
OpenAI GPT-3 - Language Models are Few-Shot Learners(GPT3 논문 설명)
14 Aug 2020 | Paper_Review NLP목차
- OpenAI GPT-3 - Language Models are Few-Shot Learners
- 초록(Abstract)
- 1. 서론(Introduction)
- 2. 접근법(Approach)
- 3. 결과(Results)
- 4. 벤치마크를 외웠는지 측정하고 예방하기(Measuring and Preventing Memorization Of Benchmarks)
- 5. 한계(Limitations)
- 6. 광범위한 영향(Broader Impacts)
- 7. 관련 연구(Related Work)
- 8. 결론(Conclusion)
- Appendix A: Details of Common Crawl Filtering
- Appendix B: Details of Model Training
- Appendix C: tails of Test Set Contamination Studies
- Appendix D: Total Compute Used to Train Language Models
- Appendix E: Human Quality Assessment of Synthetic News Articles
- Appendix F: Additional Samples from GPT-3
- Appendix G: Details of Task Phrasing and Specifications
- Appendix H: Results on All Tasks for All Model Sizes
- Refenrences
- Citation
이 글에서는 2020년 5월 Tom B. Brown 등이 발표한 OpenAI GPT-3: Language Models are Few-Shot Learners를 살펴보도록 한다.
GPT-3을 이용한 API가 공개되어 있다.
이 논문은 총 페이지수가 75페이지 정도는 된다.. 하지만 일부분을 제외하고 대부분 여기에 적었다.
OpenAI GPT-3 - Language Models are Few-Shot Learners
논문 링크: OpenAI GPT-3 - Language Models are Few-Shot Learners
API: GPT-3을 이용한 API
Github for Data: GPT-3
초록(Abstract)
최근 연구들은, 방대한 텍스트 말뭉치(corpus)로 사전학습(pre-training)한 후 특정 task에 맞춰 미세조정(find-tuning)하는 방법을 통해, 많은 NLP task에서 상당한 발전을 이루었다. (그러나, ) 이는 그 모델의 구조에 있어서는 task 종류에 민감하지 않지만(task-agnostic), (학습) 방법은 여전히 수천, 수만의 예시 데이터를 통해 어느 task에 특화된(task-specific) 미세조정 단계를 요구한다. 이와는 대조적으로, 사람은 일반적으로 단지 몇 개의 예시, 혹은 간단한 지시사항만으로도 (현 NLP 시스템에게는 여전히 많이 어려운) 새로운 언어 task를 수행할 수 있다.
이 논문에서 우리는 언어모델의 크기를 키우는 것이 task에 대한 일반성과(task-agnostic), few-shot 성능을 높이고, 미세조정 접근법을 사용한 이전의 state-of-the-art와도 비등한 성능을 확보할 수 있음을 보인다. 구체적으로, 이전의 그 어떤 비-희박 언어모델보다 10배는 많은 1750억 개의 인자를 가지는 자기회귀(auto-regressive) 언어모델인 GPT-3 를 학습시켜, few-shot 세팅에서 성능을 측정하였다. 모든 종류의 task에 대해, GPT-3는 어떤 gradient의 update나 미세조정을 거치지 않고 오직 few-shot 설명(문제 설명 등)을 취하였다. GPT-3는 번역, 질답(QA), cloze task 등의 많은 NLP 데이터셋과, 문장에서 새로운 단어를 쓰는 단어 해석, 3자리 연산, domain adaptation 등등 수많은 task에서 강력한 수행능력을 얻었다. 그와 동시에, GPT-3가 few-shot 학습을 할 때 여전히 어려워하는 몇몇 데이터셋과 더불어 거대한 웹 데이터셋으로 학습할 때 GPT-3가 방법론적인 문제를 맞이하는 데이터셋(이 무엇이 있는지)을 확인하였다. 마지막으로, GPT-3는 어떤 기사를 사람 또는 기계가 썼는지 판별하는 문제에서 사람이 봐도 어려움을 느낄 정도의 기사를 써낼 수 있음을 보인다. 그리고, GPT-3가 넓게 보아 어떤 사회적 영향력을 가질 수 있는지를 논의한다.
1. 서론(Introduction)
최근 몇 년간 NLP 시스템에서 사전학습된 언어 표현(representations)을 사용하는 추세가 있었고, downstream transfer을 위한 task-agnostic한 방향으로 적용되었다. 먼저, 단어 벡터를 사용하는 단일 레이어 표현을 학습시켜 task-specific한 모델 구조에 입력되고, 더 강력한 표현을 얻기 위해 다중 레이어 표현을 활용하는 RNN과 문맥적 state가 사용되었다(여전히 task-specific한 모델 구조를 가졌음). 그리고 더 최근에는 사전학습된 재귀, 또는 transformer 언어 모델이 task-specific한 모델 구조의 필요성을 제거하고 직접 미세조정하는 방식이 사용되었다.
이러한 최근의 패러다임은 독해, 질답, 원문함의 등등 수많은 어려운 NLP task들에서 상당한 발전을 이루어 냈으며, 새로운 모델구조와 알고리즘에 기반하여 더 많은 진전을 이루었다. 하지만, 이 방법의 큰 한계는 모델구조가 task-agnostic하더라도, 여전히 task-specific한 데이터셋과 task-specific한 미세조정 단계를 필요로 한다는 것이다: 특정 task에서 더 강력한 성능을 위해서는 일반적으로 해당 task에 초점이 맞춰진 수천~수만개의 데이터에 대해서 미세조정을 진행해야 한다. 이러한 한계를 없애는 것은 여러 이유에서 가치가 있다.
- 현실적인 관점에서, 새 task마다 레이블링이 전부 되어 있는 큰 데이터셋을 필요로 하는 것은 언어모델의 활용성을 제한한다. 문법교정에서 파생되는 어떤 것이든, 추상 개념의 예시를 생성하는 것과, 짧은 이야기를 비평하는 것 등을 포함하여 광범위한 분야에서 유용한 언어task들이 있다. 이러한 많은 task들에 대해 각각 그에 맞는 큰 규모의 감독학습용 데이터셋을 구하는 것은 어렵다(그 과정이 모든 새로운 task마다 반복되어야 하는 경우에는 특히 더).
- 학습 데이터에 존재하는 거짓 상관관계를 활용할 수 있는 가능성이 모델의 표현력과 학습 분포의 협소함에 따라 크게 증가한다. 이는 사전학습과 미세조정 패러다임에 문제를 야기하는데, 모델이 사전학습 동안에 정보를 습득할 수 있도록 큰 크기를 갖게 설계되었지만, 아주 좁은 task 분포에 미세조정(국한)된다. 예를 들어 Pretrained transformers improve out of distribution robustness는 더 큰 모델은 분포 외 데이터를 반드시 더 잘 일반화하지는 않는다. 모델은 학습 (데이터) 분포에 너무 맞춰져 있고 그 밖의 것은 잘 일반화하지 못하기 때문에 사전학습-미세조정 패러다임 하에서는 일반화가 잘 이루어질 수 없다는 증거가 존재한다. 따라서 특정 벤치마크에서 미세조정된 모델의 성능은 해당 부분에서는 인간 수준일지 몰라도 보다 근본적인 task에서는 실제 성능이 과장되었을 수 있다.
- 인간은 대부분의 언어 task를 배우기 위해 대규모 감독학습용 데이터셋이 필요하지 않다 - 자연어로 된 간단한 지시문 혹은 아주 적은 수의 예시만 있어도 어떤 사람이 새로운 task를 충분히 능숙하게 수행하도록 만들 수 있다(예: 이 문장이 기쁜 혹은 슬픈 무언가를 말하는지 선택하라. 또는, 여기 용감한 행동을 하는 사람 예시 2개가 있다. 용감한 행동의 세 번째 예시를 들라). 현재 NLP 기술에서 이런 개념적인 한계를 제쳐놓더라도, 이러한 적응 능력은 현실적으로 이점이 있다 - 이는 사람을 균일하게 여러 task와 기술들을 섞거나 전환하게 할 수 있다(긴 대화문에 무언가 더 추가하는 것 등). 더 넓은 곳에서 유용하게 쓰이려면, NLP 시스템을 (사람만큼) 유동적이고 일반성을 갖도록 할 것 이다.
이러한 문제들을 다루는 가능성 있는 방법은 언어모델의 문맥에서, 모델이 학습하는 동안 여러 기술과 패턴인식 능력을 키우고, 추론 시간에는 이를 원하는 task에 빠르게 적용시키거나 인식시키는 방법인 meta-learning이다.
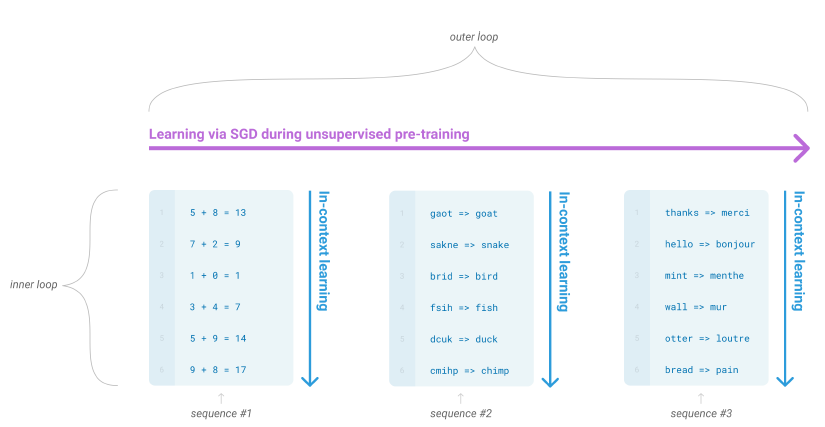
무감독 사전학습 동안, 언어모델은 여러 기술들과 패턴인식 능력을 키워 이를 추론 시간에 사용한다. 각 sequence에 대해 forward-pass 안에서 일어나는 내부 반복 과정을 문맥 내 학습 이라고 부른다. 이 다이어그램에서 문장들은 사전하습 동안 모델이 데이터 표현을 볼 수 있게 하지는 않지만, 모델은 어떤 하위 작업들이 한 개의 sequence 내에서 일어난다는 사실은 알 수 있다.
우리가 문맥 내 학습이라고 부르는 이것을 통해 시도하려는 최근 연구는 사전학습된 언어모델의 텍스트 입력을 task specification의 형태로 사용한다: 이 모델은 자연어 지시문과 task 설명이라는 조건 속에서 ‘다음에 무엇이 올 것인지를 예측’한다.
이 방법은 처음에는 가능성을 보였지만, 여전히 미세조정에 비하면 갈 길이 멀다 - 예를 들어 Language models are unsupervised multitask learners 는 Natural Questions에서 4%만을, 55 F1 CoQa를 달성하였는데 이는 최신 결과보다 35점이나 뒤떨어진 결과이다. Meta-learning은 명백히 언어 task를 푸는 현실적인 방법으로서 실행 가능하기 위한 상당한 개선을 요구한다.
언어모델링의 다른 최신 경향은 앞으로 갈 길을 제시할 수 있다. 최근 몇 년간 Transformer 언어 모델의 크기(parameter의 수)는 1억 개부터 3, 15, 80, 110, 170억 개까지 증가하였다. 크기가 증가할 때마다 텍스트 합성과 downstream NLP task에서 상당한 성능 개선을 보여주었고, 이러한 log loss는 많은 downstream task와 관련하여 scale에 따라 개선되는 경향이 뚜렷하다. 문맥 내 학습이 모델의 parameter 안에서 많은 기술과 task를 습득하기 때문에, 문맥 내 학습 능력은 scale에 따라 그 능력이 더 증가한다고 보는 것은 설득력이 있다.
