
Swin Transformer V2 - Scaling Up Capacity and Resolution 논문 설명
15 Dec 2021 | Transformer Swin Transformer Microsoft Research목차
- Swin Transformer V2: Scaling Up Capacity and Resolution
이 글에서는 Microsoft Research Asia에서 발표한 Swin Transformer의 개선 버전, Swin Transformer v2 논문을 간략하게 정리한다.
Swin Transformer V2: Scaling Up Capacity and Resolution
논문 링크: Swin Transformer V2: Scaling Up Capacity and Resolution
Github: https://github.com/microsoft/Swin-Transformer
- 2021년 11월(Arxiv)
- Microsoft Research Asia
- Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei et al.
기존 Shifted WINdow Transformer을 더 큰 모델, 고해상도의 이미지에서 더 안정적으로 학습하는 것과 모델의 성능을 높이는 여러 테크닉을 기술하는 논문이다.
Abstract
기존의 Swin Transformer v1을 30억 개의 parameter, $1536 \times 1536$ 크기의 이미지에도 적용할 수 있게 개선한다. 이 논문에서 제시하는 vision model의 크기를 키우는 방법은 다른 모델에서 충분히 적용 가능하다고 한다.
해결해야 할 부분은
- Vision model은 크기를 키울 때 학습이 불안정한 문제가 있고
- 고해상도의 이미지 혹은 window를 요구하는 많은 downstream vision task의 경우 어떻게 낮은 해상도를 처리하는 모델에서 높은 해상도를 처리하는 모델로 전이학습(transfer learninng)이 효과적으로 잘 될 수 있는지 불분명하다는 것이다.
큰 모델, 고해상도의 이미지를 처리할 때는 GPU 메모리 사용량도 중요한 문제인데, 이를 해결하기 위해 여러 기법을 적용해본다:
- 큰 모델의 학습 안정성을 높이기 위해 normalization을 attention 이전이 아닌 다음에 적용하고(post normalization) scaled cosine attention 접근법을 적용한다.
- 저해상도에서 고해상도 모델로 전이학습할 시 위치 정보를 log-scale로 continuous하게 표현한다.
- 이외에 GPU 메모리 사용량을 줄이는 여러 기법을 소개한다.
1. Introduction
작은 vision model에서 큰 vision model로 전이학습할 때 학습이 불안정한 문제가 있다. 이 논문에서 저자들은 activation의 진폭(amplitude)이 불일치한다는 것을 발견했다고 한다. 그리고 이는 기존의 Swin Transformer v1에서는 residual unit이 main branch에 그대로 더해져서 layer를 거칠수록 값이 누적되어 점차 크기가 커지기 때문이라고 한다. 그래서 이를 해결하기 위한 방법으로 post normalization 기법을 적용한다.
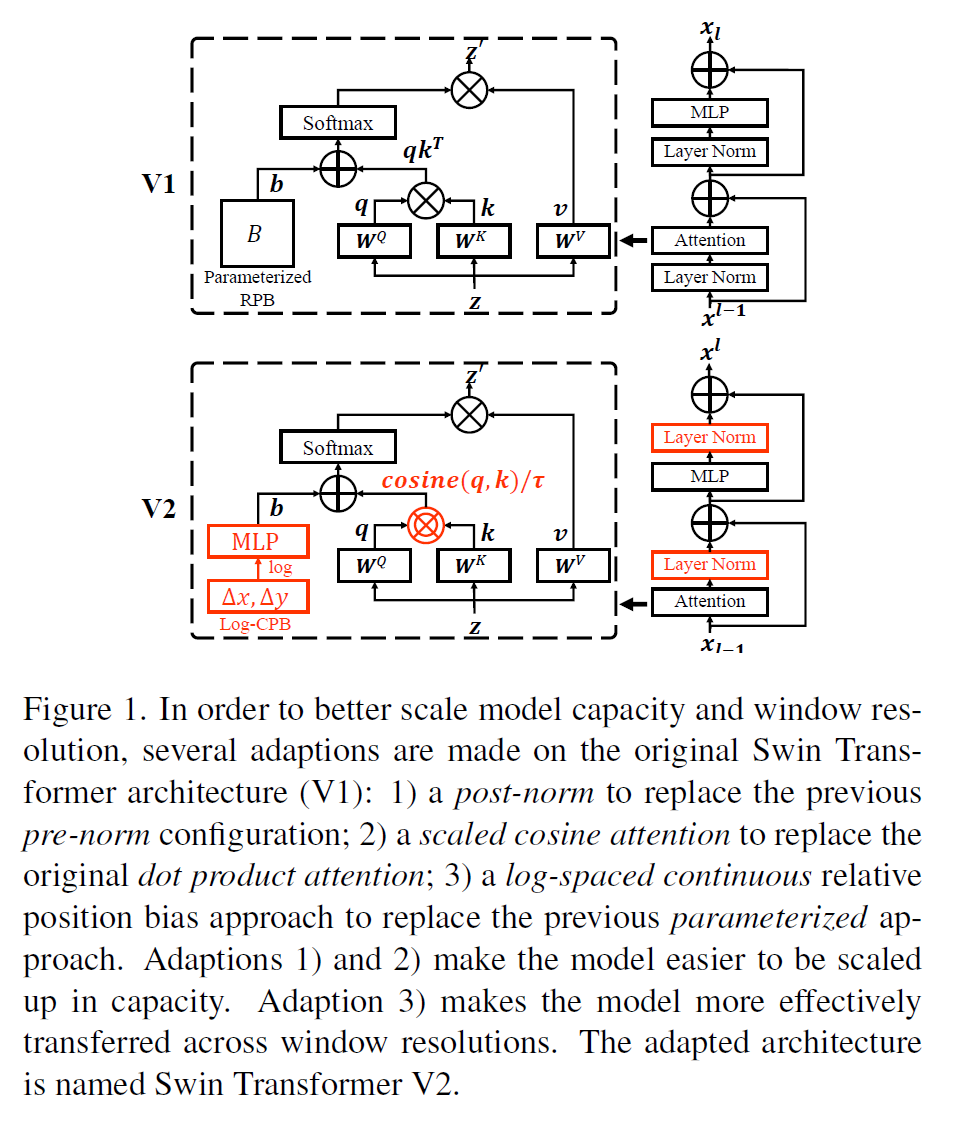
그림 1에서와 같이 layer norm을 각 residual unit의 처음 부분에서 끝 부분으로 옮긴다. 이렇게 하면 activation 값이 한층 낮아지게 된다.
