
PCREC(Pre-training Graph Neural Network for Cross Domain Recommendation) 설명
28 Nov 2021 | Machine_Learning Recommendation System Paper_Review목차
이번 글에서는 GNN을 활용하여 CDR(Cross Domain Recommendation) 문제를 풀어본 논문에 대해서 다뤄보도록 하겠습니다. 논문 원본은 이 곳에서 확인할 수 있습니다. 본 글에서는 핵심적인 부분에 대해서만 살펴보겠습니다.
Pre-training Graph Neural Network for Cross Domain Recommendation 설명
1. Introduction
추천 시스템을 만든다고 할 때 cold start problem과 data sparsity issue는 흔히 겪는 문제입니다. 이를 해결하기 위해 cross-domain recommendation를 떠올려 볼 수 있는데, 이에 관하여 평소의 카드 결제 기록을 바탕으로 어떤 커머스 샵의 상품을 추천해주는 시스템을 예로 들 수 있겠습니다.
만약 2가지 domain이 존재한다고 하면 대부분의 기존 연구들은 이를 결합하여 한 번에 학습시키는 형태를 보여왔는데, 이 경우 학습된 임베딩이 편향된 정보를 포함하고 있는 source domain에 의해 크게 영향(dominated) 받을 수 있습니다.
이러한 문제를 해결하기 위해 본 논문에서는 PCRec 이라는 방법론을 제시하고 있습니다. 설명을 읽어보면 아시겠지만 구조 자체는 어렵지 않고 많이 본 듯한 느낌이 듭니다. 논문 내에서 서술된 내용 중에서 인사이트를 얻을 수 있는 부분에 집중하면 더욱 좋을 것 같습니다.
기본적으로 CDR 에서는 정보가 source domain에서 target domain으로 전달됩니다. CDR의 핵심 아이디어는 두 도메인에 있는 common user를 활용하여 관련된 정보를 전달하는 것인데, 이는 2가지 모델링 방법으로 구체화할 수 있습니다.
source domain의 user 정보를 target domain에서 보조적인 정보로 활용하는 것이 첫 번째이고, 두 domain에서 공유가능한 parameter를 jointly train하는 것이 두 번째 방법입니다. 최근의 연구 중에서는 이 2가지 방법을 결합한 형태도 존재한다고 합니다. 그런데 이러한 방법을 적용할 때 생각해야 할 것이, 꼭 source domain이 우리가 target domain에서 풀고자 하는 예측 목표와 관련이 깊다고 말하기 어려울 수도 있다는 것입니다. 그리고 만약 source domain이 target domain에 대해 dominant bias를 갖고 있다면 이는 성능 저하의 주요 요인이 될 수 있습니다.
따라서 CDR을 잘 해내기 위해서는 우리는 반드시 아래 2가지를 동시에 달성해야 합니다.
- 정보를 효과적으로 전달할 것
- source domain에서 발생하는 편향으로부터 target domain에서의 예측을 보호할 것
pre-trained model에서 획득한 임베딩이 우리가 전달해야 할 정보라고 생각할 수 있겠습니다. 그리고 이 정보가 target domain에서 도움이 될 수 있도록 이를 fine-tuning 하는 작업이 수반되어야 할 것입니다.
본 논문에서는 pre-train 과정에서 graph structural information을 사용하고 이 때 학습은 SSL(Self-Supervised Learning)의 형태로 이루어집니다. query node가 존재할 때 이 node와 positive/negative 관계를 맺고 있는 node들을 추출한 뒤 각각의 pair에 대해 contrasive learning을 적용하면 됩니다. 이 아이디어는 이전 여러 연구에서도 자주 사용되었습니다.
fine-tuning의 본체가 될 모델로 Matrix Factorization을 사용하였는데, 본 논문은 이 간단한 모델이 사실 LightGCN과 같은 좀 더 복잡한 모델보다 더 나은 성능을 보여주었다고 여러 차례 강조하고 있습니다.
2. Related Work
cross-domain recommendation과 contrasive learning의 개념에 대해 보충 설명하고 있는 부분입니다.
본 논문에서 제시된 방법론은 user/item relevance에 집중하는 embedding-based transfer 방법을 취하고 있다는 점만을 기록하며, 나머지 부분에 대해서는 논문을 직접 참고하길 바랍니다.