이 논문에서, 우리는 1750억 개의 parameter를 가지는 자기회귀 언어모델(GPT-3)을 학습함으로서 이 가설을 테스트하고, 그 문맥 내 학습능력을 측정한다. 구체적으로, GPT-3을 학습셋에 직접 포함되어 있지 않은 task에 대해 빠르게 적응할 수 있는지를 테스트하도록 고안된 여러 최신 task를 포함하여 20개 이상의 NLP 데이터셋에 대해 평가를 진행한다. 각 task에 대해, GPT-3를 3가지 조건에서 평가한다:
- few-shot learning, 혹은 모델의 10/100개의 문맥창(context window)에 맞는 설명 또는 예시(demonstration)을 허용하는 문맥 내 학습 조건,
- one-shot learning, 딱 한 개의 예시만을 허용하는 조건,
- zero-shot learning, 어떤 예시도 허용되지 않고, 모델에 주어지는 것은 오직 자연어로 된 지시문인 조건.
GPT-3은 전통적인 미세조정 조건에서 평가할 수도 있지만, 이는 추후 연구로 남겨둔다.
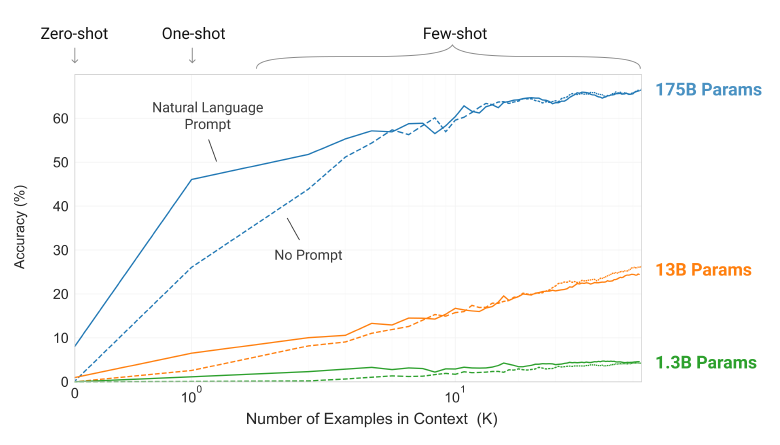
위 그림은 우리가 연구한 조건에서, 모델이 단어에서 관련 없는 기호를 제거하도록 하는 task에서 few-shot learning 결과를 보여준다. 모델 성능은 자연어 지시문이 포함되면, 모델 문맥에 주어지는 예시의 수($K$)가 증가하면 높아진다. Few-shot learning 성능은 모델 크기에 따라서도 크게 증가한다. 모델의 크기와 문맥 내 예시의 수와 관련한 일반적인 경향은 우리가 연구하는 대부분의 task에 대해서도 성립한다. 우리는 이러한 “학습” 곡선은 어떤 가중치 업데이트나 미세조정을 거치지 않았으며, 단지 조건으로 주어지는 예시의 수를 늘렸을 뿐이다.
대략, NLP task들에서 GPT-3은 zero-shot과 one-shot 조건에서 훌륭한 결과를, few-shot 조건에서도 SOTA와 비슷하거나 경우에 따라서는 넘어서는 결과를 보여주었다. 예로, GPT-3은 CoQA, zero-shot에서 81.5 F1을(심지어 기존 SOTA는 미세조정 모델이다), few-shot에서는 85.0 F1을 달성했다. 비슷하게, TriviaQA에서는 zero-shot에서는 64.3%, one-shot에서는 68.0%, few-shot에서는 71.2%로, few-shot의 경우는 같은 closed-book 세팅에서 SOTA를 달성한 미세조정 모델의 것과 같다.
GPT-3은 또한 단어해독(순서 맞추기), 연산 수행, 정의된 것을 단 한 번만 보고서 문장에서 새로운 단어를 사용하는 등 즉석에서 추론하는 task와 빠른 적응력을 측정하는 task들에서 one-shot과 few-shot에서 숙련된 결과를 내놓음을 보여주었다. 또한 few-shot 세팅에서, GPT-3은 사람이 보기에도 주어진 기사가 인간 혹은 기계가 썼는지 분간하기 어려운 기사를 생성해낼 수 있다.
그와 동시에, GPT-3이 few-shot에서 어려움을 겪는 몇몇 task를 확인하였다. 여기에는 자연어 추론문제인 ANLI, 독해 데이터셋인 RACE와 QuAC 등이 포함된다. 이러한 한계를 포함하여 GPT-3의 장단점을 보여줌으로써, 우리는 언어모델에서 few-shot learning의 연구를 촉진하고 어떤 개선이 가장 필요한지 관심을 모을 수 있을 것이다.
전체 결과의 느낌은 아래 그림에서 볼 수 있다. zero-shot 성능은 모델 사이즈에 따라 천천히 증가하는 것에 비해, few-shot은 더 가파르게 증가하며, 더 큰 모델일수록 문맥 내 학습에서 월등함을 보여준다. 논문에서 그림 3.8을 보면 SuperGLUE에서 더 자세한 분석을 볼 수 있다.
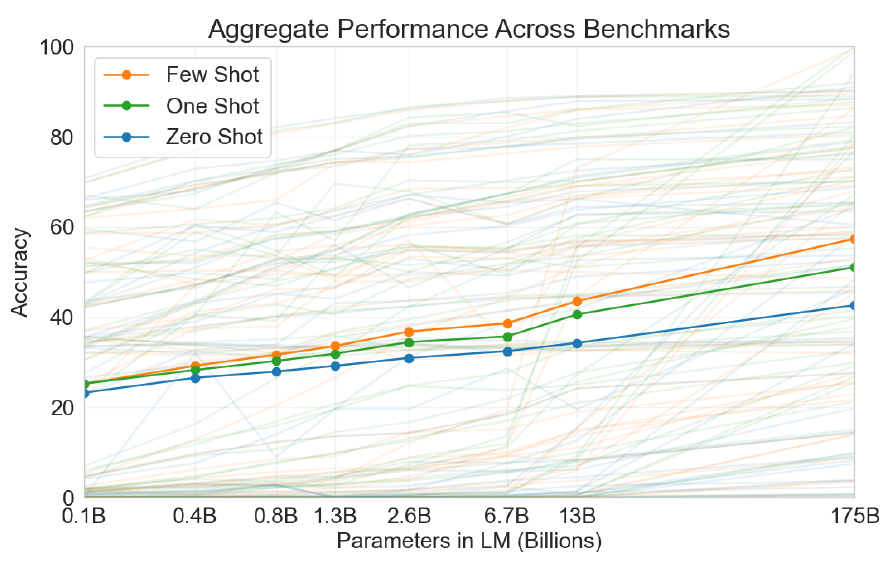
또, 데이터 오염(학습 데이터셋과 테스트 데이터셋이 겹치는 문제)에 대해서도 체계적으로 연구했다 - Common Crawl 등을 통해 얻은 데이터셋에서 거대한 모델을 학습시킬 때 생기는 문제로, 웹에서 모은 데이터가 있기 때문에 가질 수 있는 문제이다(즉, train/test set이 우연히 겹치는 부분이 적지 않을 수 있다). 이 논문에서 데이터 오염과 그 왜곡 효과를 측정하는 체계적 도구를 개발했다. GPT-3의 성능은 대부분의 데이터셋에서 데이터 오염에 미미한 영향만을 받았지만, 우리는 약간의 데이터셋에서 오염이 충분히 큰 영향을 가질 수 있음을 보이고, 또 그 심각도에 따라 그러한 데이터셋에는 별표(*)를 하여 결과에 포함하지 않았다.
위의 모든 것에 더하여, 우리는 zero, one, few-shot 세팅에서 GPT-3의 성능을 비교하기 위해 1.25억~130억 개의 parameter를 가지는 작은(?) 모델을 학습시켰다. 폭넓게, 대부분의 데이터셋에서 모든 3가지 조건에서 상대적 smooth scaling을 찾았다: 주목할 만한 패턴은 zero, one, few-shot 성능은 종종 모델 크기에 따라 증가하며, 이는 더 큰 모델은 더 능숙한 mera-learner임을 시사한다.
마지막으로, GPT-3에 의해 보여진 광범위한 역량에서, 우리는 편향성, 공정성, 나아가 사화적 영향력과, 에 점에서 GPT-3의 특징에 대한 예비 분석을 시도하고 논의할 것이다.
이 논문의 남은 부분은 다음과 같이 구성된다. Section 2에서는 GPT-3을 학습시키고 평가하는 접근법과 방법을 소개한다. Section 3에서는 zero, one, few-shot 세팅에서 전체 범위의 task에 대한 결과를 보여준다. Section 4에서는 데이터 오염에 대한 문제를, Section 5에서는 GPT-3의 한계에 대해 논한다. Section 6에서는 GPT-3의 영향력을, Section 7에서는 관련 연구를 보고 Section 8에서는 결론을 다룬다.
2. 접근법(Approach)
모델, 데이터, 학습 등 기본적인 접근법은 Language models are unsupervised multitask learners와 비슷하지만, 모델의 크기를 키웠고, 데이터셋의 크기와 다양성, 학습량을 전부 늘렸다. 문맥 내 학습도 위 논문(GPT-2)와 비슷하지만, 이 논문에서는 문맥 내 학습을 위해 세팅을 다르게 하는 체계적인 방법을 보인다. 그래서, GPT-3을 평가하거나 원칙적으로 평가 가능할 수 있게 하는 여러 세팅들을 정의하고 대조하는 것으로 이 section을 시작한다. 이러한 세팅은 task-specific한 데이터에 얼마나 의존하려는 경향이 있는지를 보는 것이라 할 수 있다. 구체적으로, 4가지로 나누어 볼 수 있다:
- 미세조정(Fine-Tuning, FT)은 최근에 가장 일반적인 접근법으로, 사전학습된 모델을 원하는 task에 맞도록 감독학습 데이터셋으로 학습시키는 과정을 포함한다. 보통 수천~수만 개의 레이블링된 예시를 필요로 한다.
- 이러한 미세조정(fine-tuning)의 주된 장점은 많은 벤치마크에서 강력한 성능을 가지는 것이다.
- 주된 단점은 모든 task마다 큰 데이터셋을 새로이 필요로 하며, 분포 외의 데이터에 대해서는 일반화를 잘 못하며, 학습 데이터에 거짓/비논리적인 특성이 있는 경우 이를 흡수할 수도, 사람에 비해 불공정한 비교로 이어질 수도 있다.
- 이 논문에서는 task-agnostic한 성능을 가지는 것이 목적이기 때문에 GPT-3은 미세조정을 진행하지 않는다. 단, 나중에는 추후 연구로 괜찮은 방향이기에 미세조정을 사용할 수도 있다.
- Few-Shot(FS)은 모델이 추론 시간에서 단 몇 개의 예시만을 볼 수 있되 가중치 업데이트는 허용되지 않는 조건이다. 그림 2.1에서 보듯이, 일반적인 데이터셋에서 예시는 문맥과 원하는 답이 있고(예로는 영어-독일어 번역), few-shot은 단 $K$개의 문맥과 답이 주어진다. 이후 마지막으로 단 한 개의 문맥이 주어지면, 모델은 (정확한) 답을 생성해 내야 한다.
- 우리는 보통 $K$는 10~100 정도로 설정했고, 이는 모델의 문맥창($n_{ctx} = 2048$)에 잘 맞을만한 개수이다.
- few-shot의 주된 장점은 task-specific한 데이터에 대한 필요를 크게 줄여주며(즉, 몇 개 없어도 됨) 지나치게 크고 좁은 분포를 갖는 미세조정용 데이터셋을 학습할 가능성을 줄일 수 있다.
- 주된 단점은 이 방법은 미세조정 모델의 SOTA에는 한참 뒤떨어지는 성능을 갖는다는 점이다. 또한, 적은 수라 해도 여전히 task-specific한 데이터를 필요로 한다.