또 기존 dot-product attention 대신 scaled cosine attention을 사용했는데, 이는 block 입력의 진폭에 별 관계없이 연산이 수행되고 따라서 attention value는 안정된 값을 유지한다.
이러한 방법들은 더 큰 모델에서 학습의 안정성을 높이고 최종 성능 또한 향상시키는 결과를 가져왔다.
그리고 또 하나의 문제가 있는데 작은 크기의 이미지를 다룰 때의 window size와 큰 크기의 이미지에서 fine-tuning할 때의 window size는 많이 차이가 난다. 기존의 방법은 bi-cubit interpolation을 수행하는 것인데 이는 땜질에 불과하고, 이 논문에서는 log-scale continuous position bias(Log-CPB)를 제안한다.
이는 작은 meta network를 하나 만들어 적용하는 방법이다. 이 meta net은 임의의 좌표를 받아 log-space로 변환하므로 extrapolation 비율이 작으며, 모델 간 공유가 가능하기 때문에 이미지의 해상도가 변해도 문제 없이 사용할 수 있다.
또 고해상도 이미지를 처리하려면 GPU 사용량이 크게 증가하는데, 이를 줄이기 위해 다음 테크닉을 사용한다.
- Zero-Optimizer
- Activation Check Pointing
- a Novel implementation of sequential self-attention computation
위의 방법들을 사용하여, 더 큰 모델을 안정적으로 학습, 더 좋은 성능을 얻을 수 있다. Swin Transformer v1와 마찬가지로 Image Classification, Object Detection, Semantic Segmentation task에서 실험하였고, 기존보다 더 좋은 결과를 얻었다.
2. Related Works
Language networks and scaling up
NLP 분야에서는 이미 큰 모델일수록 좋다는 것이 입증되어 있다.
BERT-340M, Megatron-Turing-530B, Switch-Transformer-1.6T 등이 제안되었다.
Vision networks and scaling up
그러나 이미지 분야에서는 모델 크기를 키우는 시도가 별로 없었다. (다루기 힘들기 때문인가..) JFT-3B 정도가 있다.
Transferring across window / kernel resolution
- 기존의 CNN 논문들은 고정된 크기의 kernel(ex. 1, 3, 5)만을 사용하였다.
- ViT와 같은 global vision transformer에서는 이미지 전체에 attention을 적용하며 입력 이미지의 해상도에 따라 window size가 정비례하여 증가한다.
- Swin Transformer v1와 같은 local vision transformer는 window size가 고정되어 있거나 fine-tuning 중에 변화할 수 있다.
- 다양한 scale의 이미지를 처리하기 위해서는 아무래도 window size가 가변적인 것이 편하다. 여기서는 log-CPB를 통해 전이학습이 좀 더 부드럽게 가능하게 한다.
Study on bias terms, Continuous convolution and variants
기존 Transformer는 절대위치 embedding을 사용하였으나 요즘의 이미지 분야 연구에서는 상대위치를 쓴다. 이 논문에서 계속 강조하는 log-CPB는 임의의 window size에서 더 잘 작동한다고 하고 있다.
