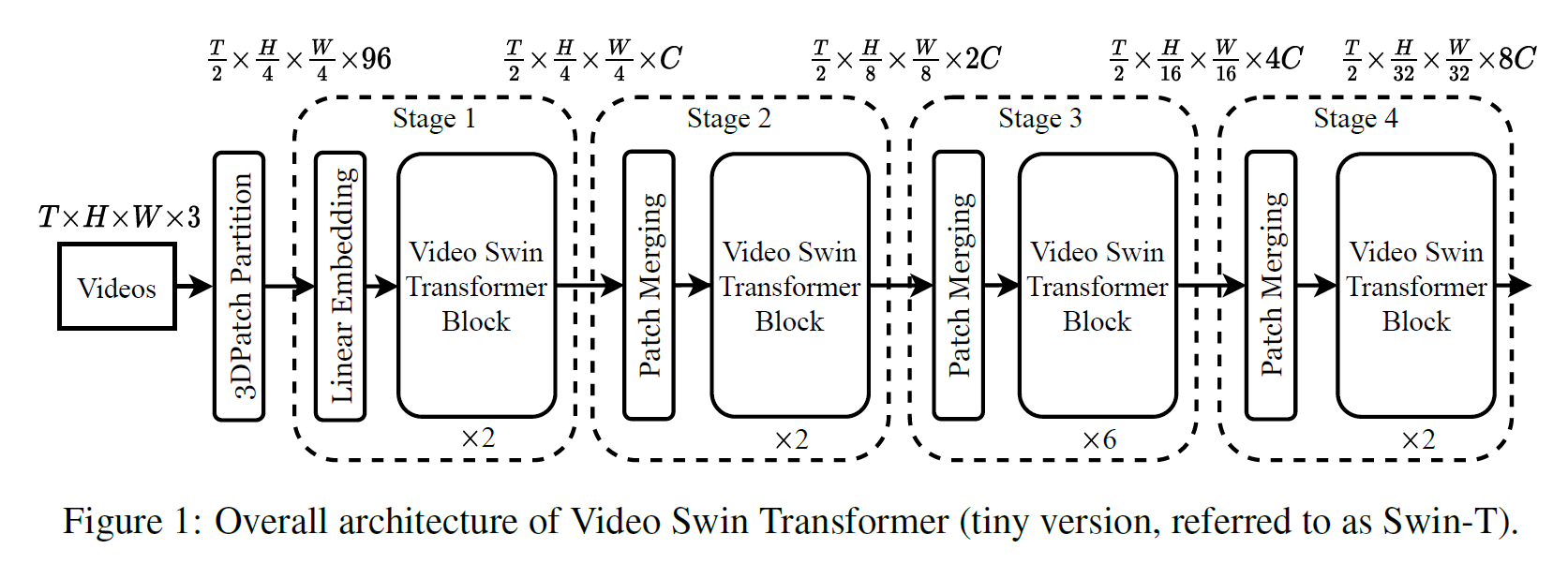
- Swin Transformer를 거의 그대로 계승한다.
- 시간 차원이 추가된 것을 알 수 있다. 단, 공간 차원과 달리 시간 차원은 맨 처음 반으로 줄이는 것 외에 더 건드리지 않는다.
- 시간 차원 외에는 거의 같다. Patch Partition 이후 시간 차원이 반으로 줄어드는데 feature가 48이 96으로 2배 증가한다.
- 위의 그림은 마찬가지로 Tiny 버전이다.
- W-MSA와 SW-MSA가 각각 3D 버전으로 변경되었다.
