
BLEURT - Learning Robust Metrics for Text Generation(BLEU 개선 버전, BLEURT 논문 설명)
13 Jan 2021 | Paper_Review NLP Evaluation_Metric목차
- BLEURT: Learning Robust Metrics for Text Generation
- 초록(Abstract)
- 1. 서론(Introduction)
- 2. 서두(Preliminaries)
- 3. 품질 평가를 위한 미세조정 BERT(Fine-Tuning BERT for Quality Evaluation)
- 4. 합성 데이터에서 사전학습(Pre-Training on Synthetic Data)
- 5. 실험(Experiments)
- 6. 관련 연구(Related Work)
- 7. 결론(Conclusion)
- Refenrences
- Appendix A Implementation Details of the Pre-Training Phase
- Appendix B Experiments–Supplementary Material
이 글에서는 2020년 ACL에 Google Research 팀의 Thibault Sellam 등이 게재한 BLEURT: Learning Robust Metrics for Text Generation를 살펴보도록 한다.
구글 AI 블로그에서 이 논문에 대한 설명을 볼 수 있다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
BLEURT: Learning Robust Metrics for Text Generation
논문 링크: BLEURT: Learning Robust Metrics for Text Generation
홈페이지: 구글 AI 블로그
Tensorflow code: Official Code
초록(Abstract)
텍스트 생성은 지난 몇 년간 상당한 발전을 이루었다. 그러나 아직 그 평가 방법은 매우 뒤떨어져 있는데, 가장 자주 사용되는 BLEU나 ROUGE는 사람의 판단과는 낮은 연관성을 갖는다(즉, 사람이 보기에 별로 적절치 않다). 이 논문에서는 BLEURT라는 새 평가 방법을 제안하는데, BERT에 기반한 학습된 평가방법으로 수천 개 정도의 학습 예시만으로도 사람의 판단 방식을 모델링할 수 있다. 이 접근법의 핵심은 수백만 개의 합성된 예시를 모델을 일반화하기 위해 사용하는 새로운 사전학습 방식이라는 것이다. BLEURT는 WMT Metrics와 WebNLG Competition 데이터셋에서 state-of-the-art 결과를 얻었다. 바닐라 BERT 기반 방식과는 다르게, BLEURT는 학습 데이터가 드물고 기존 분포에서 벗어나도 훌륭한 결과를 보여준다.
1. 서론(Introduction)
지난 몇 년간, 자연어생성 분야에서의 연구는 번역, 요약, 구조화된 데이터 → 텍스트 생성, 대화 및 이미지 캡션 등을 포함한 많은 문제에서 encoder-decoder 신경망을 통해 상당한 발전을 이루었다. 하지만, 평가 방법의 부족으로 인해 발전이 적지 않게 지연되었다.
인간 평가(Human Evaluation)는 시스템의 품질을 측정하는 데 있어서 종종 최선의 지표가 되지만, 이는 매우 비싸며 상당히 시간이 많이 소요되는 작업으로 매일 모델 개발의 pipeline에 넣을 수는 없다. 그래서, NLG 연구자들은 보통 계산이 빠르고 그럭저럭 괜찮은 품질의 결과를 주는 자동 평가방법(automatic evaluation metrics)을 사용해 왔다. 이 논문에서는 문장 수준의, 참조 기반 평가 방법으로, 어떤 후보 문장이 참조 문장과 얼마나 비슷한지를 측정하는 방법을 제시한다.
1세대 평가방법은 문장 간의 표면적 유사도를 측정하기 위해 수동으로 만들어졌다. BLEU와 ROUGE라는 두 개의 방법이 N-gram 중첩(overlap)에 기반하여 만들어졌다. 이러한 평가방법은 오직 어휘의 변화에만 민감하며, 의미적 또는 문법적인 측면의 변화는 제대로 측정하지 못하였다. 따라서, 이러한 방식은 사람의 판단과는 거리가 멀었으며, 특히 비교할 시스템이 비슷한 정확도를 가질 때 더욱 그렇다.
NLG 연구자들은 이 문제를 학습된 구성 요소를 이 평가방법에 집어넣음으로써 다뤄 왔다. WMR Metrics Shard Task라는, 번역 평가에서 자주 사용되는 평가방법이 있다. 최근 2년간은 신경망에 기반한 RUSE, YiSi, ESIM이 많이 사용되었다. 최근의 방법들은 다음 가지로 나뉜다:
- 완전히 학습된 평가방법.
- BEER, RUSE, ESIM
- 일반적으로 end-to-end 방식으로 학습되었으며, 보통 수동으로 만든 feature나 학습된 embedding에 의존한다.
- 훌륭한 표현능력(expressivity)를 가진다.
- 유창성, 충실함, 문법, 스타일 등 task-specific한 속성을 가지도록 튜닝할 수 있다.
- Hybrid 평가방법.
- YiSi, BERTscore
- 학습된 요소(contextual embeddings)를 수동으로 만든 논리(token alignment 규칙)와 결합한다.
- 강건성(Robustness)를 확보할 수 있다.
- 학습 데이터가 적거나 없는 상황에서 좋은 결과를 얻을 수 있다.
- train/test 데이터가 같은 분포에 존재한다는 가정을 하지 않는다.
사실, IID 가정은 domain drift 문제에 의해 NLG 평가에서 특히 문제가 되었다. 이는 평가방법의 주 목적이지만, quality drift 때문이기도 하다: NLG 시스템은 시간이 지남에 따라 더 좋아지는 경향을 보이며, 따라서 2015년에 rating data로 학습한 모델은 2019년의 최신 모델을 구별하지 못할 수 있다(특히 더 최근 것일수록). 이상적인 학습된 평가방법은 학습을 위해 이용가능한 rating data를 완전히 활용하고, 분포의 이탈(drift)에 강간한 것을 모두 확보하는 것이다. 즉 추론extrapolate할 수 있어야 한다.
이 논문에서 통찰한 바는 표현능력과 강건성을 인간 rating에 미세조정하기 전 대량의 합성 데이터에서 사전학습하는 방식으로 결합하는 것이 가능하다는 것이다.
여기서 BERT에 기반한 텍스트 생성 평가방법으로 BLEURT를 제안한다. 핵심은 새로운 사전학습 방법으로, 어휘적 그리고 의미적으로 다양한 감독 signal(supervision signals)를 얻을 수 있는 다양한 Wikipedia 문장에서 임의의 변화(perturbation)을 준 문장들을 사용하는 방법이다.
BLEURT를 영어에서 학습하고 다른 일반화 영역에서 테스트한다. 먼저 WMT Metrics Shared task의 모든 연도에서 state-of-the-art 결과를 보인다. 그리고 스트레스 테스트를 하여 WMT 2017에 기반한 종합평가에서 품질 이탈에 대처하는 능력을 측정한다. 마지막으로, data-to-text 데이터셋인 WebNLG 2017으로부터 얻는 3개의 task에서 다른 도메인으로 쉽게 조정할 수 있음을 보인다. Ablation 연구는 이 종합 사전학습 방법이 IID 세팅에서 그 성능을 증가시키며, 특히 학습 데이터가 편향되어 있거나, 부족하거나, 도메인을 벗어나는 경우에 더 강건함을 보인다.
코드와 사전학습 모델은 온라인에서 볼 수 있다.