3. Swin Transformer V2
3.1. A Brief Review of Swin Transformer
여기를 보면 될 것 같다.
Issues in scaling up model capacity and window resolution
앞에서 계속 설명했던 내용이다.
- 모델의 크기를 키울 때 학습 불안정성 문제가 발생한다.
- 전이학습할 때 window resolution이 달라지며 성능 하락이 일어난다.
3.2. Scaling Up Model Capacity
역시 같은 내용이 나온다. ViT를 일부 계승한 Swin Transformer는 Layer norm을 각 block의 처음 부분에서 적용하는데 이는 깊은 layer로 갈수록 activation이 점점 극적으로 커지게 된다.
Post normalization
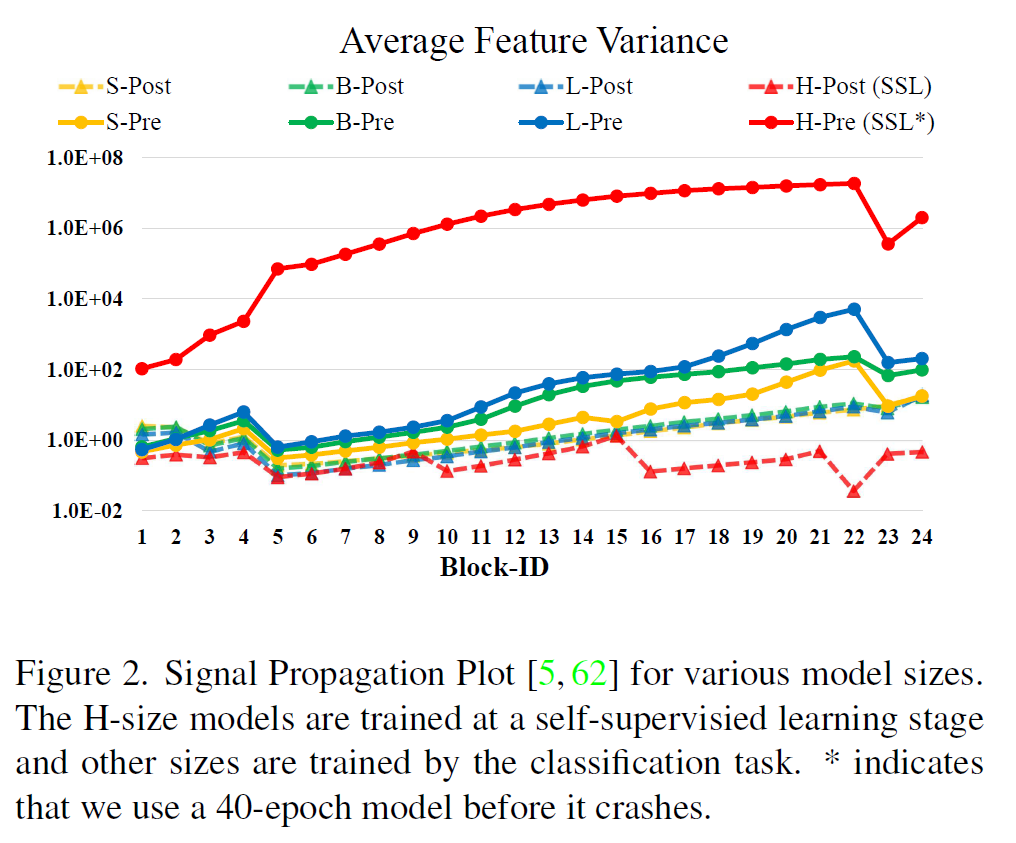
그래서 이 post normalization을 적용하는 것이다. 서론 부분에서도 말했듯이, layer norm을 block의 처음에서 끝으로 옮긴다(그림 1). 그러면 layer를 계속 통과해도 activation 진폭이 크게 커지지 않는다. 아래 그림에서 pre- 방식과 post- 방식의 activation amplitude 차이를 볼 수 있다.
Scaled cosine attention
기존 Transformer는 query와 key 간 유사도를 계산할 때 dot-product로 계산한다. 하지만, 특히 큰 크기의 vision model에서, 일부 pixel에 의해 그 전체 값이 dominated되는 문제가 발생한다.
따라서 그냥 dot-product 대신 scaled cosine 연산을 적용한다. 물론 Swin Transformer v1처럼 position bias는 이때 더해진다.
\[\text{Sim}(\textbf{q}_i, \textbf{k}_j) = \text{cos}(\textbf{q}_i, \textbf{k}_j)/\tau + B_{ij}\]$\tau$는 학습가능한 scalar 값(0.01 이상으로 설정)이며 layer나 head간 공유는 되지 않는다.