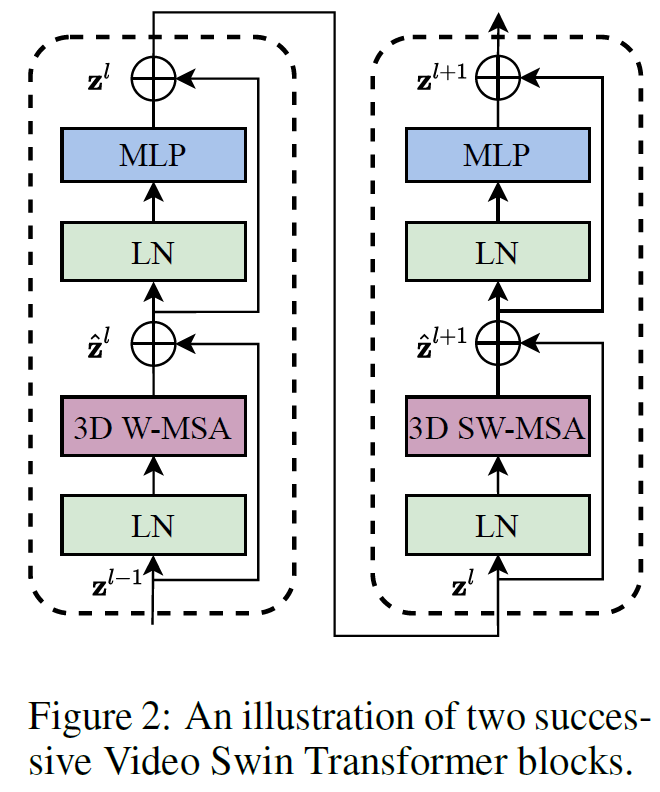
3.2 3D ShiftedWindow based MSA Module
비디오는 이미지에 비해 훨씬 더 많은 정보를 갖고 있기 때문에 계산량이 매우 많아질 수 있다. 그래서 Swin Transformer를 따라 locality inductive bias를 잘 적용한다.
Multi-head self-attention on non-overlapping 3D windows
Swin Transformer의 아이디어를 3차원으로 그대로 확장한다. Swin Transformer를 이해했으면 그냥 넘겨도 된다.
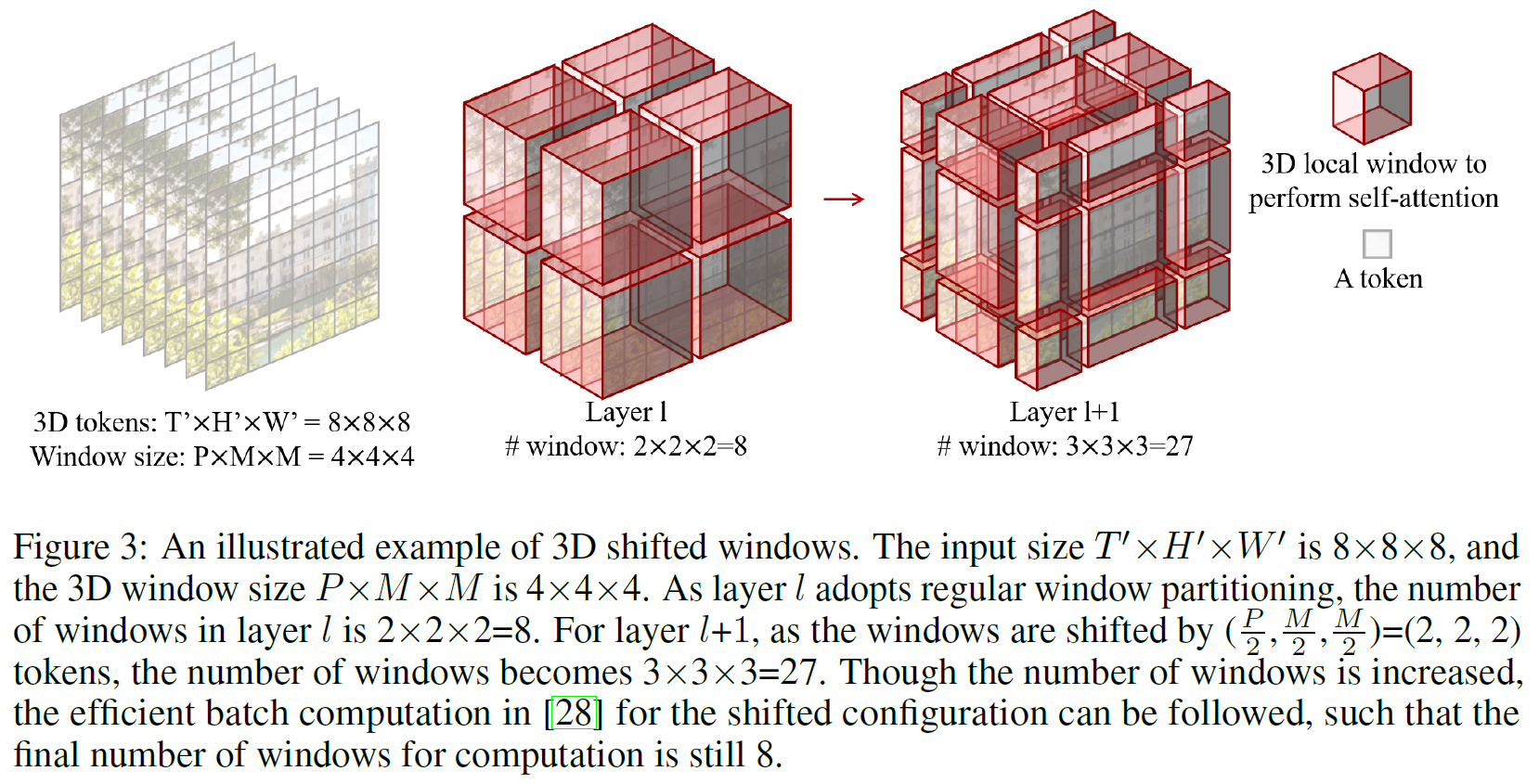
3D Shifted Windows
여기도 마찬가지로 그냥 2D를 3D로 확장한 것이다.
Video Swin Transformer Block은 수식으로 나타내봐도 3D 버전으로 변경된 것 외에 똑같이 생겼다.
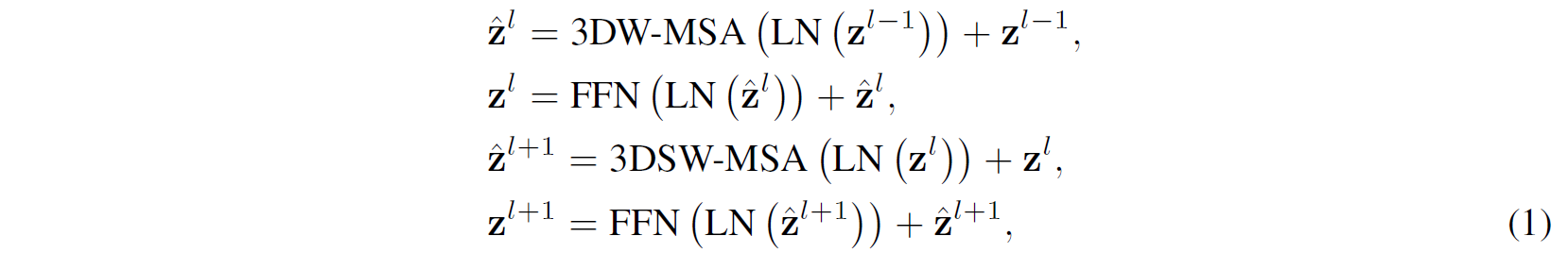
3D Relative Position Bias
Relative Position Bias를 쓰는 것이 낫다는 것이 여러 논문을 통해 입증되었으므로 이를 따른다. 3D relative position bias $B \in \mathbb{R}^{P^2 \times M^2 \times M^2}$를 각 head에 더하여 attention을 수행한다.
\[\text{Attention}(Q, K, V) = \text{SoftMax}(QK^T / \sqrt{d} + B)V\]- $PM^2$는 3D window의 token의 수
- $d$는 query, key의 차원
- $Q, K, V \in \mathbb{R}^{PM^2 \times d}$
그래서 $B$의 범위는 시간 차원으로 $[-P+1, P-1]$, 공간 차원에서 $[-M+1, M-1]$이고, 작은 크기의 bias matrix $\hat{B} \in \mathbb{R}^{(2P-1) \times (2M-1)\times (2M-1)}$를 parameterize하고 $B$의 값은 $\hat{B}$로부터 취한다.