2. 서두(Preliminaries)
$x = (x_1, …, x_r)$는 $r$개의 token을 갖는 참조 문장이며 $\tilde{x} = (\tilde{x}_1, …, \tilde{x}_p)$는 길이 $p$의 예측 문장이다. $y$가 예측 문장이 참조 문장과 관련하여 얼마나 좋은지를 사람이 정한 값이라 할 때 크기 $N$의 학습 데이터셋은 다음과 같이 쓴다.
\[\lbrace (x_i, \tilde{x}_i, y_i) \rbrace^N_{n=1}\]학습 데이터가 주어지면, 우리의 목표는 사람의 평가를 예측하는 함수 $f : (x, \tilde{x}) \rightarrow y$를 학습하는 것이다.
3. 품질 평가를 위한 미세조정 BERT(Fine-Tuning BERT for Quality Evaluation)
적은 양의 rating(rating) 데이터가 주어졌을 때, 이 task를 위해 비지도 표현을 사용하는 것이 자연스럽다. 이 모델에서는 텍스트 문장의 문맥화된 표현을 학습하는 BERT를 사용하였다. $x$와 $\tilde{x}$가 주어지면, BERT는 문맥화된 벡터의 sequence를 반환하는 Transformer이다:
\[v_{[\text{CLS}]}, v_{x_1}, ..., v_{x_r}, v_1, ..., v_{\tilde{x}_p} = \text{BERT}(x, \tilde{x})\]$ v_{[\text{CLS}]}$는 특수 토큰 $\text{[CLS]}$의 표현이다. 여기서 rating를 예측하기 위해 $\text{[CLS]}$ 벡터에 선형 레이어를 하나 추가했다:
\[\hat{y} = f(x, \tilde{x}) = W\tilde{v}_{[\text{CLS}]} + b\]$W$와 $b$는 각각 weight matrix와 bias이다. 위의 선형 레이어와 BERT parameter는 대략 수천 개의 예시를 사용하여 미세조정(fine-tuned)된다. Regression Loss로 다음을 쓴다.
\[l_{\text{supervised}} = \frac{1}{N} \Sigma^N_{n=1}\Vert y_i - \hat{y}\Vert^2\]이 접근법은 상당히 간단하지만, Section 5에서 WMT Metrics Shared Task 17-19에서 state-of-the-art 결과를 얻을 수 있음을 보인다. 하지만, 미세조정 BERT는 많은 양의 IID data를 필요로 하며, 이는 다양한 task와 모델의 변형에 일반화할 수 있는 평가 방법으로는 아주 이상적이지는 않다.
4. 합성 데이터에서 사전학습(Pre-Training on Synthetic Data)
이 접근법의 핵심 부분은 rating data에 미세조정하기 전 BERT를 “warm up”하기 위해 사전학습 기술을 사용했다는 것이다. 많은 양의 참조-후보 쌍 $(z, \tilde{z})$을 생성하여, 여러 어휘적 & 의미적 수준의 감독 signal를 multi-task loss를 사용하여 BERT를 학습시켰다. 실험이 보여주듯이, BLEURT는 이 단계 이후로 매우 성능이 좋아지며, 특히 데이터가 부족할 때에 더욱 그렇다.
어떤 사전학습 접근법이든지 데이터셋과 사전학습 task 뭉치가 필요하다. 이상적으로, 이러한 구조는 최종 NLG 평가 task(i.e., 문장 쌍은 비슷하게 분포되어야 하고 사전학습 signal는 사람의 판단과 연관되어 있어야 한다)와 비슷할 수밖에 없다. 안타깝게도, 우리는 우리가 미래에 평가할 NLG 모델에 접근할 수 없다.
따라서, 우리는 일반성을 위해 방법을 다음 3가지 요구사항으로 최적화했다:
- 참조 문장 집합은 반드시 크고 다양성을 가져야 하며, 이는 BLEURT가 다양한 NLG domain과 task를 처리할 수 있을 만큼 충분해야 한다.
- 문장 쌍은 매우 다양한 의미적, 구문론적, 의미적 차이점을 포함해야 한다.
- 사전학습 objective는 BLEURT가 식별할 수 있을 만큼 효과적으로 그 현상들을 잡아내야 한다.
아래 섹션들에서 상세히 설명한다.
4.1. 문장 쌍 생성(Generating Sentence Pairs)
BLEURT를 매우 다양한 문장에 노출시키기 위한 하나의 방법은 존재하는 문장 쌍 데이터셋(Bowman et al., 2015; Williams et al., 2018; Wang et al., 2019)을 사용하는 것이다. 이 데이터셋들은 다양한 출처의 연관된 문장들을 포함하지만 NLG 시스템이 만드는 오류와 변형을 잡아내지 못할 수 있다(생략, 반복, 터무니없는 대체 등). 대신 자동적 접근법을 선택하여, 이는 임의로 늘일 수 있고 또한 적은 비용으로 실행할 수 있다: 우리는 합성 문장 쌍 $(z, \tilde{z})$를 Wikipedia에서 가져온 문장에 180만 개의 부분 perturbing을 수행하여 얻었다. 여기서는 BERT에서 mask-filling, 역 번역, 단어를 임의로 빼는 세 가지 기술이 사용되었다. 이를 살펴보자.
Mask-filling with BERT:
BERT의 초기 학습 task는 토큰화된 문장에서 masked 토큰을 채우는 task이다. 이 기술은 Wikipedia 문장의 임의의 위치에 mask를 삽입한 후 언어 모델로 이를 채우는 과정이다. 따라서, 문장의 유창성을 유지하면서 어휘적 변형을 모델에 소개하였다. Masking 전략은 두 가지가 있는데, 문장의 임의의 위치에 mask를 만들거나, masked 토큰에 근접한 문장을 만드는 것이다. 더 자세한 내용은 부록 참조.
Backtranslation:
역 번역을 통해 문단과 문장 동요(perturbation)을 생성하였고, 이는 번역 모델을 사용하여 영어를 다른 언어로 번역했다가 다시 영어로 바꾸는 왕복 과정이다. 주 목표는 의미를 유지하는 참조 문장에 변형을 추가하는 것이다. 추가적으로, 역 번역 모델의 예측 실패한 것을 현실적 변형의 출처로 사용하였다.
Dropping words:
위의 합성 예시에서 단어를 무작위로 삭제하여 다른 예시를 만드는 것이 실험에서 유용하다는 것을 알아내었다. 이 방법은 BLEURT가 “병적인” 행동이나 NLG 시스템: 의미없는 예측, 문장 절단 등에 대비할 수 있게 한다.
4.2. 사전학습 signal(Pre-Training Signals)
다음 단계는 각 문장 쌍 $(z, \tilde{z})$과 사전학습 signal 집합 $\lbrace \tau_k \rbrace$ 을 늘리는 것이다. $\tau_k$는 사적학습 task $k$의 목표 벡터이다. 좋은 사전학습 signal는 매우 다양한 어휘적, 의미적 차이점을 잡아내야 한다. 이는 또한 얻기 쉬워야 하며, 따라서 이 접근법은 대량의 합성 데이터에도 크기를 늘려 사용할 수 있어야 한다. 다음 섹션에서는 표 1에 요약한 9가지 학습 task를 소개한다. 추가 구현 세부는 부록을 참조한다.