3.3. Scaling UpWindow Resolution
여러 window resolution에서 부드럽게 잘 넘어갈 수 있는 relative bias 정책인 log-CPB를 소개한다.
Continuous relative position bias
parameterized bias를 직접 최적화하는 대신 continuous position bias를 상대 좌표 하에서 작은 meta network에 맞춘다:
\[B(\Delta x, \Delta y) = \mathcal{G}(\Delta x, \Delta y)\]$\mathcal{G}$는 2-layer MLP(사이의 activation: RELU)와 같은 작은 network이다. 이 $\mathcal{G}$가 임의의 상대좌표에 대해 bias value를 생성하고 따라서 어떤 크기의 window에든지 적절한 값을 생성할 수 있다. 추론 시에는 각 상대 위치를 사전에 계산할 수 있고 모델 parameter로 저장할 수 있으며, 이는 원래 parameterized bias 접근법과 같은 수준으로 간편?(convenient)..하다.
Log-spaced coordinates
해상도가 커질수록 상대 좌표의 차이도 커질텐데, 이를 정비례하게 잡으면 그 차이가 너무 커진다. 그래서 log-scale로 바꾼다.
\[\widehat{\Delta x} = \text{sign}(x) \cdot \log(1+\vert \Delta x \vert )\] \[\widehat{\Delta y} = \text{sign}(y) \cdot \log(1+\vert \Delta y \vert )\]예를 들어 $8 \times 8$ 크기의 window를 $16 \times 16$으로 키우면, 선형 비례하게 차이를 잡을 경우 $[-7, 7]$에서 [-15, 15]가 되므로 $8/7 = 1.14$배만큼 extrapolate해야 한다. 그러나 log-scale의 경우 $0.33$배로 줄어든다.
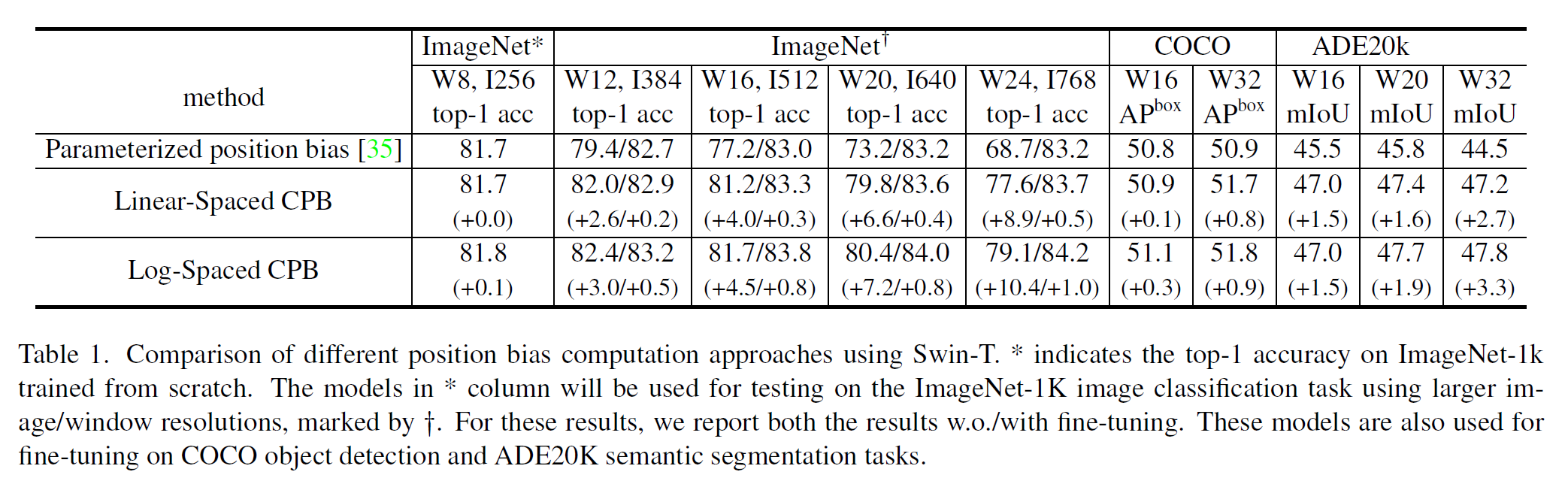
아래 표에서 position bias 정책 별 성능 차이를 볼 수 있다. 물론 log-space CPB가 가장 좋다고 한다.
3.4. Other Implementation
Implementation to save GPU memory
이 논문에서 GPU 메모리 사용량을 줄이기 위해 사용한 테크닉을 정리한다.