3.3 Architecture Variants
여기랑 똑같다.
$P=8, M=7, d=32$이고 각 MLP의 expansion layer에서 $\alpha=4$이다.
3.4 Initialization from Pre-trained Model
Swin Transformer를 계승한 만큼 비슷하게 대규모 데이터셋에서 사전학습한 모델로 초기화를 시킨다. 기존의 Swin Transformer와는 딱 2개의 block만 다른 shape을 갖는다.
- Stage 1에서 linear embedding layer
- 시간 차원을 반으로 줄이면서 채널이 2배로 늘어났기 때문에($48 \times C \rightarrow 96 \times C$), 일단 weight를 그대로 복사한 다음 전체에 0.5를 곱한다(그러면 variance는 불변이다).
- Video Swin Transformer block의 relative position biases
- shape이 $(2M-1, 2M-1)$에서 $(2P-1, 2M-1, 2M-1)$로 바뀌어야 한다. 그래서 그냥 broadcasting하여 초기화에 사용한다.
4 Experiments
4.1 Setup
Datasets
- Human action recognition으로는 Kinetics-400(400개의 action category가 있으며 240k/20k의 train/val video), Kinetics-600(370k/28.3k video)을 사용하였다.
- Temporal modeling을 위해서는 Something-Something V2 (SSv2)(174 classes, 168.9K/24.7K video)를 사용하였다.
- top-1와 top-5 정확도로 평가한다.
Implementation Details
- K400, K600: $224 \times 224$ 해상도의 비디오는 $16 \times 56 \times 56$의 3D token이 된다.
- SSv2: Kinetics-400에서 사전학습한 모델로 초기화를 하고 시간 차원에서 window size는 16을 사용했다.
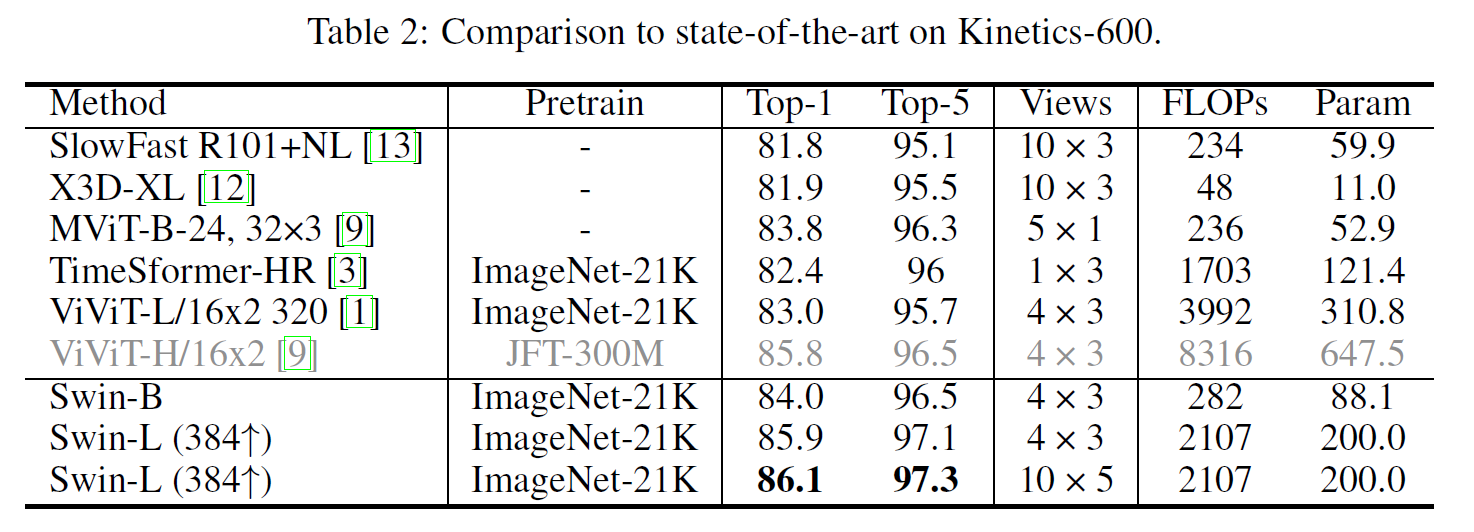
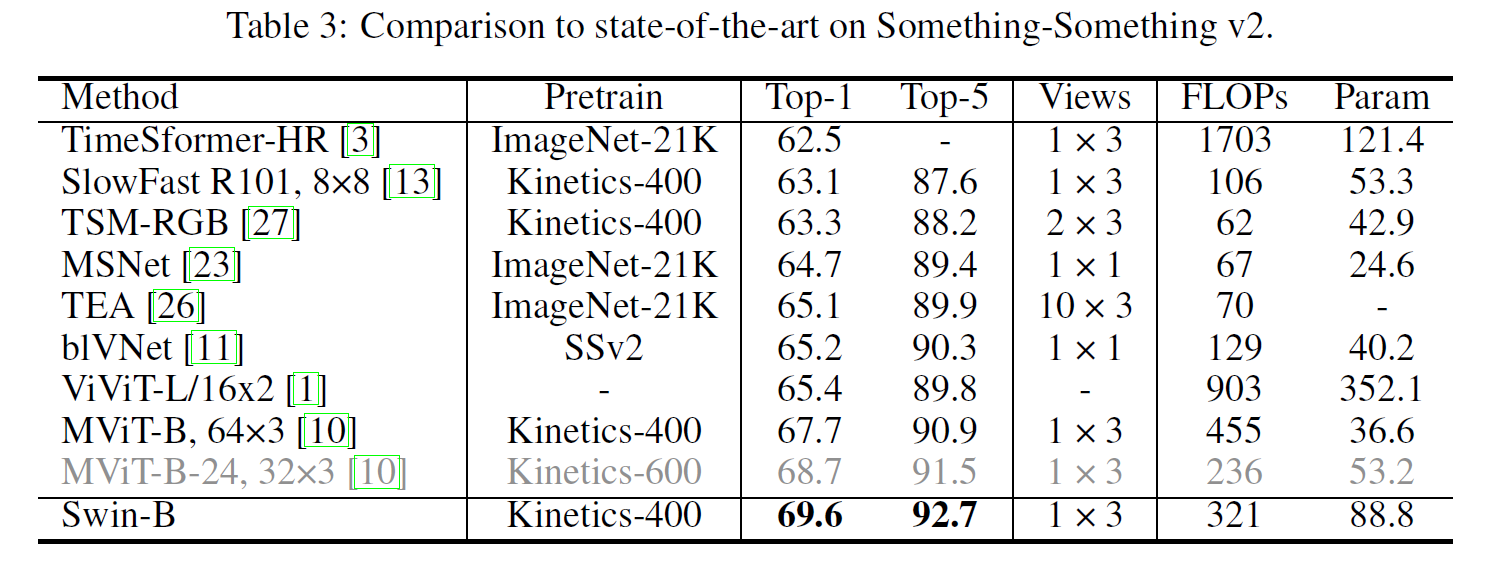
4.2 Comparison to state-of-the-art
와! SOTA!
4.3 Ablation Study
Different designs for spatiotemporal attention
Spatio-temporal attention을 3가지 다른 디자인을 사용하여 구현하고 평가해 보았다.
- Joint: spatiotemporal attention을 각 3D windows-based MSA layer에서 계산하며, 기본 세팅이다.