- 이름에서 알 수 있듯이, 언어 모델에서 few-shot learning은 기계학습에서 다른 문맥에서 사용된 few-shot learning과 연관이 있다 - 둘 다 넓은 분포를 갖는 task에 기반한 학습 방법이며(이 경우에는 사전학습 데이터에서) 새로운 task에 빠르게 적응하는 방법이다.
- One-Shot(IS)은 few-shot과 비슷하나 단 한 개의 예시와, task에 대한 자연어 지시문이 제공된다는 점이 다르다. one-shot이 few나 zero-shot과 다른 점은 이 방법이 사람이 소통하는 방법과 가장 흡사한 방법이기 때문이다.
- 예를 들어, Mechanical Turk와 같이, 사람에게 데이터셋을 만들어내라는 요청을 할 경우, 보통 task에 대해 하나의 예시를 주게 된다(물론 지시문과 함께). 이와 대조적으로, 예시가 아예 없다면 task의 내용이나 형식에 대해 소통하는 것이 어려울 수 있다.
- Zero-Shot(0S)은 one-shot과 비슷하지만 단 하나의 예시도 없으며, 모델은 단지 task에 대한 지시문만을 받는다.
- 이 방법은 최대의 편의성을 갖는데, robustness나, 거짓 상관관계 등을 걱정할 필요가 없다.
- 단, 가장 어려운 조건이다.
- 어떤 경우에는 사람조차도 예시가 없으면 task에 대해 제대로 이해하지 못할 수도 있고, 따라서 이 조건은 “불공정할 정도로 어렵다”고 할 수 있다.
- 예를 들어, 누군가 ‘200m 달리기를 위한 세계기록 표를 만들라’고 한다면, 이 요청은 상당히 모호할 수 있는데, 표가 어떤 형식을 가져야 하고, 어떤 내용이 들어가야 하는지에 대한 명확한 설명이 없기 때문이다.
- 그럼에도 불구하고, 적어도 zero-shot의 조건은 사람이 task를 수행하는 것과 가장 가까운 방식이다 - 예로, 아래 그림에서 사람은 단지 텍스트 지시문만을 보고도 무엇을 해야 할지 알 수 있을 것이다.

위 그림은 영어-독일어 번역 예시에 대한 4가지 방법을 보여준다. 이 논문에서는 zero, one, few-shot에 집중하는데, 경쟁 상대로 보는 것이 아닌 비교 상대로 보기 위함이며, 다른 문제 세팅에서 특정 벤치마크에서의 성능과 sample의 효율성 사이에서 균형을 찾는다. 특히 few-shot 결과는 미세조정 모델보다 아주 약간 못한 결과를 보임을 강조한다. 궁극적으로, 하지만, 사람이 하는 것과 거의 비슷한 one-shot이나 zero-shot에서는 추후 연구의 중요한 목표로 둔다.
Section 2.1~2.3에서는 모델, 학습 데이터, 학습 과정을 자세히 설명한다. Section 2.4에서는 어떻게 few, one, zero-shot 평가를 진행했는지를 자세히 말한다.
2.1 Model and Architectures
모델 초기화, 사전 정규화, 내부 서술된 되돌릴 수 있는 토큰화 과정을 포함하여 GPT-2와 동일한 구조를 갖지만, Sparse Transformer와 비슷하게, Transformer 레이어 내에서 밀집/희박한 국소 집중 패턴을 번갈아 사용하였다. 모델 크기에 따른 기계학습 성능의 의존도를 살펴보기 위해, 1.25억 개부터 1750억 개의 parameter를 가지는 8가지 다른 크기의 모델을 학습시켰고, 가장 큰 마지막 것은 GPT-3라 부르는 모델이다. 이전 연구에서 충분한 학습 데이터를 갖고 있으면 validation loss는 크기에 대한 함수로 부드러운 멱법칙을 따를 것이라 하였다; 여러 다른 크기의 학습 모델은 validation loss와 downstream 언어 과제들에 대한 가설을 모두 검증할 수 있게 해 준다.
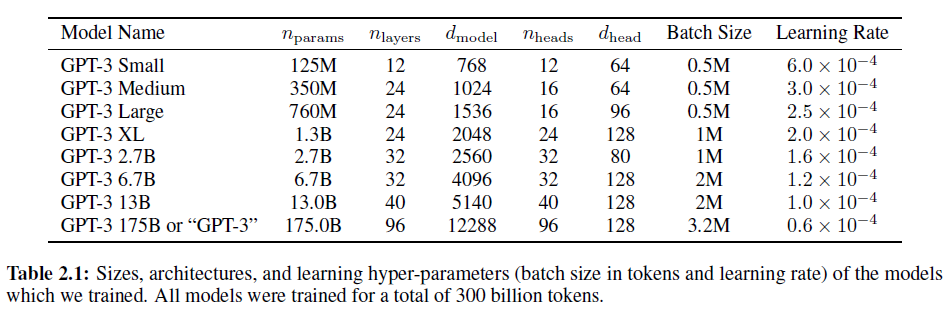
위 표는 8가지 모델의 크기와 구조를 보여준다. $n_{params}$는 학습가능한 parameter의 전체 개수, $n_{layers}$는 레이어 수, $d_{model}$은 각 bottleneck 레이어 안에 있는 unit의 수(이 논문에서, 항상 $d_{ff} = 4 \times d_{model}$이다), $d_{head}$는 각 attention head의 차원이다. 모든 모델은 $n_{ctx} = 2048$ 토큰을 가진다.
각 GPU 노드 등 데이터 이동을 줄이기 위해 깊이와 너비에 따라 여러 GPU에 모델을 나누었다. 또한 각 모델의 정확한 parameter 수는 계산효율성과 GPU의 부하 균형에 맞게 정했다. 이전 연구는 validation loss는 합리적인 범위 내에서는 parameter의 작은 차이에 크게 민감하지 않음을 시사한다.
2.2 Training Dataset
언어모델을 위한 데이터셋은 빠르게 확장되어 거의 1조 개의 단어로 구성된 Common Crawl 데이터셋에서 정점을 찍고 있다. 데이터셋의 이 크기는 같은 데이터를 두 번 쓰지 않아도 이 논문의 가장 큰 모델을 학습시키에도 충분하다. 하지만, 필터링을 전혀 또는 거의 거치지 않은 Common Crawl 데이터는 조정된 데이터셋에 비해 낮은 품질을 갖는 경향이 있다. 따라서, 데이터셋의 품질을 높이기 위한 3가지 방법이 사용되었다:
- 고품질 출처와 연관성이 있는 것만을 받아 정제하고
- 과적합을 정확히 측정하기 위한 온전성을 남겨두고 중복을 피하기 위해 문서 수준에서 중복 제거 작업을 수행하였고,
- 다양성을 증가시키기 위해 고품질 출처로 알려진 말뭉치를 추가하고 섞어서 사용하였다.
자세한 것은 부록 A를 참조하라. 추가 데이터셋으로는 WebText, Books1와 Books2, 영어 위키피디아가 있다.
아래 표는 혼합된 데이터셋 구성을 보여준다. CommonCrawl의 경우 45TB의 데이터셋을 정제하여 570GB로 만들었다(4천억 개의 byte pair encoded 토큰으로 구성됨). 학습에서, 데이터의 사용은 데이터셋의 크기에 비례하지 않고, 고품질일수록 많이 선택되었다. 이는 고품질과 과적합 사이의 trade-off가 있는 것이다.
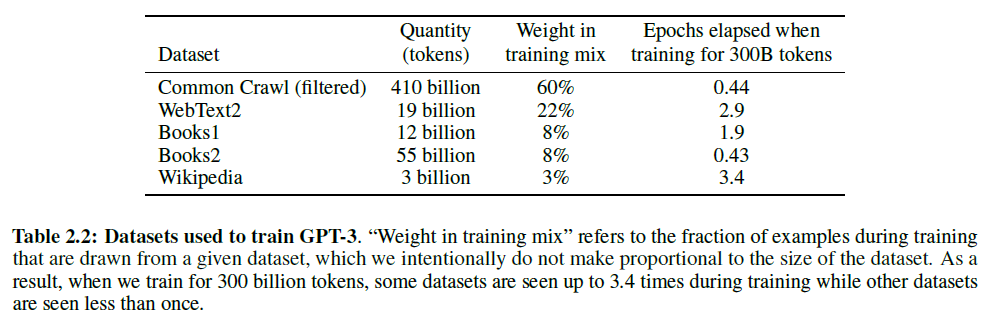
인터넷에서 가져온 데이터로 사전학습한 언어모델에서 가장 큰 방법론적 문제는, 특히 굉장한 양의 내용을 기억하려는 큰 모델에서, 사전학습 동안 무심코 본 정보를 test나 dev set에서 다시금 마주하게 되는 (데이터) 오염 문제이다. 이러한 오염을 줄이기 위해서, 논문에서 살펴보는 모든 벤치마크의 dev/test set와 겹치는 어떤 부분이든 제거하려는 노력을 하였다.
안타깝게도, 일부 겹치는 부분을 무시하는 버그기 필터링 과정에서 있었고, 학습의 비용 문제로 인해 다시 모델을 학습하는 것은 비현실적이었다. 그래서 이 영향을 Section 4에서 살펴보고, 데이터 오염을 더욱 공격적으로 제거하는 추후 연구를 할 것이다.
2.3 Training Process
일반적으로 큰 모델일수록 더 큰 batch를 쓰지만, learning rate는 더 작게 해야 한다. 학습하는 동안 gradient noise scale을 측정하고 이를 batch size를 선택하는 가이드로 사용하였다. Table 2.1에서 사용한 parameter setting을 보여 준다. 메모리 부족 없이 더 큰 모델을 학습시키기 위해, 각 행렬곱 내에서 모델 병렬화와 네트워크의 레이어에서 모델 병렬화를 섞어 사용하였다. 모든 모델은 고대역 클러스터의 일부분으로 V100 GPU에서 학습되었다. 자세한 학습 과정은 부록 B에 있다.
2.4 Evaluation
few-shot learning에서, evaluation set의 각 예제에 대해 training set에서 조건으로 $K$개의 샘플을 뽑아 평가하였다(task에 따라 1~2개의 개행문자를 구분자로 사용함). LAMBADA와 StoryCloze에는 감독학습 셋이 없으므로 train-eval set 대신 dev-test set을 사용했다. Original Winograd는 set이 하나뿐이므로 그냥 같은 곳에서 뽑았다.
$K$는 모델의 context window이 허용하는 범위에 따라 $0 \sim \infty$가 될 수 있는데, 모든 모델에 대해 $n_{ctx}=2048$이고 보통 $10 \sim 100$개의 샘플에 맞는다. 큰 $K$가 항상 좋지는 않기 때문에 분리된 dev/test set이 있다면 적은 $K$를 dev set에 사용하여 최고의 값을 test set에서 사용했다. 일부(부록 G)에 대해서는 demonstration에 더해 자연어 지시(prompt)를 사용했다.
각 모델 크기와 학습 세팅(zero, one, few-shot)에 따라 test set에서의 최종 결과가 나와 있다. test set이 비공개인 경우에는, 테스트를 위해 모델을 올리는 것은 모델이 너무 커서 불가능하기에 dev set으로 결과를 얻었다. 적은 수의 데이터셋에 대해서는 test 서버에 제출했고 단 200B개의 few-shot 결과만 제출하였으며, 다른 모든 것에 대해 dev set 결과를 얻었다.
3. 결과(Results)
아래 그림은 10만 개 정도의 parameter를 갖는 작은 모델을 포함한 결과를 보여 준다.