3. Proposed Model
A. Preliminary
source/target domain graph를 각각 $\mathcal{G}^s, \mathcal{G}^t$ 라고 표기합니다. 학습을 진행하기 위해 각 node에 대해 r-ego network에서 context 정보를 추출한다고 하는데, 이는 그냥 r-hop neighbor까지 subgraph를 추출한다고 생각하시면 됩니다. node $u$ 에 대해 subgraph를 추출했다고 하면 이는 $\mathcal{S}_u$ 라고 표기합니다.
B. Pre-training on Source Domain
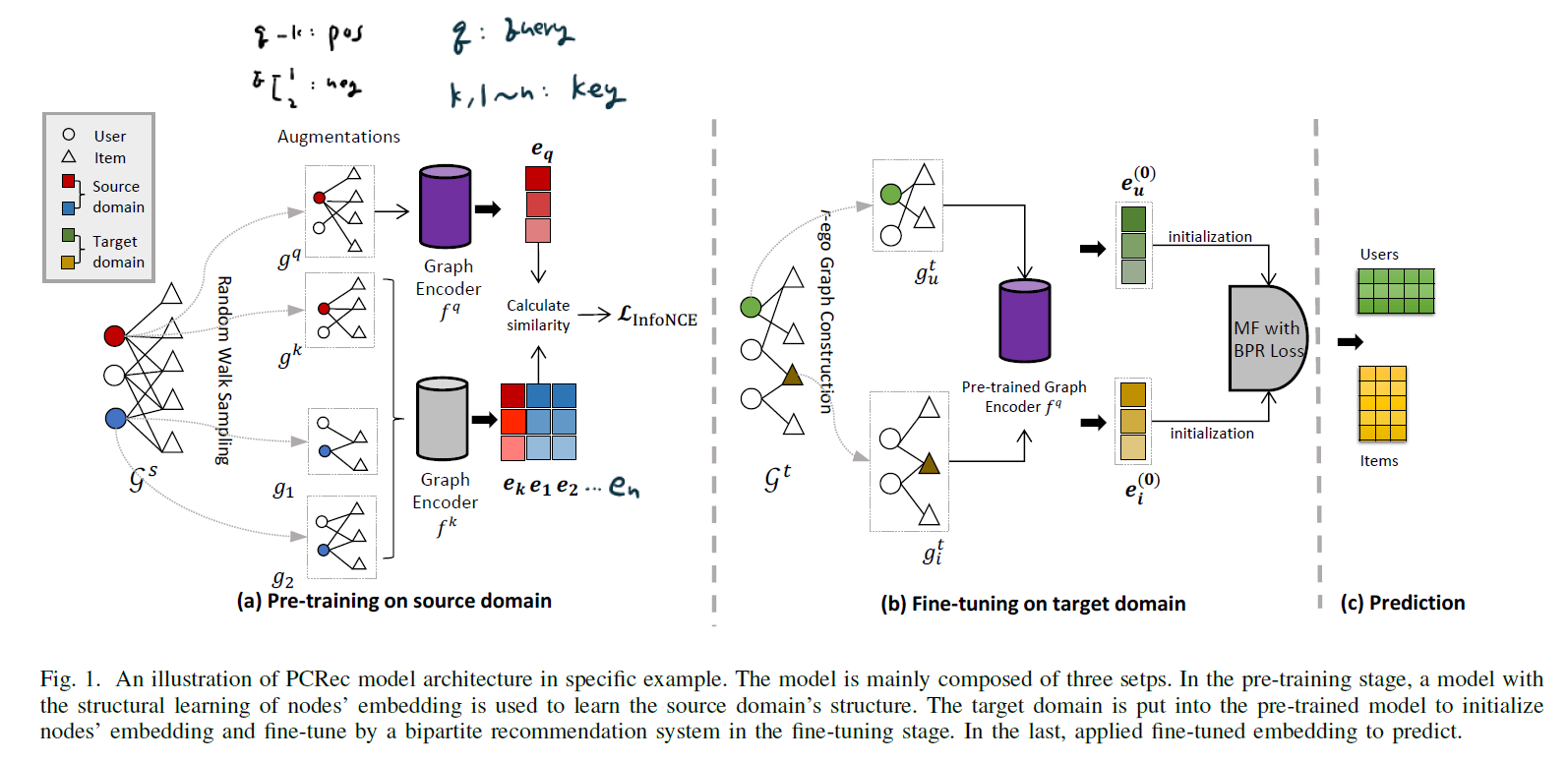
B~C 과정이 위 그림에 나와있습니다. Pre-training은 앞서 설명한 것처럼 self-supervised learning으로 진행됩니다. 먼저 query node $u$를 고릅니다. 그리고 이 node $u$ 에 대해 random walk를 수행하여 subgraph를 생성합니다. 이 subgraph는 $g^q$ 입니다. 그리고 같은 node에 대해 한 번 더 subgraph를 생성합니다. 이 subgraph는 $g^k$ 입니다. 이 2개의 subgraph들은 positive pair로 선택된 것입니다.