- Split: 2개의 temporal transformer layer를 spatial-only Swin Transformer의 위에 추가하였다. 이는 ViViT와 VTN에서 유용하다고 입증되었다.
- Factorized: Swin Transformer의 각 spatial-only MSA layer 뒤에 temporal-only MSA를 추가한 것으로 TimeSFormer에서 효과적이었던 방법이다.
- 임의로 초기화된 layer를 더하는 것의 bad effect를 줄이기 위해 0으로 초기화한 각 temporal-only MSA layer의 끝에 weighting parameter를 추가했다.

계산량도 적고 성능도 좋은 joint 버전을 쓰자. 이 논문에서는 이게 기본값이다.
이렇게 나온 이유는 joint 버전이 공간 차원에서 locality가 효율성은 보존하면서 계산량은 줄일 수 있기 때문이라고 한다.
Temporal dimension of 3D tokens, Temporal window size
window size를 temporal dimension을 바꿔가면서 가장 좋은 값을 찾아보았다.
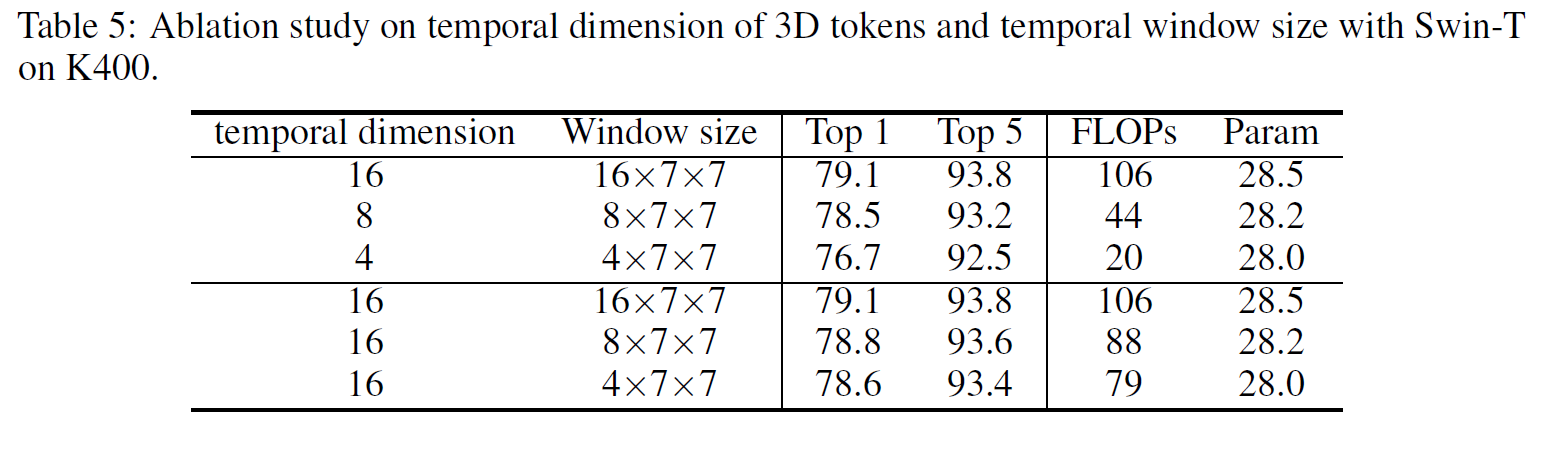
- temporal dimension이 크면 성능은 좋지만 계산량이 기하급수적으로 늘어난다.
- temporal dimension은 16으로 고정하고 window size를 달리 해 보았을 때, 크기가 커질수록 성능은 매우 조금 올라가지만(0.3 point) 계산량은 꽤 많이 늘어난다(17%).