- Zero-Redundancy Optimizer (ZeRO)
- 기본 optimizer는 data-parallel mode에서 모델 parameter와 optimization state를 모든 GPU나 master node에 broadcast한다. 이는 큰 모델에서 매우 비효율적인데, 예를 들어 3B개의 parameter + Adam optimizer, fp32 정밀도를 사용할 경우 48G의 메모리를 잡아먹는다.
- ZeRO optimizer는 모델 parameter와 거기에 연관되는 optimizer state가 여러 개의 GPU에 분산 저장되어 사용량이 매우 줄어든다.
- 이 논문에서는 DeepSpeed framework와 ZeRO stage-1 option을 사용했다.
- Activation check-pointing
- Transformer의 feature maps 역시 많은 메모리를 잡아먹는데, 이는 이미지와 window가 고해상도일 경우 병목이 될 수 있다. 이 최적화는 학습속도를 30% 가량 향상시킬 수 있다.
- ..를 의미한 것 같은데 논문에는 어떤 최적화인지 잘 안 나와 있고, 또 학습 “속도”가 30%까지 reduce할 수 있다고 되어 있는 것 같다(This optimization will reduce training speed by at most 30%.))..? 약간의 오류인 것 같다.
- Sequential self-attention computation
- 큰 모델을 초고해상도의 이미지, 예를 들어 $1536 \times 1536$ 해상도의 이미지와 $32 \times 32$의 window size를 사용할 때에는, 위의 두 최적화 전략을 사용해도 여전히 부담스럽다(40G). 여기서 병목은 self-attention module인데,
- 이를 해결하기 위해 이전의 batch 연산을 (전부) 사용하는 대신 self-attention 연산을 순차적으로 수행하도록 구현했다.
- 이는 첫 2개의 stage에서만 적용하였고, 이는 전체 학습 속도에는 큰 영향을 주지는 않는다.
이러한 과정을 통해 A100 GPU(메모리: 40G)에서 $1536 \times 1536$ 해상의 이미지를 3B 개의 parameter를 갖는 모델로 학습할 수 있었다. Kinetics-400은 $320 \times 320 \times 8$의 해상도에서 실험했다.
Joining with a self-supervised approach
큰 모델은 항상 데이터 부족 현상에 시달린다. 방법은 매우 큰 데이터셋을 구해오거나(음?) self-supervised 사전학습을 이용하는 것인데, 이 논문에서는 둘 다 쓴다..
ImageNet-22K 데이터셋을 noisy label과 함께 5배 늘려 70M개의 이미지를 갖도록 했다. 그러나 여전히 JFT-3B에는 크게 못 미치므로, self-supervised learning 접근법을 적용시켰다.
3.5. Model configurations
기존 Swin Transformer v1의 4개 크기의 모델에 더해 더 큰 모델 2개를 추가했다.
- Swin-H: $C = 352$, layer numbers = {2, 2, 18, 2}
- Swin-G: $C = 512$, layer numbers = {2, 2, 42, 2}
각각 658M과 3B 크기이다. Huge와 Giant 모델에 대해서는 6 layer마다 main branch에 layer norm을 추가했다.
그리고 시간을 아끼기 위해 Huge 모델은 실험하지 않았다. (그럼 왜 만든건가 싶긴 하지만..)
Experiments
4.1. Tasks and Datasets
Swin Transformer v1의 3가지 task에다가 하나를 더 추가했다.
- Video action classification으로는 Kinetics-400 (K400)
4.2. Scaling Up Experiments
Settings for SwinV2-G experiments
학습 시간을 줄이기 위해 $192 \times 192$ 해상도의 이미지로 사전학습을 진행했다.
- 먼저 ImageNet-22K로 20 epoch 동안 self-supervised 학습을 시키고
- 같은 데이터셋에 classification task로 30 epoch 동안 학습을 시킨다. 더 자세한 내용은 부록 참조.
이제 결과를 감상할 시간이다.