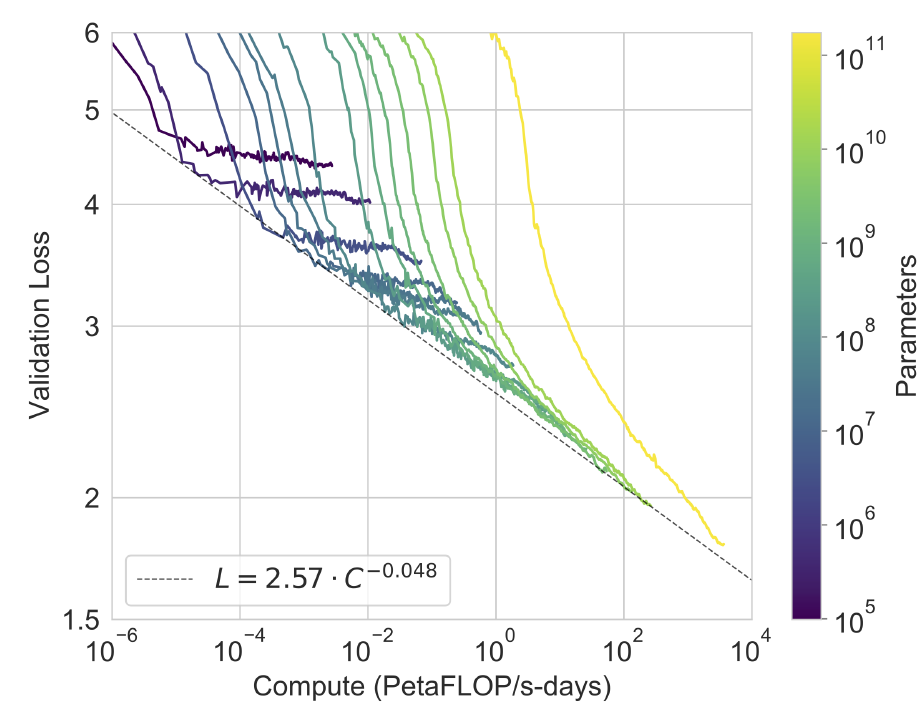
언어모델링 성능은 학습 계산량의 효율에 따라 지수적으로 증가한다. 누군가는 cross-entropy loss에서 이러한 발전이 단지 겉만 그럴싸한 학습 말뭉치의 작은 차이로 인한 것이라 생각할 수 있지만, 그런 것이 아닌 일관된 개선을 의미함을 보일 수 있다.
광범위한 데이터셋에 대해 Section 2에서 언급된 8개의 모델(GPT-3과 작은 모델들)을 테스트하였고, 비슷한 데이터셋끼리 묶어 9개로 나누었다.
- Section 3.1에서는 전통적인 언어모델링 task와 비슷한 것들(Cloze 등), 문장/문단 완성 task에 대해 평가하였다.
- Section 3.2에서는 “closed book” QA task를,
- Section 3.3에서는 언어 간 번역능력을,
- Section 3.4에서는 Winograd Schema와 같은 task를,
- Section 3.5에서는 상식추론/질답을,
- Section 3.6에서는 독해를,
- Section 3.7에서는 SuperGLUE를,
- Section 3.8에서는 자연어추론(NLI)를,
- Section 3.9에서는 즉석 추론, 적응 기술, open-ended 텍스트 합성 등 문맥 내 학습능력을 탐색하는 추가적인 task를 개발하였다.
3.1. Language Modeling, Cloze, and Completion Tasks
전통적인 언어모델링 task에 대해 GPT-3의 성능을 측정하였다. 흥미있는(of interest) 한 개의 단어를 예측하거나, 문장/문단을 완성하거나, 텍스트를 완성시키는 가능한 것들 중 하나를 선택하는 task이다.
3.1.1 Language Modeling
Penn Tree Bank(PTB)에 대해 zero-shot perplexity를 계산했으나, Wikipedia와 연관된 4개의 task는 학습데이터에 포함된 부분이 있기 때문에 결과에서 생략하였다.
이전 SOTA보다 15 point 앞서는 20.50 Perplexity를 기록하였다. 여기서는 데이터셋의 명확한 구분이 없기 때문에 zero-shot만 테스트했다.
Penn Tree Bank
Penn Tree Bank는 말뭉치 주석(corpus annotation) 중 구문 주석(syntactic annotation) 말뭉치의 일종으로, 기존의 구조 분석보다 정교한 tree structure의 집합이다. 330만 어절 이상의 월스트리트 저널(Wall Street Journal (WSJ))의 문장들로 이루어져 있으며 공개되어 있는 데이터셋이다. Treebank-3은 1999년에 나왔으며 2499개의 story부터 만들어진 98732개의 syntactic annotation story를 포함한다.
3.1.2 LAMBADA
LAMBADA dataset은 텍스트에서 장거리 의존성 모델링을 테스트한다 - 모델은 문맥 문단을 읽어 문장의 마지막 단어를 예측해야 한다. 최근 언어모델의 크기를 키우는 것은 이 어려운 벤치마크에 대한 성능을 경감시킨다는 것이 제안되어 왔다. 모델을 두 배 키워도 1.5% 정도의 향상만이 있었다.
그러나 큰 모델은 여전히 유효한 연구 방향이다. GPT-3은 이전 SOTA보다 8% 향상된 76%의 정확도를 보였다.
LAMBADA는 이 데이터셋에서 흔히 나타나는 문제를 다루는 방법으로 few-show learning의 유연성을 설명해줄 수도 있다. LAMBADA 문장의 완성은 언제나 문장의 마지막 단어이지만, 표준 언어모델은 이 부분을 알 수 없다. 이 문제는 과거에 stop-word로 다루어져 왔다. Few-shot learning 세팅은 대신 이 task를 cloze-test처럼 “frame”화 하여 언어모델이 딱 하나의 단어가 필요함을 알도록 할 수 있다. 여기서 ‘빈칸 채우기’ 형식을 활용했다.
Alice was friends with Bob. Alice went to visit her friend _____. -> Bob
George bought some baseball equipment, a ball, a glove, and a _____. ->
이렇게 했을 때 GPT-3은 86.4%의 정확도를 보여 이전보다 18% 향상된 결과를 얻었다. 여기서 few-show 성능은 모델의 크기에 따라 크게 향상될 수 있다는 것을 알 수 있다.
LAMBADA dataset
LAMBADA dataset(LAnguage Modeling Broadened to Account for Discourse Aspects)은 단어 예측 task로서 계산모델이 텍스트를 이해했는지를 판별할 수 있는 dataset이다. 이 데이터셋은 전체 문맥이 주어졌을 때 마지막 단어가 무엇일지를 사람이 맞추어 생성된 서술형 구절들로 이루어져 있다. 계산모델은 여기서 단지 지역적인 문맥뿐 아니라 더 넓은 범위의 담화에서 정보들을 얻어 사용할 수 있어야 한다.
예시:
Context: “Yes, I thought I was going to lose the baby.” “I was scared too,” he stated, sincerity flooding his eyes. “You were ?” “Yes, of course. Why do you even ask?” “This baby wasn’t exactly planned for.”
Target sentence: “Do you honestly think that I would want you to have a ?”
Target word: miscarriage
3.1.3 HellaSwag
HellaSwag dataset은 어떤 이야기나 지시문 집합의 끝맺음 문장으로 어느 것이 가장 좋을지를 선택하는 문제를 다룬다. 사람에게도 살짝 어려운 문제이지만(95.6% 정확도), GPT-3은 78.1%(one-shot), 79.3%(few-shot)을 달성하며 종전의 미세조정된 15억 개의 parameter를 가진 모델(75.4%)를 뛰어넘었다. 그러나 여전히 미세조정된 multi-task 모델인 ALUM(85.6%)에 비하면 낮은 점수이다.
HellaSwag
HellaSwag dataset은 task를 다루는 데 있어 상식(commonsense)가 필요하다. video caption인 ActivityNet Captions dataset에서의 데이터만 사용한다(original SWAG dataset은 LSMDC의 caption 데이터도 포함한다). 시간정보를 포함하는 서술(temporal description)과 각 caption에 대한 activity label을 포함한다.
예시:
Pick the best ending to the context. How to catch dragonflies. Use a long-handled aerial net with a wide opening. Select an aerial net that is 18 inches (46 cm) in diameter or larger. Look for one with a nice long handle.
a) Loop 1 piece of ribbon over the handle. Place the hose or hose on your net and tie the string securely.
b) Reach up into the net with your feet. Move your body and head forward when you lift up your feet.
c) If possible, choose a dark-colored net over a light one. Darker nets are more difficult for dragonflies to see, making the net more difficult to avoid.
d) If it’s not strong enough for you to handle, use a hand held net with one end shorter than the other. The net should have holes in the bottom of the net.
3.1.4 StoryCloze
StoryCloze 2016 dataset에서는 few-shot에서 종전 기록보다 4.1% 낮은 87.7%을 기록하였으나, zero-shot에서는 거의 10%가량 향상되었다(83.2%).
StoryCloze 2016 dataset
StoryCloze 2016 dataset은 5문장의 긴 story에서 가장 적절한 끝맺음 문장을 선택하는 문제로, 3744개의 test set을 보유하고 있다.
Context: Karen was assigned a roommate her first year of college. Her roommate asked her to go to a nearby city for a concert. Karen agreed happily. The show was absolutely exhilarating.
Right Ending: Karen became good friends with her roommate.
Wrong Ending: Karen hated her roommate.
3.2. Closed Book Question Answering
이 Section에서는 광범위한 사실적 지식(broad factual knowledge)에 대한 QA 능력을 측정한다. 가능한 질의가 방대하기 때문에, 이 task는 보통 연관된 텍스트를 찾는 정보 검색 시스템에 더해, 질문과 검색한 텍스트가 주어지면 답변을 생성하는 모델을 함께 사용하는 접근법을 사용해 왔다. 이러한 세팅은 “open-book” 과 같은 방식으로 쓸 수 있다. 최근에는 보조적인 정보라는 조건 없이도 질문에 대한 답변을 잘 생성하는 충분히 큰 모델이 제안되었다. 이러한 방식은 “closed book”으로 불린다.
여기서는 GPT-3을 Natural Questions, WebQuestions, TriviaQA 3개에 대해 측정하였다. 기존의 closed-book 세팅에 더해 few, one, zero-shot 평가를 진행(더 엄격한 조건)하였다.
아래에 결과가 있다.
- TriviaQA: zero-shot에서 64.3%, one-shot에서 68.0%, few-shot에서 71.2%를 달성하였다. zero-shot 결과는 T5-11B를 14.2% 차이로 능가하는 성능을 보여 주었다. one-shot에서도 3.7%의 차이로 SOTA를 제치는 등의 결과를 얻었다.
- WebQuestions(WebQs): fine-tune 모델에 비하면 조금 낮지만 비슷한 수준의 성능을 보여준다.
- Natural Questions(NQs): WebQs에서와 비슷하게 zero~few-shot에서의 큰 발전은 분포의 이동을 제안할 수 있으며, TriviaQA나 WebQS에 비해 더 낮은 경쟁력을 보여주는 것을 설명할 수 있다. 특히, NQs의 질문은 Wikipedia에서 아주 fine-grained한 지식을 물어보기에 특히 이는 GPT-3의 용량과 광범위 사전학습 분포의 한계를 테스트해볼 수 있다.