Automatic Metrics:
문장 BLEU, ROUGE, BERTscore와 연관하여 3가지 signal $\tau_{\text{BLEU}}$, $\tau_{\text{ROUGE}}$, $\tau_{\text{BERTscore}}$를 만들었다. precision을 사용하며 뒤의 2개는 recall과 F-score를 사용한다.
Backtranslation Likelihood:
이 signal의 아이디어는 존재하는 번역 모델을 의미적 동등을 측정하는 도구로 사용하는 것이다. 문장 쌍 $(z, \tilde{z})$이 주어지면, 이 학습 signal은 $\tilde{z}$가 그 length로 정규화되었을 때 $z$의 역 번역일 확률 $P(\tilde{z}\vert z)$를 측정한다.
아래 식의 첫 번째 항을 영어 문장 $z$을 조건으로 하여 프랑스어 문장 $z_{fr}$일 확률을 할당하는 번역 모델이라 하자.
두 번째 항은 프랑스어 $\rightarrow$ 영어에 대한 번역 모델이다.
만약 $\vert \tilde{z} \vert$가 $\tilde{z}$ 안의 토큰의 수라면, 점수를 다음과 같이 정의한다.
\[\tau_{en-fr, \tilde{z} \vert z} = \frac{\log P(\tilde{z} \vert z)}{\vert \tilde{z} \vert} , P(\tilde{z} \vert z) = \sum_{z_{fr}} P_{fr \rightarrow en}(z \vert z_{fr}) \ P_{en \rightarrow fr}(z_{fr} \vert z)\]모든 가능한 프랑스어 문장에 대해 합을 계산하는 것은 불가능하기 때문에, 합은 다음과 같이 근사한다:
\[\text{assume}: P_{en \rightarrow fr}(z_{fr} \vert z) \approx 1\] \[P(\tilde{z} \vert z) \approx P_{fr \rightarrow en}(\tilde{z} \vert z^*_{fr}) , where \ z^*_{fr} = \text{argmax} P_{en \rightarrow fr}(z_{fr} \vert z)\]$P(z \vert \tilde{z})$를 계산하는 것은 자명하게도 과정을 역으로만 하면 되므로 영어 $\leftrightarrow$ 독일어와 영어 $\leftrightarrow$ 프랑스어 간 다음 4개의 사전학습 signal을 만들었다.
\[\tau_{\text{en-fr}, z \vert \tilde{z}}, \ \tau_{\text{en-fr}, \tilde{z} \vert z}, \ \tau_{\text{en-de}, z \vert \tilde{z}}, \ \tau_{\text{en-de}, \tilde{z} \vert z}\]Textual Entailment:
signal $\tau_{\text{entail}}$은 $z$가 $\tilde{z}$를 수반하는지 혹은 상충하는지를 분류기를 통해 표현한다. 이와 관련하여 수반 데이터셋 MNLI에서 미세조정된 BERT를 사용하여 가능성을 수반(Entail), 모순(Contradict), 중립(Neutral)으로 분류하였다.
Backtranslation flag:
signal $\tau_{\text{backtran_flag}}$는 perturbation이 역 번역에 의해 생성되었는지 혹은 mask-filling에 의해 생성되었는지를 나타내는 Boolean 값이다.
4.3. 모델링(Modeling)
각 사전학습 task에서, 모델은 회귀 또는 분류 loss를 사용한다. 그리고 task 수준의 loss의 가중합을 구한다.
$\tau_k$를 각 task에 대한 목표 벡터라 하자(Entail, Contradict, Neutral, precision, recall, ROUGE F-score 등).
만약 $\tau_k$가 회귀 task이면, loss는 $\vert \tau_k \vert $가 $\tau_k$의 차원이고 $\vert \hat{\tau}_k\vert$가 [CLS] embedding에 선형 레이어를 붙여 계산한 것이라면 $\ell_2$ loss는 다음과 같다.
만약 $\tau_k$가 분류 task이면, 각 class $c$에 대한 logit을 예측하기 위한 선형 레이어를 분리하였고 multi-class cross-entropy loss를 사용하였다. 사전학습 손실함수는 다음과 같다.
\(\ell_{\text{pre-training}} = \frac{1}{M} \sum^M_{m=1} \sum^K_{k=1} \gamma_k \ell_k (\tau^m_k, \hat{\tau}^m_k)\) \(\text{where} \ \hat{\tau}_{kc} = W_{\tau_{kc}}\tilde{v}_{[\text{CLS}]} + b_{\tau_{kc}}\)
- $\tau^m_k$: 예시 $m$에 대한 목표 벡터
- $M$: 합성 예시의 숫자
- $\gamma_k$: grid search로 얻은 초모수 가중치(hyper-parameter weights)
보다 자세한 것은 부록을 참조한다.

5. 실험(Experiments)
번역과 data $\to$text task에서 실험 결과를 적는다. 먼저, BLEURT를 이미 존재하는 텍스트 생성 평가방법과 WMT Metrics Shared Task의 최근 3년간에 대해 평가한다. 그리고 WMT17에 기반한 일련의 합성 데이터에 따라 움직이는 품질 이탈(drifts)에 대한 BLEURT의 강건성을 평가한다. 또 WebNLG 2017 Challenge Dataset와 다른 task에 적용시키는 BLEURT의 능력을 평가한다. 마지막으로, ablation을 통해 각 사전학습 task이 기여하는 바를 측정한다.
Our Models:
모든 BLEURT 모델은 다음 3단계를 거친다:
- BERT 모델의 기본 사전학습
- 합성 데이터에 대한 사전학습
- task-specific rating에 대한 미세조정(번역 그리고/혹은 data $\to$ text)
BLEURT는 2가지 버전이 있다.
- BLEURT: BERT-Large uncased 기반(24 layer, 1024 hidden units, 16 heads)
- BLEURTbase: BERT-Base uncased 기반(12 layer, 768 hidden units, 12 heads)
batch size는 32, learning rate는 1e-5, 사전학습에 80만 step, 미세조정에 4만 step을 적용하였다. 더 자세한 사항은 부록 참조.
5.1. WMT Metrics Shared Task
Datasets and Metrics:
WMT Metrics Shared Task의 2017-2019년, to-English 언어 쌍 데이터를 사용하였다. 각 연도에 대해, 공식 WMT test set(사람의 평가와 같이 뉴스 도메인에서 얻은 수천 개의 문장 쌍으로 구성)을 사용하였다.
training set은 5360, 9482, 147691개의 예시가 있다. 2018년과 2019년의 test set은 더 noise가 많은데, 좀 더 낮은 상관관계를 보인다.
자동화된 평가 방법과 인간 평가와 일치하는 정도를 평가한다. 각 연도에 대해, Kendall’s Tau $\tau$(실험 간 일관성을 위해)와 공식 WMT 평가(완전성을 위해)를 둘 다 사용하였다. 공식 WMT 평가방법은 Pearson’s correlation이나 DARR라 불리는 Kendall’s Tau의 강건한 변형이며, 부록에서 볼 수 있다. 모든 숫자는 벤치마크의 구현에서 가져왔다. 결과는 전체적으로 공식 결과와 일관되지만 2018년과 2019년에서 약간의 차이를 발견하였고, 표에서 확인할 수 있다.