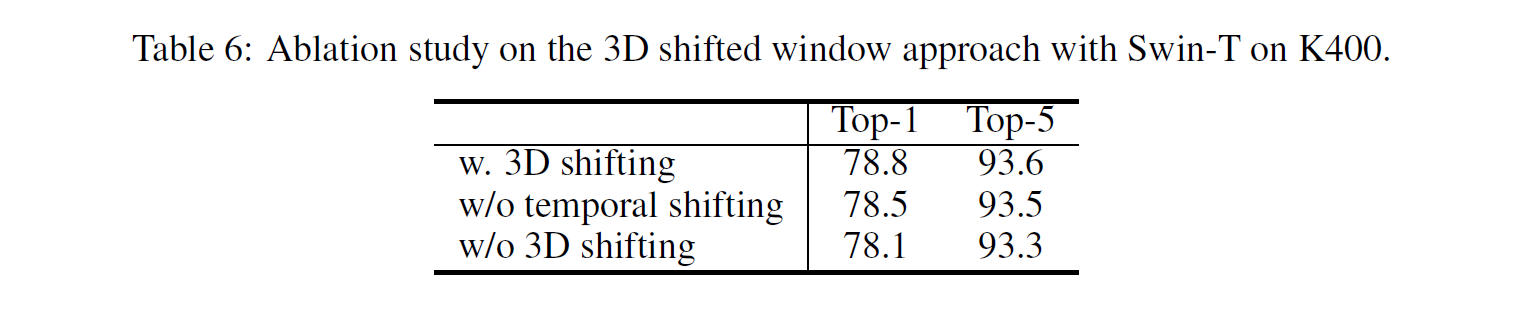
3D shifted windows
3D shifted window 기법을 쓰는 것이 낫다는 내용이다.
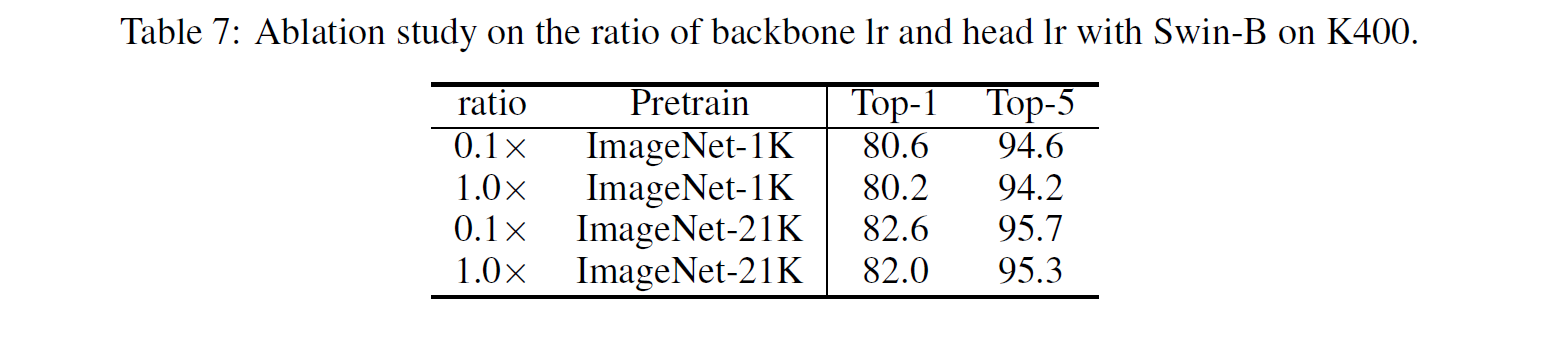
Ratio of backbone/head learning rate
서론에서 잠깐 언급한 내용인데, backbone의 learning rate를 head의 0.1배로 하면 성능이 더 잘 나온다.
Initialization on linear embedding layer and 3D relative position bias matrix
ViViT에서는 center initialization이 inflate initialization를 크게 상회한다고 해서 이를 실험해 보았다.
하지만 성능은 사실상 똑같아서, linear embedding layer에 inflate initialization을 사용했다.

5 Conclusion
Swin Transformer를 3차원으로 확장하여 실험하여 Kinetics-400, Kinetics-600, SSv2에서 SOTA를 달성하였다.