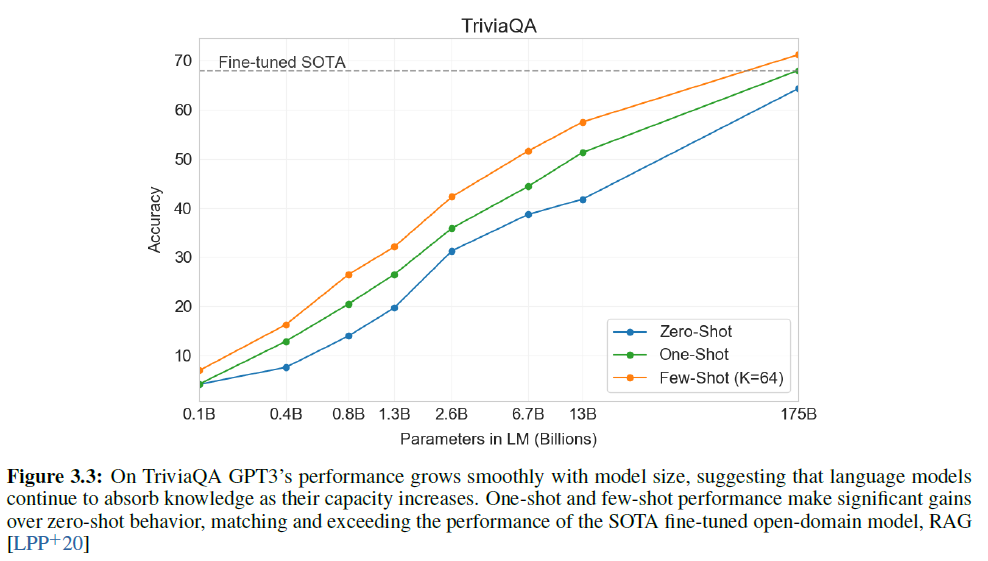
TriviaQA
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension은 650k개의 질문-답변-증거(인용구) triple를 포함하는 독해를 위한 데이터셋이다. 95k개의 질문-답변 쌍을 포함한다. 답변을 하기 위해서는 문장 여럿을 살펴봐야 한다.
Question: The Dodecanese Campaign of WWII that was an attempt by the Allied forces to capture islands in the Aegean Sea was the inspiration for which acclaimed 1961 commando film?
Answer: The Guns of Navarone
Excerpt: The Dodecanese Campaign of World War II was an attempt by Allied forces to capture the Italianheld Dodecanese islands in the Aegean Sea following the surrender of Italy in September 1943, and use them as bases against the German-controlled Balkans. The failed campaign, and in particular the Battle of Leros, inspired the 1957 novel The Guns of Navarone and the successful 1961 movie of the same name.
WebQuestions(WebQs)
Freebase를 사용하여 대답할 수 있는 6642개의 질문-답변 데이터셋이다. 2013년까지 웹에서 자주 질문이 이루어진 것들로 이루어져 있다.
targetValue: Jazmyn Bieber / Jaxon Bieber
utterance: What is the name of justin bieber brother?
Natural Questions(NQs)
구글 검색엔진에서 모아진 익명으로 이루어진 질의들로, 5개의 상위 결과에서 Wikipedia와 연관한 질문, 일반적으로 문단 수준인 긴 답변, 1개 또는 그 이상의 객체로 이루어진 짧은 답변으로 구성되며, 없을 경우 None으로 표시된다. 307k/7.8k/7.8k개의 train/dev/test 데이터가 있다.
Question: where is blood pumped after it leaves the right ventricle?
Short Answer: None
Long Answer: From the right ventricle , blood is pumped through the semilunar pulmonary valve into the left and right main pulmonary arteries ( one for each lung ) , which branch into smaller pulmonary arteries that spread throughout the lungs.
3.3. Translation
GPT-2에서는 용량 문제 때문에 영어만 존재하는 데이터셋을 만들기 위한 필터를 사용하였다. 그럼에도 다언어 역량을 가질 수 있음을 보였는데, GPT-3에서는 훨씬 더 커진 크기 덕분에 실제로 여러 언어에 대한 표현(representation)을 얻을 수 있게 되었다(물론, 연구로 더 많은 향상이 있을 수 있다). GPT-3 학습을 위해 사용된 Common Crawl 데이터는 사실 93%가 영어이지만 7%는 다른 언어를 포함한다(자세한 것은 여기서 볼 수 있음). 더 나은 번역 능력을 얻기 위해 분석을 영어 이외에도 널리 연구된 독일어와 루마니아어(Romanian)에 대해 수행했다.
기존에는 두 언어를 연결하기 위해 단일 언어 데이터셋의 쌍을 back-translation으로 사전학습을 결합시켜 사용했다. 이에 반해 GPT-3은 여러 언어들이 단어, 문장, 문서 단위로 자연스레 섞인 데이터를 그냥 학습하였다. 또한 어느 특별한 문제만을 위해 특별 제작되지 않았다.
결과는 기존 NMT 모델에 비해 좋지 않지만, 단 한 개의 예시만이 주어지는 task에서는 7 BLEU score만큼 향상되었으며 이전 연구와 거의 근접한 성능을 보여준다. 아래 그림들에서 자세한 결과를 볼 수 있다.
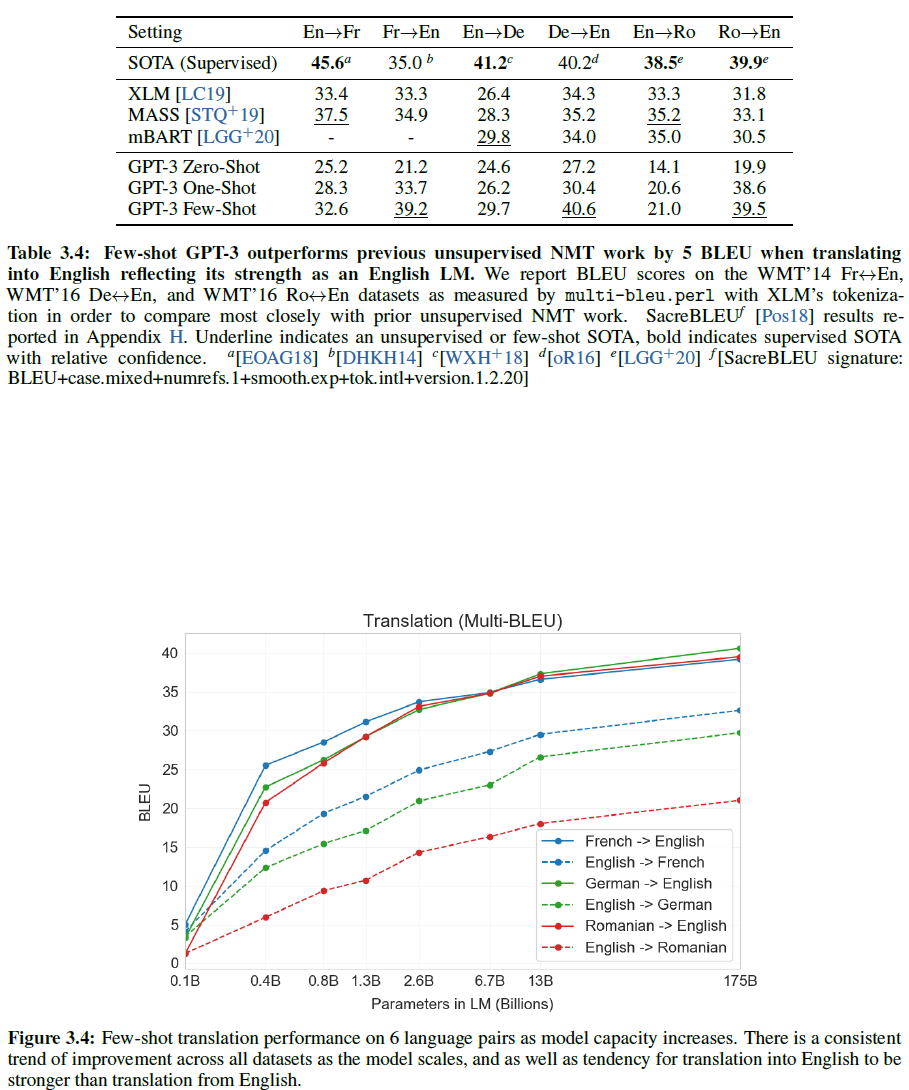
GPT-3은 다른 무감독 NMT에 비해 다른 언어 → 영어로의 번역은 아주 잘 하지만 그 반대는 상당히 성능이 낮다. 이는 GPT-2의 byte-level BPE tokenizer가 거의 영어에 맞춰져 있기 때문으로 보인다.
그리고, 여전히 모델이 커질수록 성능이 증가함에는 변함이 없다.
3.4. Winograd-Style Tasks
Winograd Schemas Challenge는 자연어 문장에서 특정 대명사가 어떤 대상을 지칭하는지를 판별하는 고전적인 자연어처리 문제로, 문법적으로는 (답이) 모호하지만 의미적으로는 (사람에게는) 명확한 문제이다. 최근에는 미세조정된 언어모델이 거의 사람 수준의 성능을 보였지만 더 어려운 버전인 Winogrande dataset에서는 여전히 사람에 비해 크게 뒤떨어지는 결과를 보였다.
GPT-3은 273개의 Winograd Schemas의 원래 세트에 대해 테스트를 진행하였으며, GPT-2에서 사용된 “partial evaluation” 방법을 사용했다. 이 세팅은 SuperGLUE benchmark와는 조금 다른데, 이진 분류로 표현되며 객체 추출이 필요하다.
Winograd에서, GPT-3은 zero/one/few-shot에서 각각 88.5%, 89.7%, 88.6%의 성능을 보였으며, 문맥 내 학습에서 크게 명확하진 않지만 모든 경우에서 SOTA 및 사람보다 조금의 차이밖에 나지 않는 결과를 얻었다.
여기서 약간의 데이터 오염 문제가 있었지만, 결과에 미친 영향은 미미하다.
더 어려운 버전인 Winogrande dataset에서는, zero/one/few-shot에서 각각 70.2%, 73.2%, 77.7%의 정확도를 보였다. 비교를 하자면, 미세조정된 RoBERTa가 79%를, SOTA가 84.6%(T5), 사람이 94.0%이다.
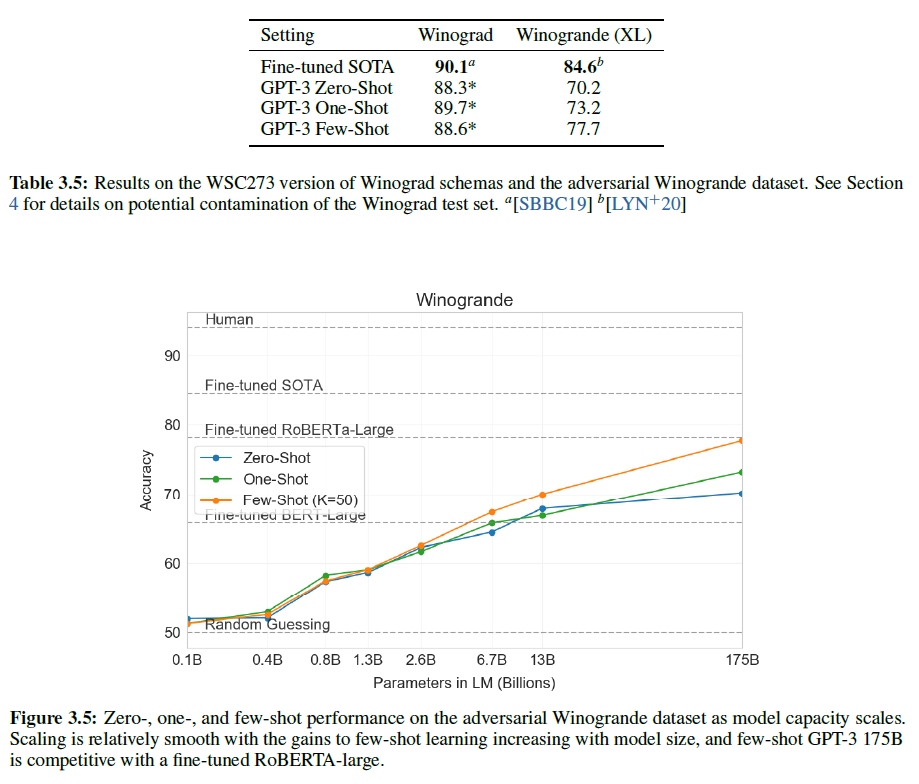
Winograd Schemas Challenge
Winograd Schemas Challenge은 튜링 테스트의 약점을 보완하고자 나온 데이터셋으로 어떤 대상이 어떠한지를 물을 때 적절한 대상을 찾는 문제이다. The trophy doesn’t fit in the brown suitcase because it’s too big. What is too big?