Models:
4가지 버전이 있다: BLEURT, BLEURTbase, BLEURT -pre, BLEURTbase -pre. 첫 2개는 BERT-large와 BERT-base에 기반하였다. 뒤 2개는 사전학습 단계를 생략하고 바로 WMT ratings에 미세조정한 것이다. WMT shared task의 각 연도의 작년 test set을 training과 validation set으로 사용하였다. 이는 부록에서 더 자세히 설명한다.
BLEURT를 shared task의 다른 후보 데이터와 자동화된 평가방법과 비교하였다. 전자의 경우에는 각 연도의 최고 성능 평가방법인 chrF++, BEER, Meteor++, RUSE, Yisil, ESIM, Yisil-SRL를 사용하였다. 모든 후보는 같은 WMT 학습 데이터와 추가적으로 존재하는 문장 또는 token embedding을 사용하였다. 후자의 경우에는 Moses sentenceBLEU, BERTscore, MoverScore를 사용하였다. BERTscore에 대해서는 공정성을 위해 BERT-large uncased 모델을, 완전성을 위해 roBERTa를 사용하였다. MoverScore는 WMT 2017의 scripts를 사용하여 평가하였다.
Results:
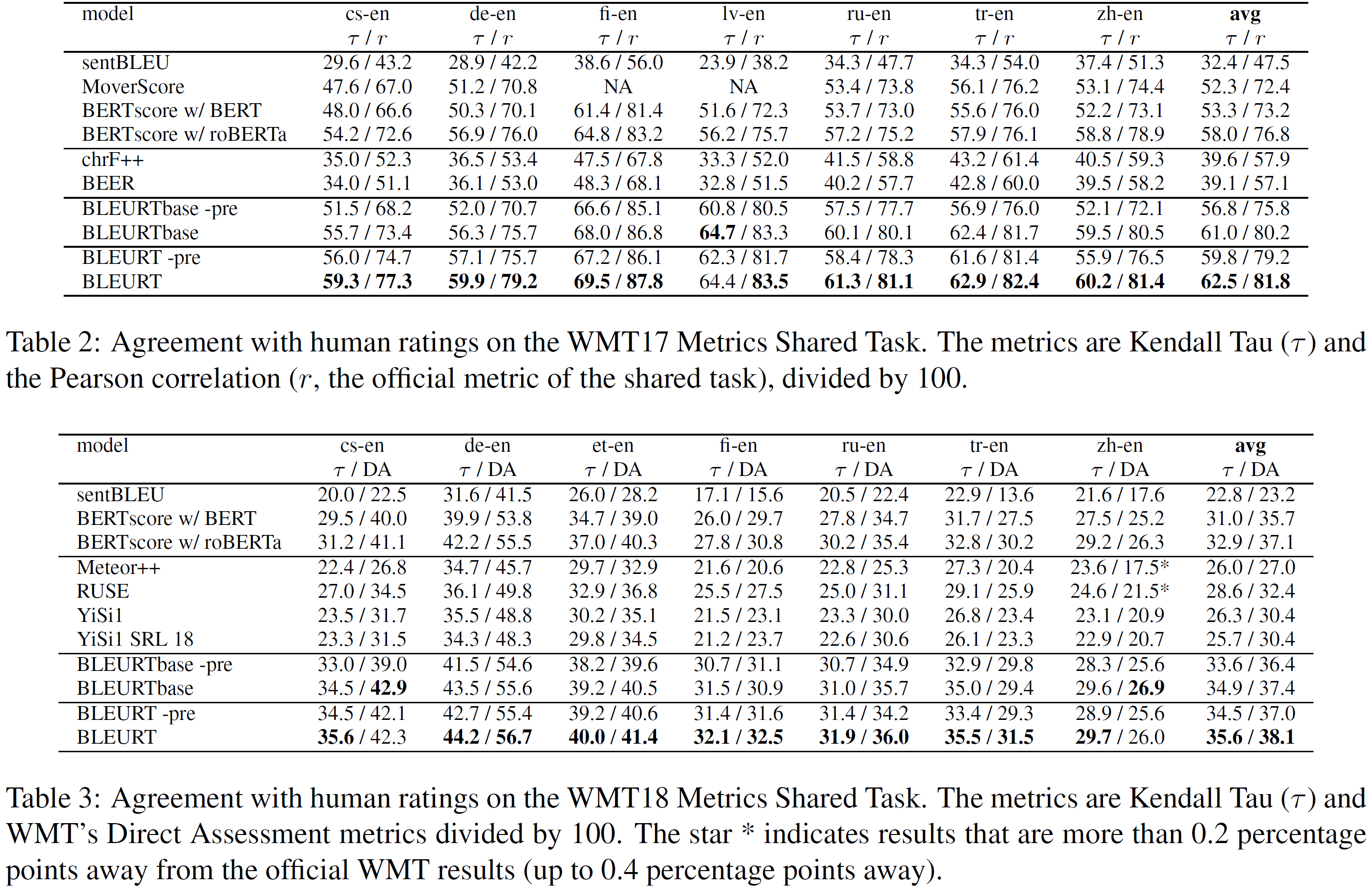
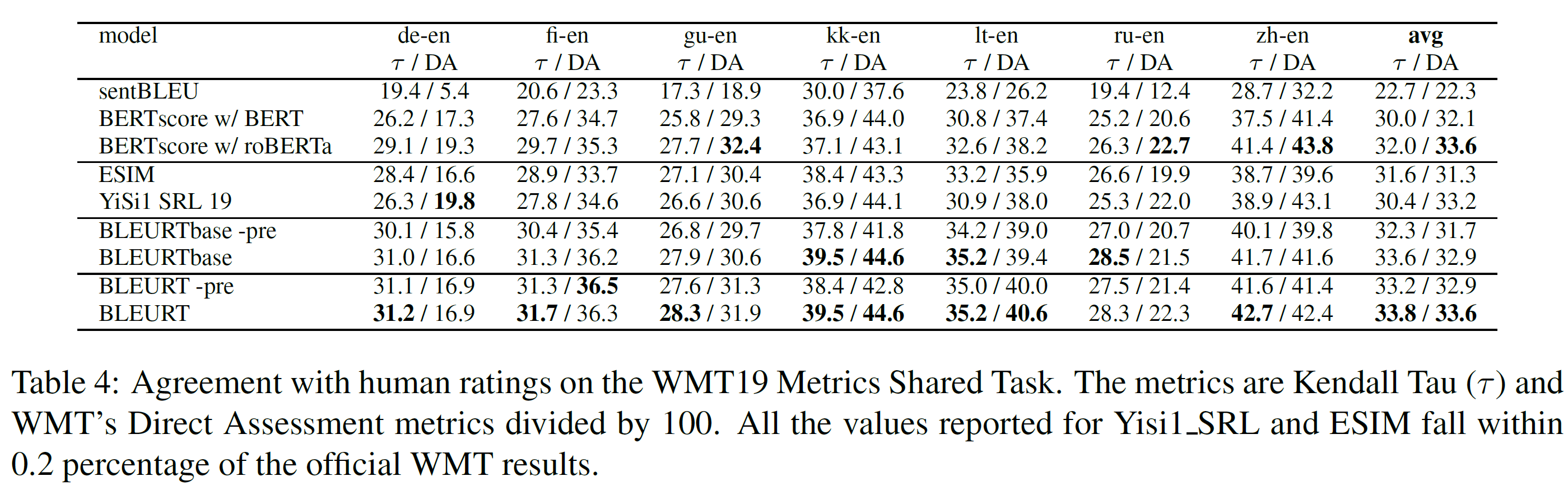
표 2~4에서 볼 수 있다. 2017년과 2018년에서는 BLEURT-based 평가가 각 언어 쌍에서 다른 벤치마크를 압도한다. 2019년에서도 Kendall’s Tau에서 모든 언어 쌍에 대해 최고의 결과를, DARR에서 7개 중 3개에서 최고의 결과를 냈다는 점에서 BLEURT와 BLEURTbase 역시 경쟁력이 있다.