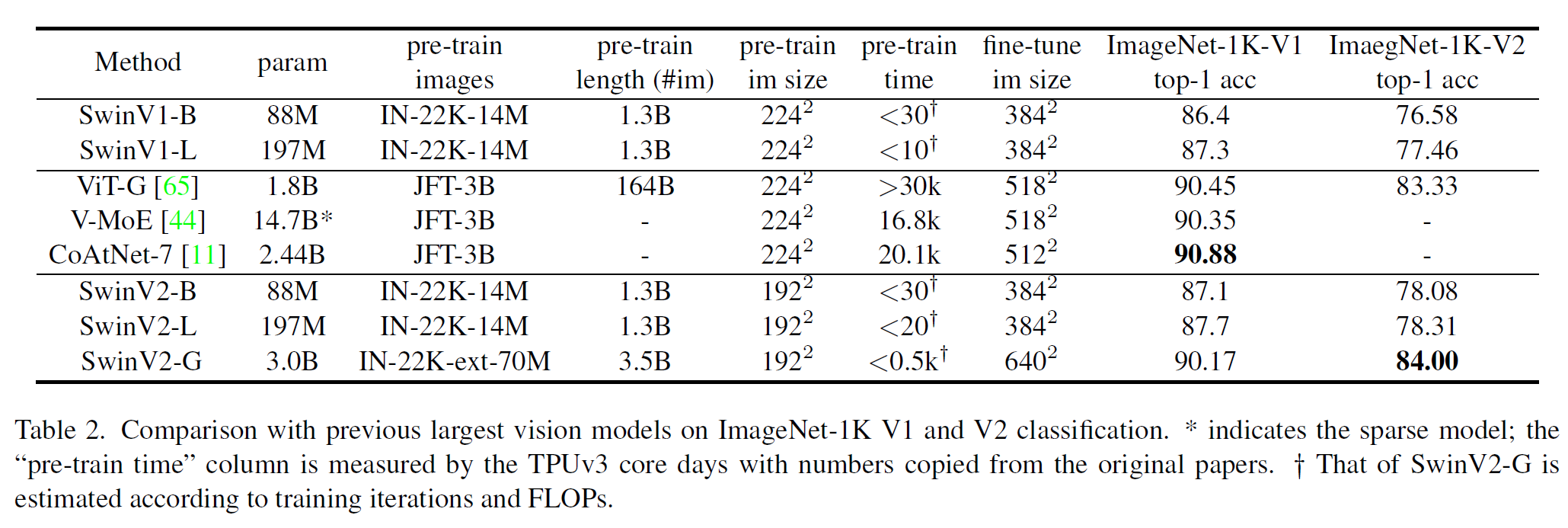
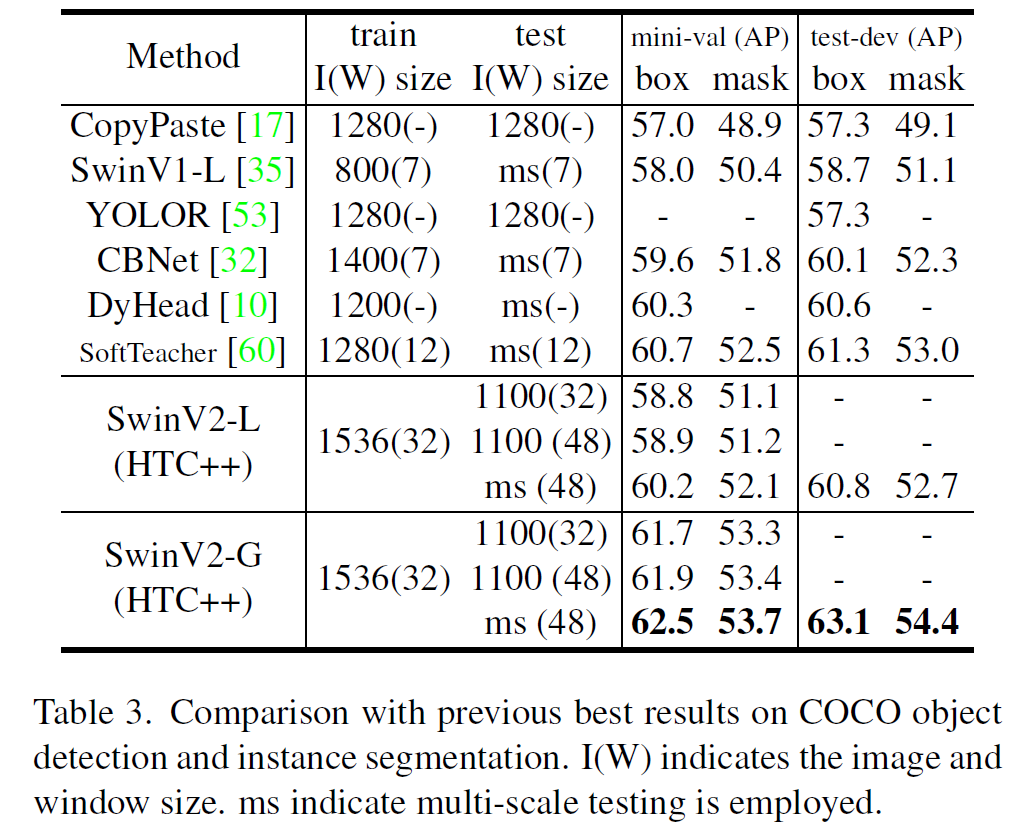
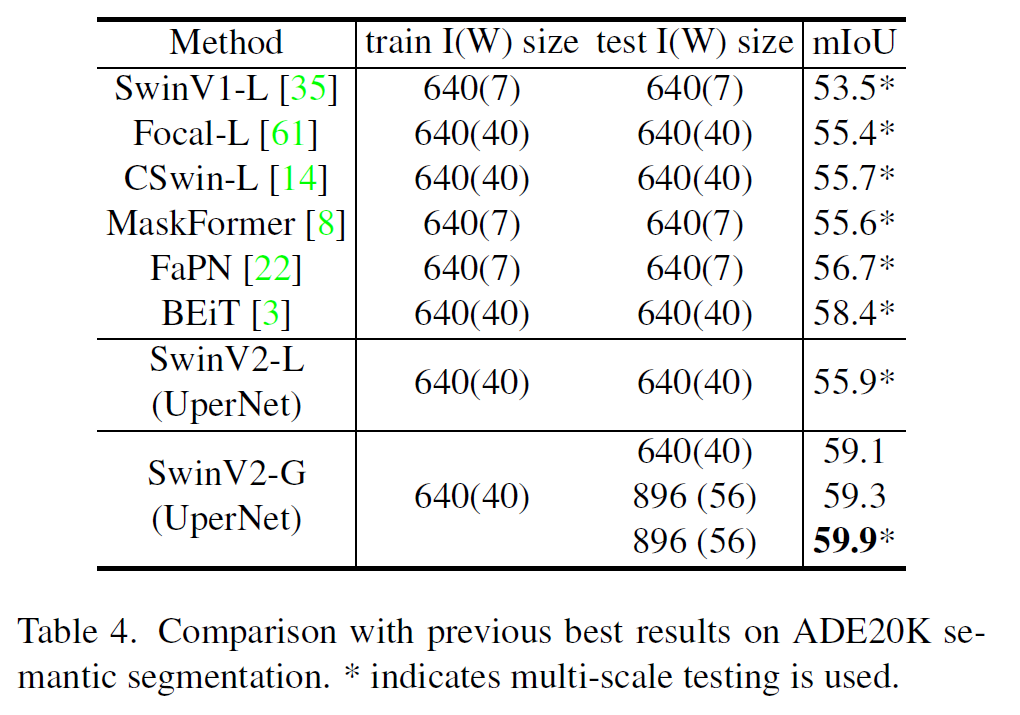