Answer 0: the trophy
Answer 1: the suitcase
Joan made sure to thank Susan for all the help she had given. Who had given the help?
Answer 0: Joan
Answer 1: Susan
Winogrande dataset
Winogrande dataset은 44k개의 문제를 포함하여 기존 WSC보다 더 어렵고 규모가 큰 데이터셋이다. 언어적으로 편향되어 있기 때문에(어떤 단어는 특정 단어들과 같이 나올 확률이 높은 등) 언어모델이 쉽게 판별할 수 있는 질문들은 제거되었다.

3.5. Common Sense Reasoning
이제 문장 완성, 독해, 광범위한 지식 질답과는 다른 물리학적/과학적 추론을 다루고자 한다. PhysicalQA(PIQA)는 어떻게 물리학적으로 세계가 움젝이고 세상에 대한 현실 이해를 관찰하는 것을 목적으로 한 상식 질문을 묻는 데이터셋이다.
GPT-3은 zero/one/few-shot에서 81.0%, 80.5%, 82.8%의 성능을 보였으며, 이는 이전의 SOTA였던 미세조정된 RoBERTa의 79.4%보다 더 높은 수치이다.
PIQA는 상대적으로 모델 크기가 커져도 성능이 많이 향상되지 않으며 또한 사람에 비하면 10% 이상 낮지만, GPT-3의 zero-shot 결과는 현재 SOTA를 뛰어넘는다. 참고로 PhysicalQA에서도 데이터 오염 문제가 있었다.
ARC(AI2 Reasoning Challenge)는 3~9학년(초등~중등)의 과학 시험에서 모은 7787개의 다지선다형 문제 데이터셋이다. 이 데이터셋의 “Challenge” 버전은 단순 통계적 혹은 정보 검색만으로는 맞게 답할 수 없는 것들만 필터링한 것으로서 GPT-3은 zero/one/few-shot에서 51.4%, 53.2%, 51.5%의 성능을 보였다. 이는 UnifiedQA에서 미세조정된 RoBERTa가 보인 55.9%와 견줄 수 있는 수준이다.
이 데이터셋의 “easy” 버전에서는 GPT-3은 zero/one/few-shot에서 68.8%, 71.2%, 70.1%의 성능을 보여 RoBERTa를 살짝 앞질렀다. 그러나 이는 UnifiedQA에 비하면 27%/22%만큼이나 낮은 수치이다.
초등 수준의 과학적 사실을 다루는 질문으로 구성된 OpenBookQA에서는, zero~few-shot에서 상당한 발전을 보였으나 SOTA에 비하면 20점 이상 낮은 수치이다. few-shot 성능은 미세조정된 BERT Large와 비슷하다.
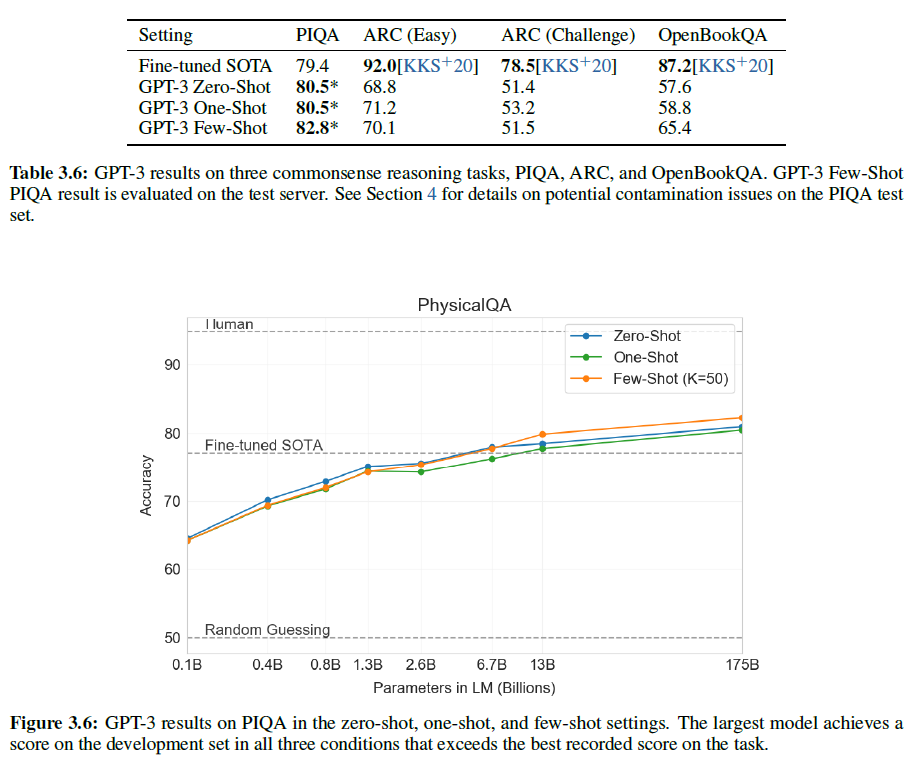
전체적으로, PIQA, ARC에서는 큰 향상이 없었으나, OpenBookQA에서는 꽤 진전이 있었다.
PhysicalQA(PIQA)
PhysicalQA(PIQA): Reasoning about Physical Commonsense in Natural Language은 어떤 (실생활) 목표가 자연어로 주어지면, 모델은 적절한 해답을 선택해야 한다.
Goal: To separate egg whites from the yolk using a water bottle, you should…
a. Squeeze the water bottle and press it against the yolk. Release, which creates suction and lifts the yolk.
b. Place the water bottle and press it against the yolk. Keep pushing, which creates suction and lifts the yolk.
ARC(AI2 Reasoning Challenge)
ARC(AI2 Reasoning Challenge): Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge은 Challenge set과 Easy set으로 구분되어, Challenge set은 정보기반 알고리즘과 단어 co-occurence 알고리즘으로 제대로 답변할 수 없는 질문들로만 구성되어 있다.
What is a worldwide increase in temperature called?
(A) greenhouse effect
(B) global warming
(C) ozone depletion
(D) solar heating
OpenBookQA
OpenBookQA : Can a Suit of Armor Conduct Electricity A New Dataset for Open Book Question Answering은 1326개의 초등 수준 과학적 사실에 기반하였으며 질문의 수는 6k 정도이다.
Question: Which of these would let the most heat travel through?
A) a new pair of jeans.
B) a steel spoon in a cafeteria.
C) a cotton candy at a store.
D) a calvin klein cotton hat.
Science Fact: Metal is a thermal conductor.
Common Knowledge: Steel is made of metal. Heat travels through a thermal conductor.
3.6. Reading Comprehension
추상적 / 다지선다 등 5개의 데이터셋에 대해 독해력을 측정한다. 여러 다른 답변 형식에서도 데이터셋간 장벽을 뛰어넘는 GPT-3의 범용성을 확인하였다.
- 자유 형식 대화 데이터셋인 CoQA에서 최고의 성능(사람보다 3 point 낮음)과,
- 구조화된 대화와 교사-학생 상호작용의 답변 선택 모델링을 요구하는 QuAC에서는 ELMo baseline보다 13 F1 score가 낮은 나쁜 성능을 보여주었다.
- 독해 문맥에서 이산적 추론과 산술능력을 평가하는 데이터셋인 DROP에서는 GPT-3이 few-shot에서 미세조정된 BERT baseline을 뛰어넘었지만 SOTA나 사람에 비하면 아주 못 미치는 성적을 거두었다.
- SQuAD 2.0에서는 zero-shot에서 10 F1(69.8) score를 향상시켰고 이는 원 논문의 가장 좋은 미세조정 모델보다 약간 더 높은 점수이다.
- 중/고등 다지선다형 영어시험 문제를 모은 RACE에서는 상당히 약한 모습을 보였다(SOTA에 비해 45%나 낮음).
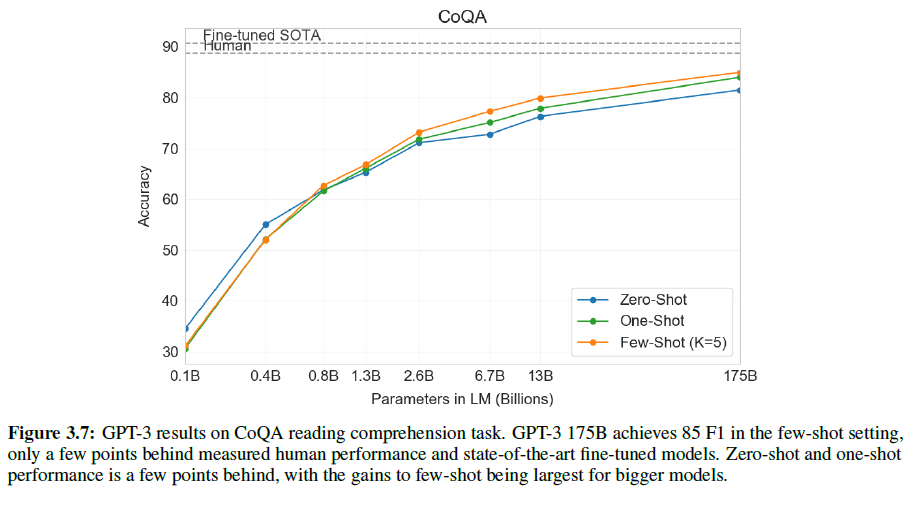
CoQA: A Conversational Question Answering Challenge
Conversational Question Answering systems을 만드는 데 필요한 대규모 데이터셋으로 coca(코카)라 읽는다. 텍스트 구절을 이해하고 대화에서 나타나는 상호 연결된 질문들에 대답하는 능력을 측정한다. 127k개의 질문과 8k개의 대화문을 포함한다.
Jessica went to sit in her rocking chair. Today was her birthday and she was turning 80. Her granddaughter Annie was coming over in the afternoon and Jessica was very excited to see her. Her daughter Melanie and Melanie’s husband Josh were coming as well. Jessica had . . . Q1: Who had a birthday?
A1: Jessica
R1: Jessica went to sit in her rocking chair. Today was her birthday and she was turning 80. Q2: How old would she be?
A2: 80
R2: she was turning 80
…
Q5: Who?
A5: Annie, Melanie and Josh
R5: Her granddaughter Annie was coming over in the afternoon and Jessica was very excited to see her. Her daughter Melanie and Melanie’s husband Josh were coming as well.
QuAC : Question Answering in Context
14k개의 정보를 찾는(information-seeking) QA 대화로 총 100k개의 질문을 포함하는 Question Answering in Context 데이터셋이다.
Section: Daffy Duck, Origin & History
STUDENT: What is the origin of Daffy Duck?
TEACHER: → first appeared in Porky’s Duck Hunt
STUDENT: What was he like in that episode?
TEACHER: → assertive, unrestrained, combative
STUDENT: Was he the star?
TEACHER: → No, barely more than an unnamed bit player in this short
STUDENT: Who was the star?
TEACHER: → No answer
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
Discrete Reasoning Over the content of Paragraphs의 약자로 문단 내용의 이산적 추론능력을 필요로 하는 독해력 측정용 benchmark dataset이다. Subtraction, Comparison, Selection, Addition, Count and Sort, Conference Resolution, Other Arithmetic, Set of spans, Other 등의 카테고리로 나뉘어 총 96k개의 질문을 포함한다.
Reasoning: Subtraction (28.8%)
Passage(some parts shortened): That year, his Untitled (1981), a painting of a haloed, black-headed man with a bright red skeletal body, depicted amid the artists signature scrawls, was sold by Robert Lehrman for $16.3 million, well above its $12 million high estimate.
Question: How many more dollars was the Untitled (1981) painting sold for than the 12 million dollar estimation?