기대한 대로, BLEURT는 대부분의 경우 BLEURTbase를 압도한다. 사전학습은 일관되게 BLEURT와 BLEURTbase의 성능을 높인다.
2017년에서 가장 큰 효과는 BLEURTbase(zh-en)에서 7.4 Kendall Tau 점수를 더 얻었다는 것이다. 이 효과는 2018년과 2019년에서는 더 약하다(tr-en, 2018년에서 2.1점). 이 차이는 2017년에 사용된 학습 데이터는 이후 연도보다 더 적기 때문이며, 사전학습이 더 도움이 되었기 때문이라 설명할 수 있다. 일반적으로 사전학습은 BERT-large보다 BERT-base에서 더 큰 효과를 가지는데, 사실, 사전학습을 포함한 BLEURTbase는 포함하지 않을 때 BLEURT보다 더 좋은 경우도 있었다.
Takeaways:
사전학습은 일관적으로 성능 향상을 가져다주며, 특히 BLEURT-base에서 그렇다. BLEURT는 WMT Metrics Shared task의 모든 연도에서 가장 좋은 성능을 보인다.
5.2 Robustness to Quality Drift
사전학습이 품질 이탈(quality drift)에 대한 BLEURT의 강건성을 증가시킨다는 것은 추론 비중이 증가하는 일련의 task를 구성함으로써 평가하였다. 모든 실험은 WMT Metrics Shared Task 2017에 기반하였다. 이 rating이 특별히 믿을 만하기 때문이다.
Methodology:
WMT Metrics shared task의 예시들을 부차표본추출하여 저평가된 번역을 학습으로 고평가된 번역을 테스트로 하여 난이도가 점점 높아지는 데이터셋들을 생성하였다. 중요한 parameter는 skew factor $\alpha$인데 이는 학습 데이터가 얼마나 좌편향되었고 테스트 데이터가 얼마나 우편향되었는지를 측정한다. 학습 데이터는 $\alpha$가 커질수록 줄어든다. 가장 극단적인 경우인 $\alpha=3.0$의 경우 학습 데이터로는 전체(5344개)의 11.9%만 사용한다. 더 자세한 건 부록 참조.
BLEURT는 사전학습을 한 것과 안 한 것으로 나누어 Moses sentBLEU와 BERTscore와 비교한다. BERT-large uncased를 기본으로 사용한다.
Results:
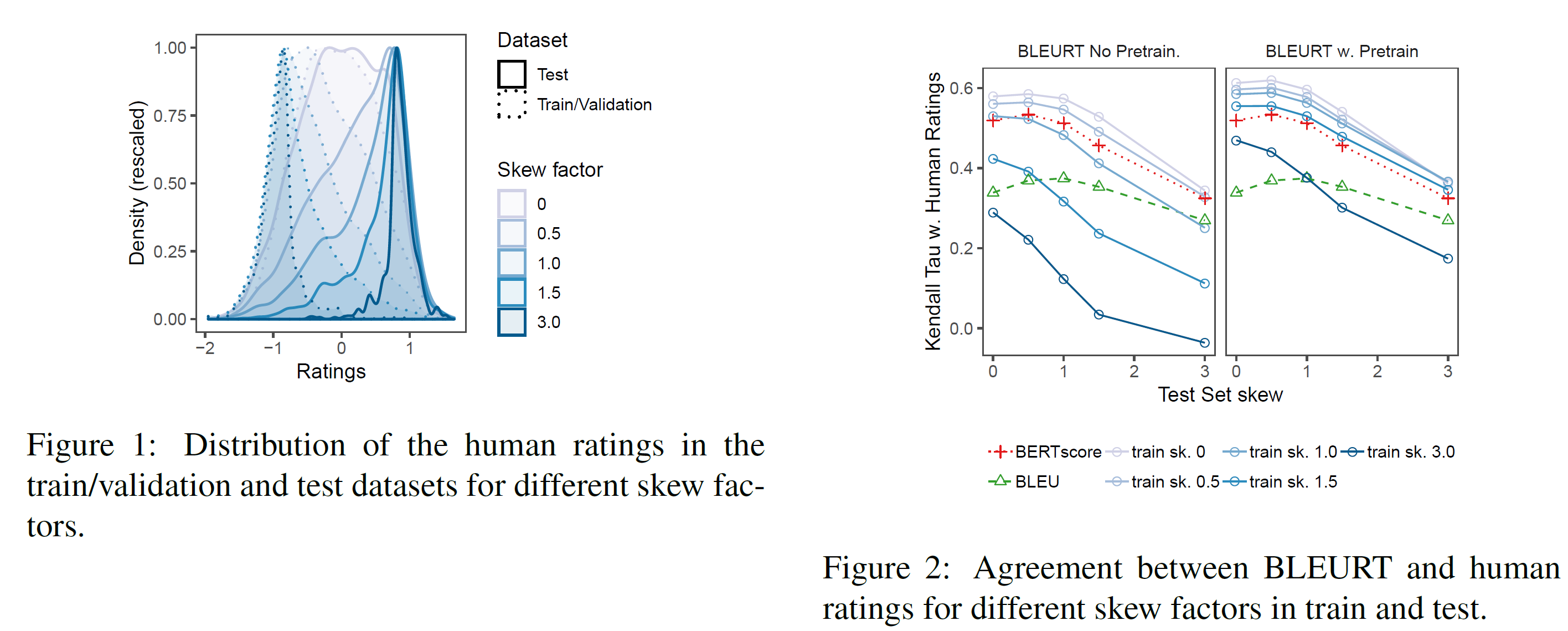
그림 2는 학습/테스트 데이터의 skew를 독립적으로 변화시키면서 측정한 BLEURT의 성능을 보여준다. 첫 번째 관찰할 점은 test skew가 증가할수록 모든 평가방법의 일치성이 하락한다는 것이다. 이 효과는 2019 WMT Metrics 보고서에서도 이미 보고되었다. 일반적인 설명은 rating이 가까워질수록 task가 어려워진다는 것이고, “good* 시스템을 그냥 평가하는 것보다 “good”과 “bad”를 구별하는 것이 더 쉽다는 것이다.
학습 skew는 사전학습이 없는 BLEURT에 치명적인 효과를 가진다: $\alpha=1.0$에서 BERTscore보다 낮으며, $\alpha \ge 1.5$인 경우에는 sentBLEU보다 낮다. 사전학습된 BLEURT는 훨씬 더 강건하다: 유일하게 낮아지는 때는 가장 극단적인 drift(학섭 데이터는 부정확한 번역, 테스트할 때에는 훌륭한 번역)가 존재하는 $\alpha=3.0$일 때 뿐이다.
Takeaways:
사전학습은 BLEURT의 quality drift에 대한 강건성을 크게 증가시킨다.