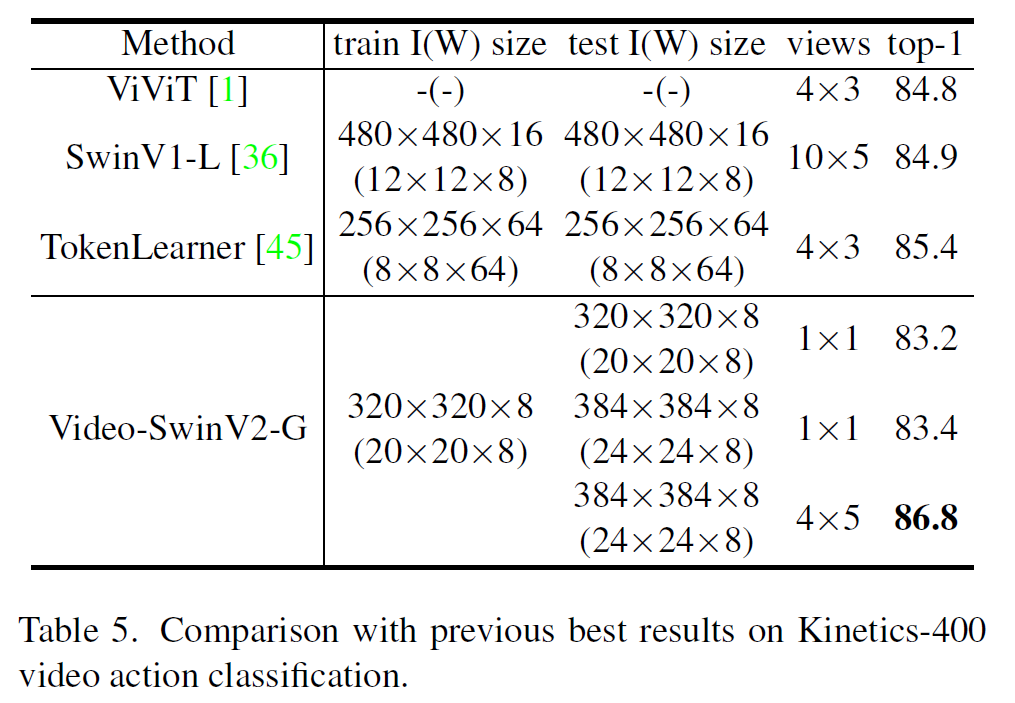
당연히 모델이 클수록 성능이 좋으며, 상당히 최근에 나온 논문들보다 성능은 더 좋다.
4.3. Ablation Study
3.2절에서 설명한 기법들의 효과를 검증한다.