그리고 node $u$ 와 다른 node 하나를 선택했다고 해봅시다. 이 node에서 다시 random walk를 수행하여 $n$ 개의 subgraph를 생성합니다. 이 subgraph들은 $g^1, g^2, …, g^n$ 으로 표기합니다. 위 그림에서는 n=2인 예시를 보여준 것입니다.
이제 positve/negative pair로 사용할 subgraph 추출은 끝났습니다. 이를 활용하여 GNN Encoder를 학습시켜야 합니다. 이 때 2개의 구분된 graph encoder가 존재하는데, $f^q$ 는 query node를 위한 encoder이고 $f^k$ 는 그 외의 key nodes를 위한 encoder입니다. GIN: Graph Isomorphism Network가 학습 네트워크로 사용되었는데, 이에 대해 상세히 알고 싶다면 이 글을 참조하시길 바랍니다.
최적화를 위한 Loss Function은 아래와 같습니다.
\[\mathcal{L}_{infoNCE} = -log \frac{exp(e^T_q e_k / \tau)} {\Sigma_{i=1}^n exp(e^T_q e_i / \tau)}\]이 때 $\tau$ 는 hyperparameter입니다.
contrasive learning에서 K-size look-up key set을 유지하는 것은 굉장히 중요한데, 이 크기를 증가시키면 직관적으로 생각했을 때, 더 나은 sampling 전략이 될 것입니다.
하지만 계산량을 고려하여 본 논문에서는 queue와 moving-averaged encoder를 활용하여 key의 dynamic set을 유지하는 MoCo training scheme을 사용합니다.
C. Fine-tuning on Target Domain
Pre-trained된 모델의 결과물인 user/item embedding을 그대로 사용하는 것은 source domain graph의 structural bias를 그대로 반영하는 결과를 초래하게 될 것입니다. 따라서 이를 target domain에 맞게 fine-tuning하는 작업이 필요합니다.
본 논문에서는 MF 모델을 통해 이를 성취하며 아래와 같이 BPR(Bayesian Personalized Ranking) Loss를 통해 최적화를 수행합니다.
\[\mathcal{L}_{BPR} = -\Sigma_{i=1}^M \Sigma_{i \in \mathcal{N}_u} \Sigma_{j \notin \mathcal{N_u}} log \sigma(\hat{y}_{ui} - \hat{y}_{uj}) + \lambda \Vert \Theta \Vert^2\]D. Recommendation
최종 결과 임베딩을 사용하여 목적에 맞게 최종 추천 시스템을 구현하면 됩니다.
4. Experiments
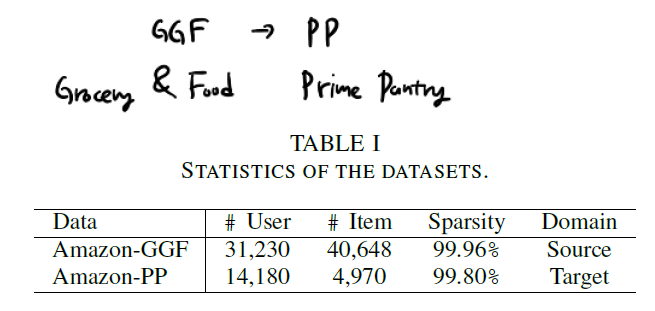
본 논문에서는 위 표에 나온 데이터를 사용하여 실험을 진행하였습니다. GGF가 source이고 PP가 target domain입니다. sparsity 문제는 현실 데이터에서도 정말 많이 마주하는데, 본 논문에서는 이 점을 고려하여 GGF 데이터셋에서는 10-core setting을, PP 데이터셋에서는 5-core setting을 사용하였습니다. 이는 최소 몇 개의 transaction을 발생시킨 user만을 대상으로 학습/예측을 진행하겠다는 규칙을 만든 것이라고 보면 됩니다. 저도 과거에 sparsity가 심한 대규모 데이터셋에 대해 이와 같은 제한을 적용했던 경험이 있습니다.