5.3 WebNLG Experiments
이 섹션에서는, data $\to$ text 데이터셋(WebNLG Challenge 2017)에서 나온 3가지 task에 대한 BLEURT의 성능을 평가한다. 목표는 학습 데이터가 제한되었을 때 BLEURT의 새로운 task에 대한 적응능력을 평가하는 것이다.
Dataset and Evaluation Tasks:
WebNLG challenge 벤치마크 시스템은 1~5개의 RDF triple 집합의 객체(예: 빌딩, 도시, 예술가 등)에 대한 자연어 설명을 생성한다. 223개의 입력에 대해 9개의 시스템에 인간 평가를 수행하여 4677 문장 쌍에 대한 데이터가 있다. 각 입력당 1~3개의 참조 설명이 있다. 각 제출은 의미, 문법, 유창성 측면에서 평가된다. ratings의 각 종류는 독립된 모델링 task로 여겨진다.
데이터는 train/test 집합 사이에 자연스러운 구분이 없으므로 여러 전략을 통해 실험하였다. 학습에는 0~50%의 데이터를 사용하고, 다른 일반화 가능 범위를 평가하기 위해 평가할 시스템과 RDF 입력을 모두 분리하였다.
Systems and Baselines:
BLEURT -pre -wmt는 WebNLG ratings에서 직접 학습된 일반적인 BERT-large uncased이며, BLEURT -wmt는 합성 데이터에서 처음 사전학습되어 WebNLG 데이터에서 미세조정된 것이다. BLEURT는 1) 합성 데이터, 2) WMT 데이터, 3) WebNLG 데이터에서 차례로 학습된다. 어떤 샘플이 여러 참조에서 올 때, BLEURT를 각 참조에서 실행시켜서 가장 높은 점수만을 기록한다.
4가지의 기준 모델은 각각 BLEU, TER, Meteor, BERTscore이다. 첫 3개는 WebNLG competition organizers에 의해 계산된다. 마지막 하나는 공정한 비교를 위해 BERT-large uncased 모델을 사용해 직접 평가하였다.
Results:
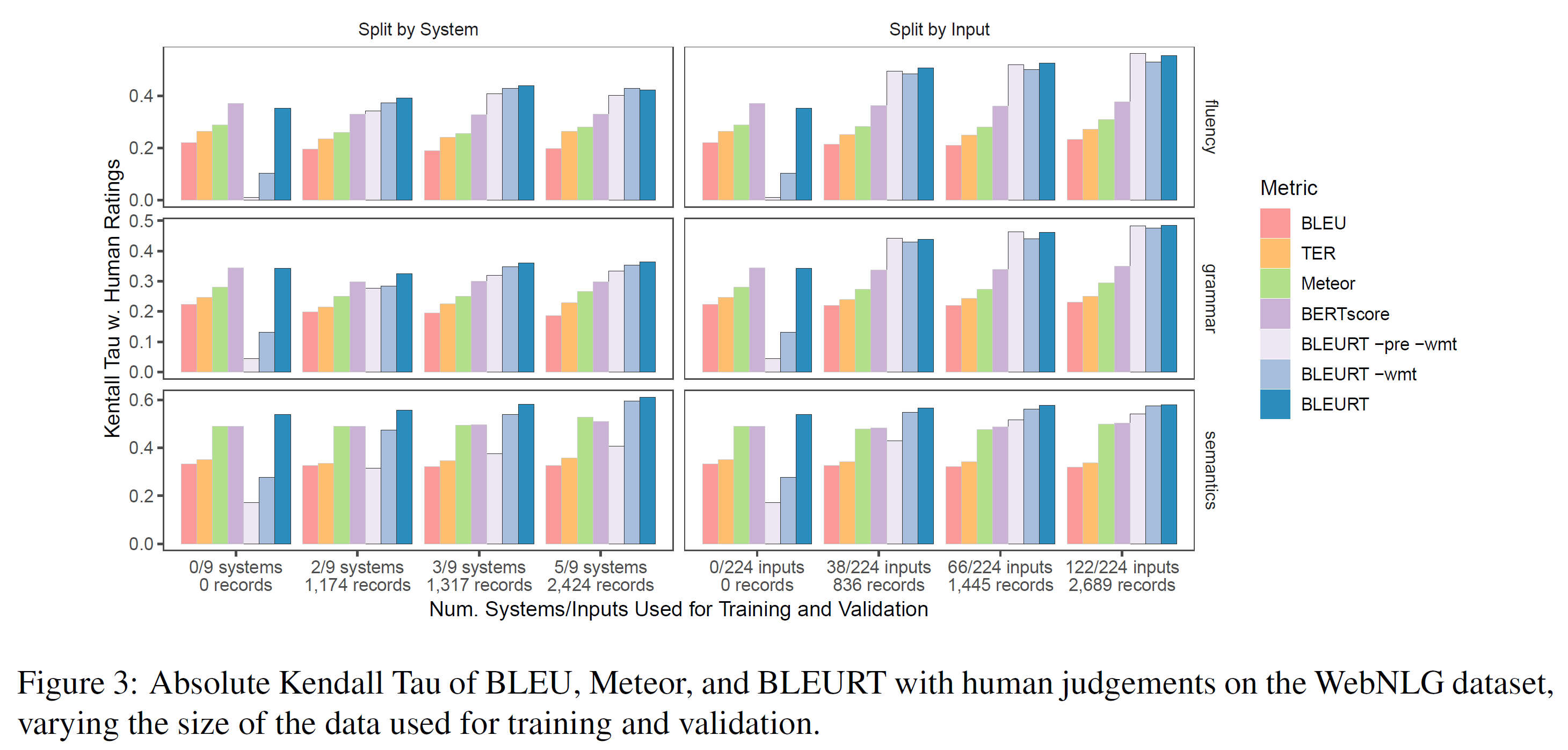
그림 3은 학습에 할당되는 데이터의 비율의 변화에 따라 평가방법과 인간 평가 사이의 상관관계를 보여준다. 더 많이 사전학습된 BLEURT가 더 잘 적응함을 볼 수 있다. vanilla BERT 접근법인 BLEURT -pre -wmt는 대부분의 task에서 기준 모델을 압도하려면 WebNLG 데이터의 1/3이 필요하며, 그러고도 의미론적인 측면에서 여전히 뒤처진다.
이와 대조적으로, BLEURT -wmt는 836개 정도의 샘플을 사용한 경우에 경쟁력이 있으며, BLEURT는 미세조정을 하지 않았을 때 BERTscore와 비교할 만하다.
Takeaways:
사전학습 덕분에 BLEURT는 새로운 task에 빠르게 적응할 수 있다. BLEURT는 합성 데이터와 WMT 데이터에 총 2번 사전학습 함으로써 학습 데이터 없이도 모든 task에서 괜찮은 결과를 보여 준다.