Answer: 4300000
BiDAF: $16.3 million
Know What You Don’t Know: Unanswerable Questions for SQuAD:
SQuAD 2.0(Stanford Question Answering Dataset)은 기존 독해력 측정 데이터셋의 대답 가능한 질문이나 쉽게 판별할 수 있는 대답 불가능한 질문이라는 약점을 보완하여 사람이 생성한 질문으로 구성된다. 모델은 정답을 맞추는 것만 아니라 답변 중에 정답이 있는지도 판별해야 한다.
Article: Endangered Species Act
Paragraph: “…Other legislation followed, including the Migratory Bird Conservation Act of 1929, a 1937 treaty prohibiting the hunting of right and gray whales, and the Bald Eagle Protection Act of 1940. These later laws had a low cost to society—the species were relatively rare—and little opposition was raised.”
Question 1: “Which laws faced significant opposition?”
Plausible Answer: later laws
Question 2: “What was the name of the 1937 treaty?”
Plausible Answer: Bald Eagle Protection Act
RACE: Large-scale ReAding Comprehension Dataset From Examinations:
중국의 중/고등(12~18세) 영어시험으로부터 모은 28k개의 구절(passages)와 100k 정도의 (영어교사가 만든) 질문들로 구성된 데이터셋으로 이해력과 추론 능력을 평가하기 위한 다양한 주제들로 구성되어 있다.

자유 형식 대화 데이터셋인 CoQA에서 최고의 성능(사람보다 3 point 낮음)과, 구조화된 대화와 교사-학생 상호작용의 답변 선택 모델링을 요구하는 QuAC에서는 ELMo 기준보다 13 F1 score가 낮은 나쁜 성능을 보여주었다.
3.7. SuperGLUE
조금 더 많은 NLP task에 대한 결과를 모으고 BERT와 RoBERTa와 더 체계적으로 비교하기 위해 SuperBLUE benchmark 테스트도 진행하였다. few-shot에서는 모든 task에 대해 32개의 예제를 사용하였고 이는 training set에서 무작위로 선택하였다. WSC와 MultiRC를 제외하고는 각 문제당 문맥에서 새로운 예제를 선택했다. 위 두 데이터셋에서는 training set에서 무작위로 선택한 것과 같은 세트를 사용했다.
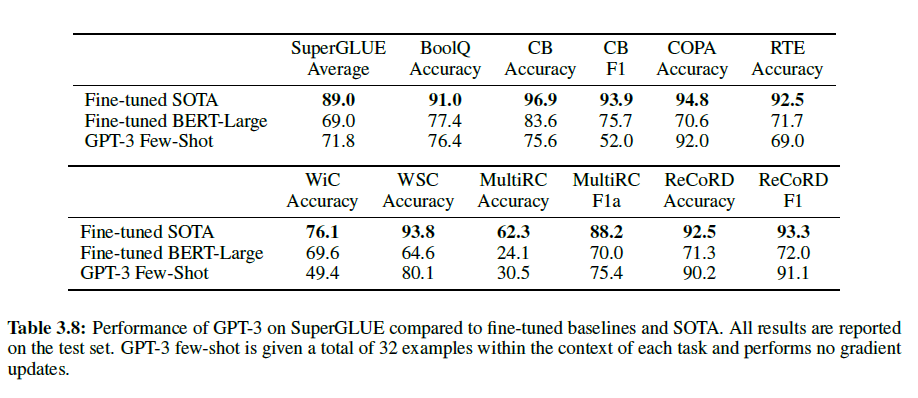
GPT-3으 몇몇 데이터셋에서는 SOTA에 근접한 결과를 얻었으나 그렇지 못한 데이터셋도 여럿 있는 것을 볼 수 있다. 특히 두 문장에서 사용된 동일한 철자의 단어가 같은 의미로 사용되었는지를 보는 WiC dataset에서는 49.4%로 찍는 거랑 다를 바가 없었다.
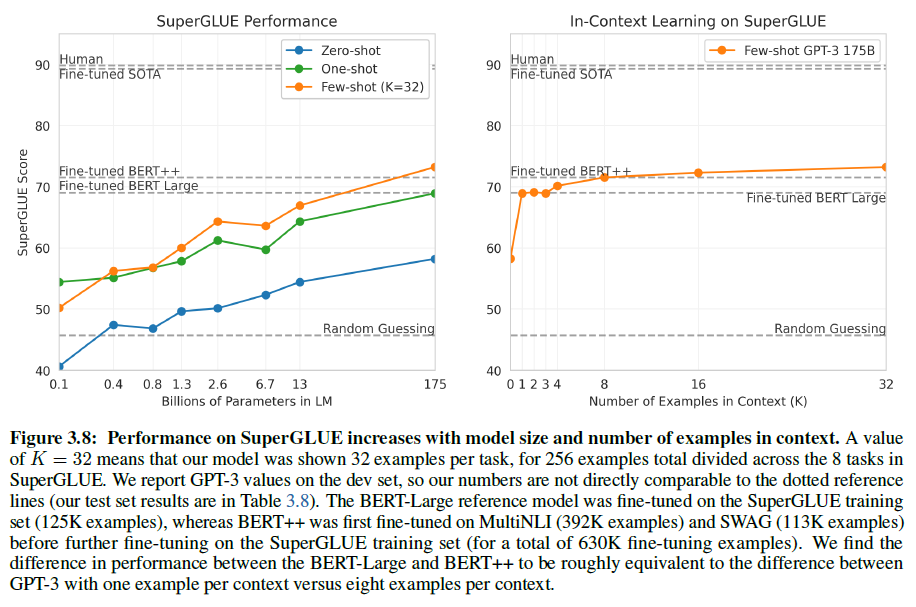
그리고 모델의 크기가 커질수록, few-shot에 사용되는 예제의 수가 많을수록 성능이 증가함을 볼 수 있다.
3.8. NLI
Natural Language Inference (NLI)은 두 문장 간의 관계를 이해하는 것을 측정한다. 실제로는, 보통 2~3개의 분류 문제로 모델은 두 번째 문장이 첫 번째 문장과 같은 논리를 따르는지, 모순되는지, 혹은 그럴지도 모를지(중립적)를 판별한다. SuperGLUE는 NLI dataset으로 이진 분류 RTE를 포함한다. RTE에서는 가장 큰 모델인 GPT-3만 찍는 것보다 나은 56%를 기록하였으나 few-shot에서는 single-task 미세조정 BERT Large와 비슷하다.
그리고 ANLI 데이터셋에 대해서도 테스트를 진행하였는데, few-shot에서조차 GPT-3보다 작은 모델은 전부 형편없는 모습(~33%)을 보여준다. 전체 결과는 아래 그림과 Appendix H에서 볼 수 있다.
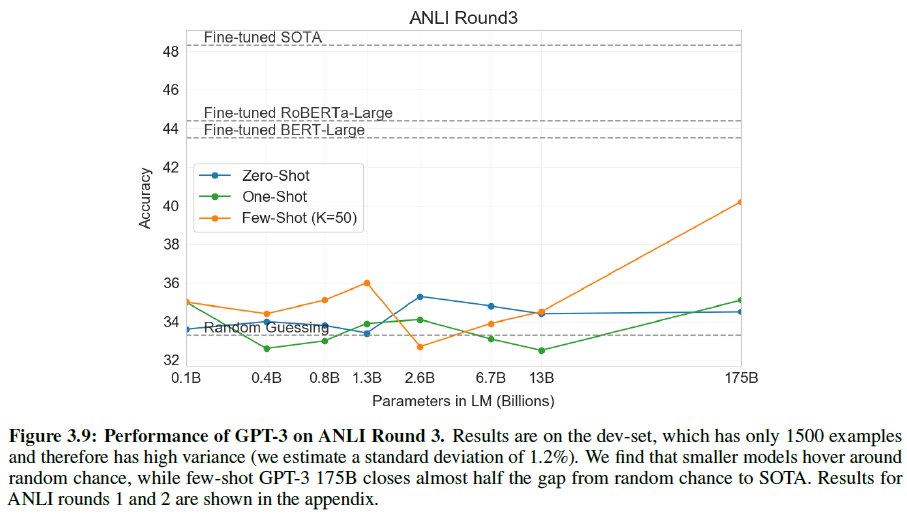
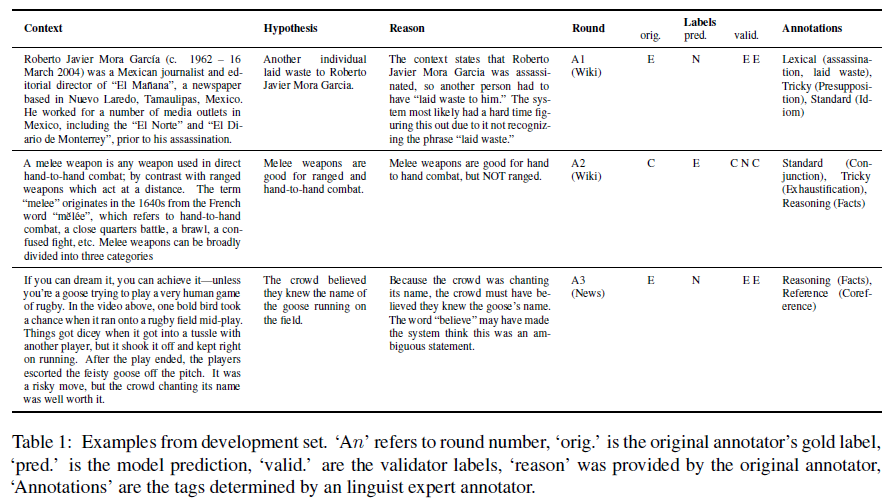
Adversarial NLI: A New Benchmark for Natural Language Understanding:
적대적으로 만들어진 자연어 추론 문제를 3 round(R1, R2, R3)에 걸쳐 진행하는 데이터셋으로 Context, Hypothesis, Reason, Round, Labels(orig, pred, valid), Annotations으로 구성된다.
3.9. Synthetic and Qualitative Tasks
GPT-3의 few-shot(혹은 zero나 one) 능력의 범위를 보려면 즉석 계산적 추론이나, 새로운 패턴을 찾아내거나, 새 task에 빠르게 적응(적용)하는지를 측정해보면 된다.
그래서 세 가지를 측정한다: 산술능력, 단어 재조합, SAT 유추.
3.9.1 Arithmetic
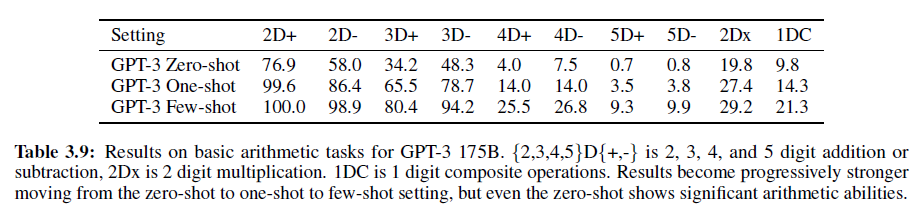
10가지 경우를 테스트하였는데, 각 숫자는 각 범위 내에서 동일한 확률로 선택되었다.
- 2자리 덧셈: “Q: What is 48 plus 76? A: 124.”