본 논문에서는 실험을 3가지 측면에서 분석하였습니다.
Step1: 기존 방법에 비해 우월한가?
Step2: r-hop neighbor에서 r은 어떻게 정하는가?
Step3: source domain에서 target domain으로 정보를 효율적으로 전달하기 위해서는 어떻게 해야하는가?
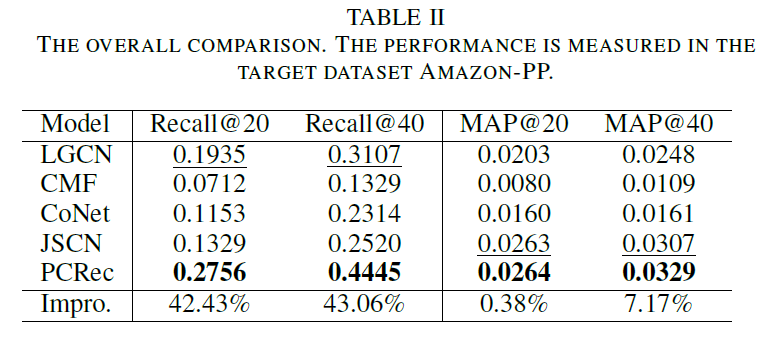
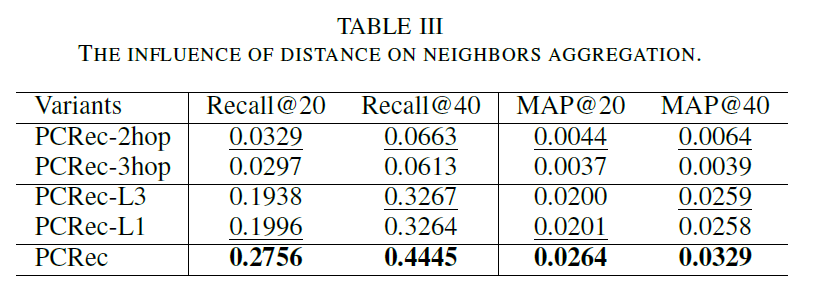
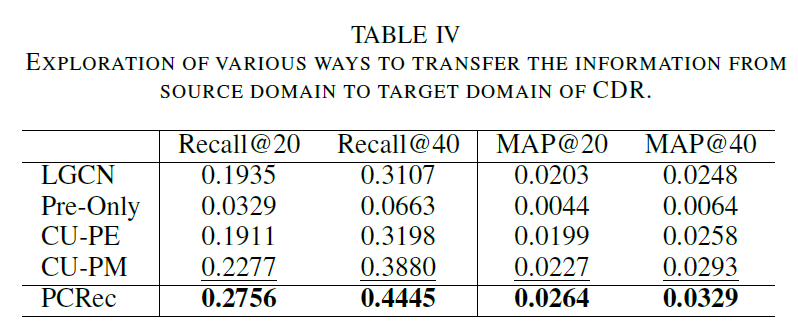
위의 결과를 보면 알겠지만, PCRec은 모든 비교 모델을 압도하는 성과를 보여줍니다. 2-hop neighbor 설정이 3-hop neighbor 설정 보다 더 나은 결과를 보여준 것은 놀랍지 않습니다. SIGN 논문에서도 기술하고 있듯이 단지 네트워크를 깊게 만들고 더 넓은 범위의 neighbor를 커버하는 것은 그리 효과적인 방법이 아닐 때가 많습니다.
pre-trained된 모델만을 사용했을 때, pre-trained된 모델의 임베딩을 fine-tuning의 초깃값으로 그대로 사용했을 때, 그리고 pre-trained된 모델로 하여금 fine-tuning 초깃값을 새로 생성하게 했을 때를 모두 비교해보면 마지막 결과가 가장 훌륭합니다. 이것이 3번째 질문에 대한 답이 될 것입니다.
5. Conclusion
본 논문은 복잡한 수식이나 새로운 Graph Convolutional Filter를 소개하는 것이 아니라 cross-domain recommendation 문제에 대해 기존의 여러 방법론들을 조합하여 접근한 논문입니다. 추천 시스템을 현실에서 구현할 때 마주하는 여러 문제를 해결하기 위해 참고하기에 훌륭한 연구자료로 판단됩니다.