5.4 Ablation Experiments
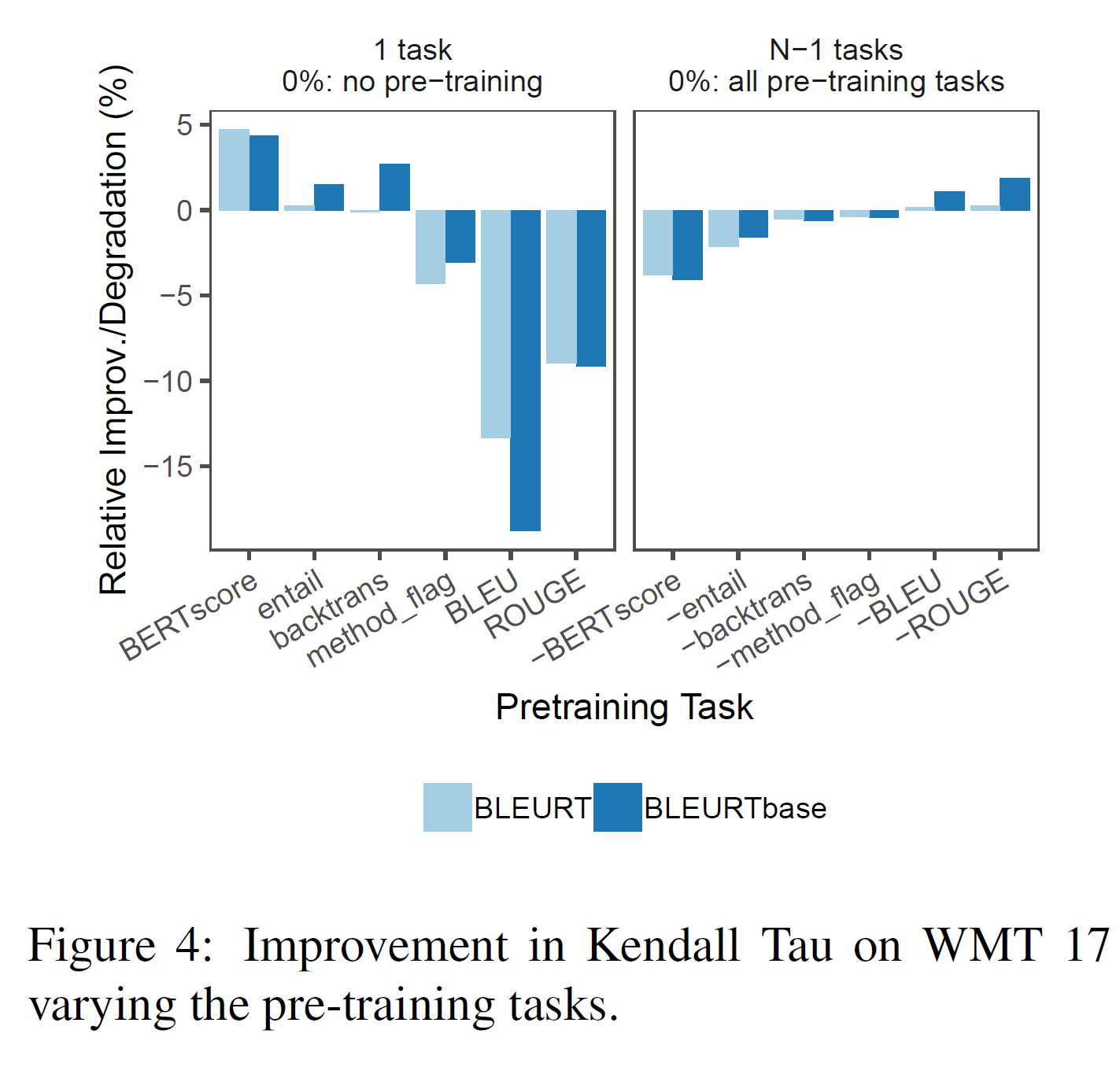
그림 4는 WMT 2017에 진행한 ablation 실험을 보여주며, 각 사전학습 task의 상대적 중요성을 보여준다. 왼쪽에서는 BLEURT이 하나의 task에 대해 사전학습된 것과 아닌 것의 차이를 보여준다. 오른쪽은 full BLEURT와 하나를 제외한 모든 task에 사전학습된 BLEURT를 비교한다. BERTscore, entailment, 역 벅역 score에 사전학습하는 것은 성능 향상을 이끌어낸다(비슷하게, 이를 없애는 것은 BLEURT의 성능을 낮춘다). 반대로, BLEU와 ROUGE는 음의 영향력을 갖는다. 높은 품질의 signal 하에서 사전학습하는 것은 BLEURT에 도움이 되지만, 사람의 평가와 낮은 상관관계를 갖는 평가방법은 모델의 성능을 떨어뜨릴 수 있다.
6. 관련 연구(Related Work)
WMT shared metrics competition은 많은 학습된 평가방법의 생성에 영감을 주었다. 최근 MoverScore와 같은 다른 평가방법도 소개되었는데, 이는 문맥적 embedding과 Earth Mover’s Distance를 결합한 것이다. 우리는 head-to-head 실험을 제공하여 실험과 최고 성능의 평가방법을 비교하였다. 다른 접근법은 품질을 직접 추정하지는 않지만, 추출이나 질답을 대안으로 쓸 수 있다. 이는 이 연구에 상호 보완을 할 수 있다.
평가를 위해 BERT를 사용하는 최근 연구들이 있다. BERTScore는 BLEU의 hard n-gram overlap을 BERT embedding을 사용하여 soft-overlap으로 대체하였다. 이는 본 연구 전체에서 사용되었다. Bertr과 YiSi는 유사성을 잡아내기 위해 역시 BERT embedding을 사용하였다. SumQE는 품질 추정을 위해 BERT를 미세조정했다.
이 논문의 초점은 다르다$-$이 논문에서는 전통적인 IID 실험 setup에서 state-of-the-art뿐만 아니라 학습 데이터가 분포를 벗어나거나 부족한 경우에서도 평가방법을 학습시켰다. NLG 문맥에서 사전학습과 추론의 영역을 탐사하였다.
이전 연구들은 참조가 없는 평가를 위해 noising을 사용하였다. Noisy한 사전학습은 의역과 같은 다른 task를 위해 제안되었지만 일반적으로 합성 데이터에는 그렇지 않았다. 의역과 perturbation으로 합성 데이터를 생성하는 것은 일반적으로 적대적 예시를 생성하는 데 사용되며, 이는 (이) 연구의 파향선이다.
7. 결론(Conclusion)
영어를 위한 참조 기반 텍스트 생성 평가방법인 BLEURT를 제안하였다. 이 평가방법은 end-to-end 방식이미 때문에, BLEURT는 높은 정확도로 인간 평가를 모델링할 수 있다. 더욱이, 사전학습은 특히 도메인과 품질 이탈이 있는 경우에도 강건성을 가진다. 추후 연구 방향은 다중 언어 NLG 평가를 포함하며, 사람과 분류기 모두를 포함하는 혼합 방식이 될 것이다.
Acknowledgements
언제나 있는 감사의 인사
Refenrences
논문 참조. 많은 레퍼런스가 있다.
Appendix A Implementation Details of the Pre-Training Phase
이 섹션에서는 본문에서 기술된 사전학습 기술에 대한 상세를 설명한다.
A.1. Data Generation
Random Masking:
2개의 masking 전략을 사용했다. 두 경우 모두 15개의 mask를 생성한다.
- 문장에서 임의의 단어를 선택하여 mask(각 토큰당 1개)로 대체한다. 따라서 mask가 문장에 산재되어 있다.
- 두 번째 전략은 연속적인 sequence를 생성한다: 처음 위치 $s$에서 길이 $l$만큼을 균등분포로 선택하여 그 안의 모든 token을 mask로 대체한다.