Ablation on post-norm and scaled cosine attention
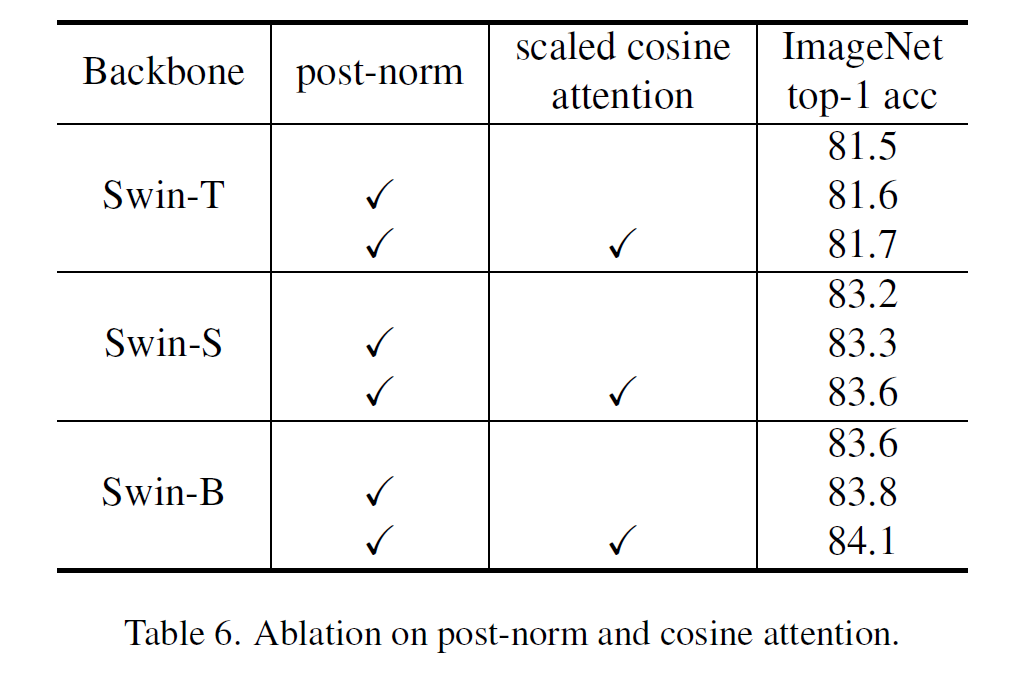
post-norm을 쓰면 top-1 정확도가 0.1~0.2정도, scaled cosine attention까지 적용하면 거기에 0.1~0.3%정도 더 성능이 올라가는것을 볼 수 있다. 또, 학습 안정성에도 효과가 있다고 한다. (그림 2 참조)
그리고 log-CPB의 효과는 아래와 같다.
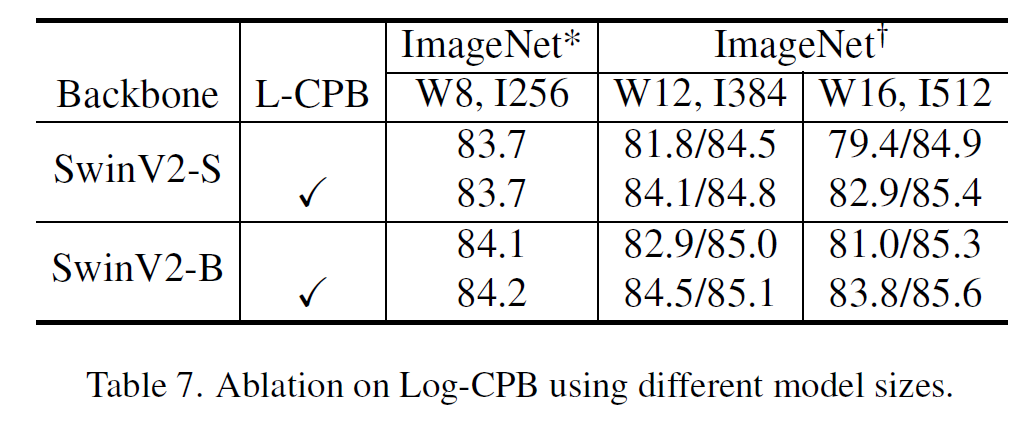
5. Conclusion
Swin Transformer v1을 대규모 모델, 더 큰 이미지에 대해 학습이 안정적으로 가능하도록 여러 기법을 사용하여 개선하였다.
- post-norm, scaled cosine attention, log-CPB 등.
이로써 Image Classification, Object Detection, Semantic Segmantation, Video Action Classification에서 좋은 성능을 얻었다.
근데 뭐, 가장 큰 모델은 40G 메모리의 A100 정도를 갖고 있어야 할 수 있는 것 같은데..기법들은 참고할 만한 논문이다.