언어모델을 한 번 실행시키고 각 위치에서 가장 (원래 단어였을 것 같은) token을 선택하는 대신, 크기 8의 beam search를 사용했다. 이는 , , ,와 같은 반복적인 sequence를 피하고 일관성을 갖도록 강제한다.
Backtranslation:
영어-프랑스어를 고려한다.
정방향 번역 모델과 역방향 번역 모델이 주어졌을 때, $\tilde{z}$를 다음과 같이 생성한다:
\[\tilde{z} = \text{argmax}_{z_{en}} P_{fr \to en}(z_{en} \vert z^*_{fr})\] \[where \ z^*_{fr} = \text{argmax} P_{fr \rightarrow en}(z_{fr} \vert z)\] \[\text{forward translation model: } P_{en \rightarrow fr}(z_{fr} \vert z_{en})\] \[\text{backward translation model: } P_{fr \rightarrow en}(z_{en} \vert z_{fr})\]번역 모델로는 tensor2rensor framework로 영어-독일어를 사용하여 학습된 Transformer를 사용했다.
Word dropping:
합성 예시 $(z, \tilde{z})$가 주어질 때 $\tilde{z}$에서 임의로 단어들을 빼서 $(z, \tilde{z}^{‘})$ 쌍을 생성한다. 탈락시키는 단어의 수는 문장 길이를 최대치로 균등하게 정했다. 이러한 변형을 이전 방법과 같이 생성된 데이터의 30%에 적용하였다.
A.2 Pre-Training Tasks
이제 사전학습을 위해 사용한 signal의 상세를 살펴본다.
Automatic Metrics:
표에서 보았듯이, BLEU, ROUGE, BERTscore 3가지 signal을 사용하였다.
- BLEU에 대해서는, 원본 Moses
SENTENCEBLEU구현을 사용, Moses tokenizer와 기본 parameter를 사용하였다. - ROUGE에 대해서는,
ROUGE-N의 seq2seq 구현을 사용하였다. - BERTscore는 BERT-large uncased에 기반한 custom 구현을 사용하였다.
ROUGE와 BERTscore는 precision, recall, F-score 3개의 점수를 반환한다. 이 3가지를 모두 사용한다.
Backtranslation Likelihood:
custom Transformer 모델을 사용하여 tensor2tensor framework를 사용, 영어$\leftrightarrow$프랑스어에서 학습시켜 모든 loss를 계산하였다.
Normalization:
모든 회귀 label은 학습 전 정규화되었다.
A.3 Modeling
Setting the weights of the pre-training tasks:
BLEURT의 성능을 WMT 17의 validation set에서 최적화하는 $\gamma_k$를 grid search로 찾아 정했다. grid의 크기를 줄이기 위해 같은 weight를 공유하는 다음 사전학습 그룹을 만들었다.
\[\tau_{\text{BLEU}}, \tau_{\text{ROUGE}}, \tau_{\text{BERTscore}}\] \[\tau_{\text{en-fr}, z \vert \tilde{z}}, \ \tau_{\text{en-fr}, \tilde{z} \vert z}, \ \tau_{\text{en-de}, z \vert \tilde{z}}, \ \tau_{\text{en-de}, \tilde{z} \vert z}\] \[\tau_{\text{entail}}, \tau_{\text{backtran\_flag}}\]Appendix B Experiments–Supplementary Material
B.1 Training Setup for All Experiments
BERT’s의 기본 설정을 따라 Adam optimizer, learning rate 1e-5, batch size 32를 사용했다. 다른 설정은
- 8만 training step
- 4만 step의 미세조정
학습과 평가를 병행하여 매 1500 step마다 checkpoint를 저장, 가장 괜찮은 validation 결과를 보인 것을 최종 선택한다.
하드웨어는 학습에 Google Cloud TPUs v2, 평가에는 Nvidia Tesla V100 가속기를 사용했다. 코드는 Python 2.7과 Tensorflow 1.15 버전이다.
B.2 WMT Metric Shared Task
Metrics.
평가방법은 여러 연도에 걸쳐서 평가 시스템을 비교하는 데 사용된다. organizer는 2017년의 모든 부분에 대해 정규화된 인간 평가와 연관한 Pearson’s correlation을 사용한다. 그리고 “DARR”이라 칭하는 Kendall’s Tau의 개조 버전을 2018년과 2019년의 인간 평가와의 연관성을 비교한다.
organizer는 같은 참조 부분에 대한 모든 번역을 모아서 가능한 모든 쌍 조합을 찾아(translation1, translation2) 100점 만점에 25점 이하인 “비슷한” 점수를 가진 모든 쌍을 제거했다.
그리고 남은 쌍에 대해, 번역이 인간 평가와 후보 평가방법 모두에서 최고점을 갖는 것을 제일 좋은 번역이라 한다.
|Concordant|를 NLG 평가방법이 ‘agree’하는 쌍의 수라 하고 |Discordant|를 ‘disagree’하는 쌍의 수라 할 때 점수는 다음과 같다.
25점 필터의 아이디어는 WMT 2018과 2019의 평가 데이터가 noisy하기 때문에 평가를 좀 더 강건하게 하는 것이다.
Kendall’s Tau는 이상적이지만, 필터를 사용하지 않는다.
Training setup.
train/validation set을 분리하기 위해 데이터셋에 누수가 없는 고정 비율을 쓰는 방법을 사용했다(train, validation 예시는 같은 출처를 공요한다). 2017년과 2018년의 validation의 10%를, 2019년의 5%를 사용했다.
여기서 모든 validation data에서 가장 높은 Kendall Tau 점수를 낸 모델을 결과로 표시하였다. 각 사전학습 task에 연관된 weights는 WMT 2017년의 train/validation setup을 사용하여 grid search를 통해 설정하였다.
Baselines.
3개의 평가방법(sentenceBLEU의 Moses 구현, BERTscore, MoverScore)을 사용하였고 이는 모두 온라인으로 사용 가능하다. sentenceBLEU를 계산하기 전 Moses tokenizer를 참조와 후보 segment에서 실행하였다.
B.3 Robustness to Quality Drift
Data Re-sampling Methodology:
training/test set을 분리하여 샘플링하였다. 10개의 동일한 크기의 bin으로 데이터를 나누고, train/test 에 대해 각각 $1\over B^{\alpha}$와 $1\over (11-B)^{\alpha}$의 확률로 샘플링하였다. $B$는 1~10의 bin 번호, $\alpha$는 미리 정의된 skew factor로 drift를 조절한다. 0은 아무 영향이 없고(ratings은 0을 중심으로 함), 3.0은 극단적인 차이(difference)를 만든다. $\alpha$가 증가함에 따라 데이터셋의 크기는 줄어든다: 5344개의 training 샘플에 대해 각각 다음과 같은 설정으로 실험하였다.
| alpha | dataset ratio |
|---|---|
| 0.5 | 50.7% |
| 1.0 | 30.3% |
| 1.5 | 20.4% |
| 3.0 | 11.9% |
B.4 Ablation Experiment–How Much Pre-Training Time is Necessary?
사전학습 시간과 downstream 정확도의 관계를 이해하기 위해, 사전학습 횟수가 다른 여러 버전의 BLEURT를 학습시켜 WMT17 데이터에 미세조정시켰다. 아래 그림이 그 결과를 보여준다. 첫 40만 step에서 가장 많은 발전이 있고, 이는 합성 데이터셋의 2 epoch에 해당한다.