- 2자리 뺄셈: “Q: What is 34 minus 53? A: -19”
- 3, 4, 5자리 덧셈/뺄셈
- 2자리 곱셈: “Q: What is 24 times 42? A: 1008”
- 괄호를 포함한 1자리 복합연산: “Q: What is 6+(4*8)? A: 38”
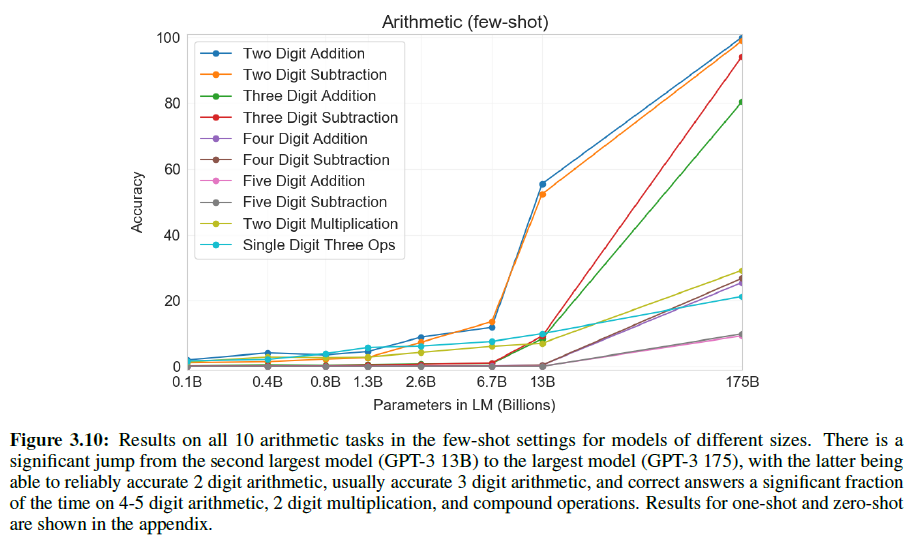
2/3자리 계산은 거의 100%에 가까운 정확도를 보여주지만, 자리수가 많아질수록 성능은 떨어졌다. 또한, 2자리 곱셈에서는 29.2%, 1자리 복합연산은 21.3%의 정확도를 얻었다(few-shot).
종합적으로, GPT-3은 보통 수준의 복잡한 산술연산에서 합리적인 수준의 성능을 보였다.
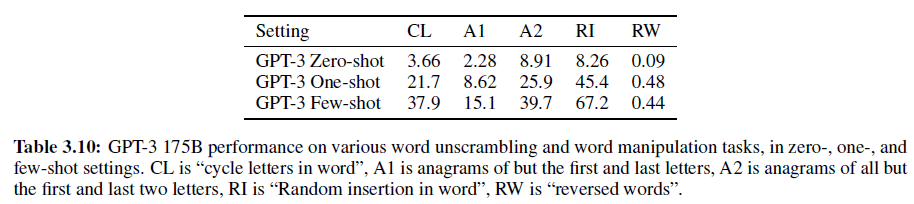
3.9.2 Word Scrambling and Manipulation Tasks
적은 수의 예로부터 새로운 symbolic manipulation을 학습하는 능력을 측정하기 위해 다음 5가지 “문자조합” task를 설정했다.
- 단어 내 철자를 회전시켜 원래 단어를 만들기(Cycle letters in word (CL)). lyinevitab = inevitably
- 처음과 마지막을 제외한 철자가 뒤섞여 있을 때 원래 단어 만들기(Anagrams of all but first and last characters (A1)). criroptuon = corruption
- A1과 비슷하지만 처음/마지막 각 2글자가 섞이지 않음(Anagrams of all but first and last 2 characters (A2)). opoepnnt → opponent
- 구두점들과 빈칸이 각 철자 사이에 올 때 원래 단어 만들기(Random insertion in word (RI)). s.u!c/c!e.s s i/o/n = succession
- 거꾸로 된 단어에서 원래 단어 만들기(Reversed words (RW)). stcejbo → objects
각 1만 개의 예제를 만들기 위해 4~15글자 사이의 가장 빈도가 높은 단어들을 선정하였다.
few-shot 결과는 아래와 같다. 모델의 크기가 커질수록 성능도 조금씩 증가한다.
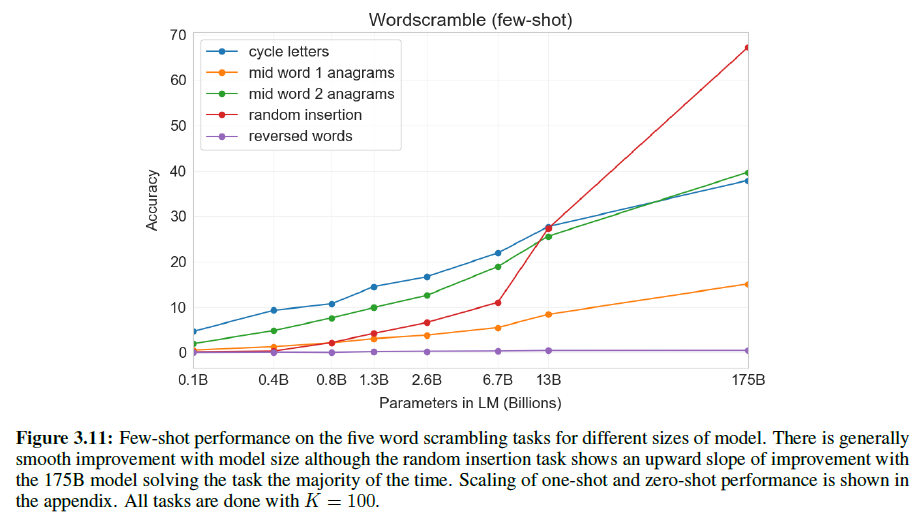
어떤 모델도 단어를 뒤집는 RW task에 성공하지 못했다. 또한 one/zero-shot에서는 성능이 매우 떨어진다.
여기서 “문맥 내 정보”는 큰 모델일수록 더 잘 활용한다는 것을 보였다.
또한, 언어모델의 이러한 성공은 단지 BPE token을 잘 쓰는 것 뿐 아니라 그 하부구조를 잘 이해하고 분석하였음을 알 수 있다. 그리고 CL, A1, A2 task는 전단사상(bijective)이 아니기 때문에(즉, 하나로 결정된 것이 아니기에) 자명하지 않은 패턴매칭과 계산적인 능력에서 연관이 있다고 할 수 있다.
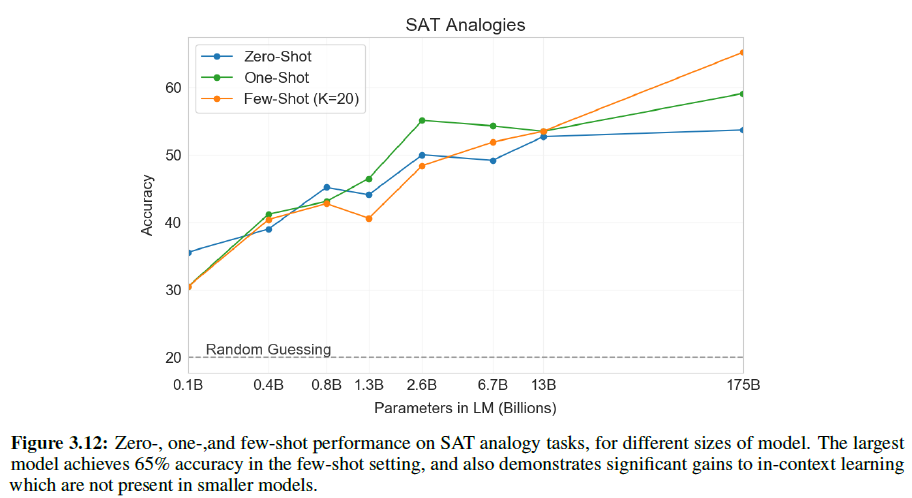
3.9.3 SAT Analogies
텍스트의 전형적인 분포와 연관된 무언가 흔치 않은 다른 task에 테스트하기 위해, 374개의 “SAT analogy” 문제를 모았다. 예시는 다음과 같다:
Audacious is to boldness as
(a) sanctimonious is to hypocrisy,
(b) anonymous is to identity,
(c) remorseful is to misdeed,
(d) deleterious is to result,
(e) impressionable is to temptation”
5개의 단어 쌍 중 주어진 단어 쌍과 같은 관계를 갖는 정답지를 골라야 한다(정답은 a이다).
여기서 GPT-3은 zero/one/few-shot에서 각각 53.7%, 59.1%, 65.2%의 성능을 보였고, 대학 졸업자 평균이 57%(찍으면 20%)이다.
아래 그림에서 보듯 1750억 개 짜리 모델은 130억 개의 모델보다 10% 가량 더 성능이 높다.
3.9.4 News Article Generation
생성적 언어모델을 질적으로 테스트하기 위한 방법으로 뉴스기사로 첫 문장을 준 뒤 이후 문장을 생성하는 식으로 측정해 왔다. GPT-3을 학습한 데이터셋은 뉴스기사에 별 비중을 두지 않읐으므로 무조건으로 뉴스기사를 생성하는 것은 비효율적이다. 그래서 GPT-3에서는 3개의 이전 뉴스기사를 모델의 문맥에 포함시켜 few-shot 학습능력을 측정했다. 제목과 부제목이 주어지면, 모델은 “뉴스” 장르에서 짧은 기사를 생성할 수 있다.
GPT-3이 생성한 기사가 사람이 쓴 것과 구별되는지를 사람이 얼마나 잘 구별하는지를 측정하였다. 이를 통해 GPT-3의 뉴스기사 생성능력을 볼 수 있다.
사람이 판별할 때는 ‘사람이 쓴 기사’와 ‘기계가 생성한 기사’ 두 개를 보고, 다음 5가지 중에 고른다: 1) 확실히 사람이 썼다. 2) 사람이 쓴 것 같다. 3) 잘 모르겠다. 4) 기계가 쓴 것 같다. 5) 확실히 기계가 썼다.
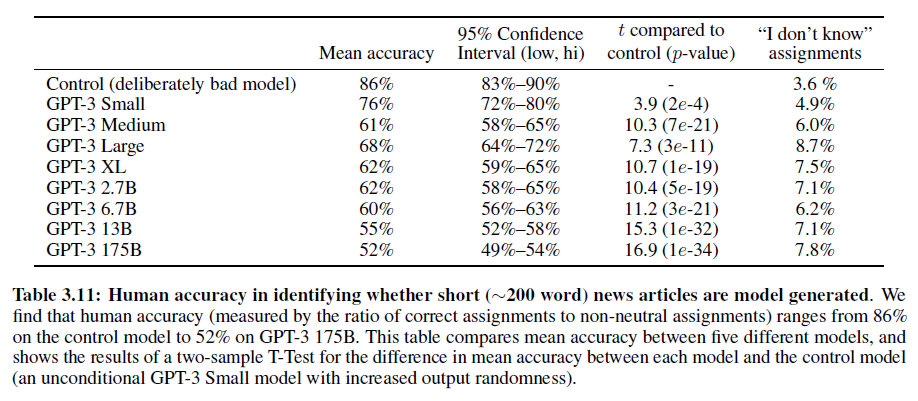
정답률이 50%에 근접하면 기계가 썼는지 사람이 썼는지 분간이 안 된다는 뜻이다(기계가 사람만큼 잘 썼다/또는 사람처럼 비슷하게 썼다).
물론 모델이 커질수록 구별하기는 점점 더 어려워진다.
아래는 GPT-3이 생성한 기사이다. 구분하기 가장 어려운 것과 쉬운 것을 보여주고 있다.

3.9.5 Learning and Using Novel Words
발달적 언어학에서 연구되는 한 task는 새로운 단어를 학습하고 사용하는 능력을 측정한다(예를 들면 단 한 번 정의된 단어를 보고 나서 사용하거나, 한 번의 용례로 단어의 의미를 유추하는 것).
테스트는 다음과 같이 했다. “Gigamuru”와 같이 실제로 없는 단어를 정의하고, 이를 문장에서 사용해 보게 하였다. 1~5개의 없는 단어를 정의하고 문장에서 사용하여, 이 task는 one/few-shot 세팅으로 구성된다. 모든 정의는 사람이 직접 하였고, 첫 번째 답은 사람이 정의하였고, 나머지는 GPT-3이 한 것이다:
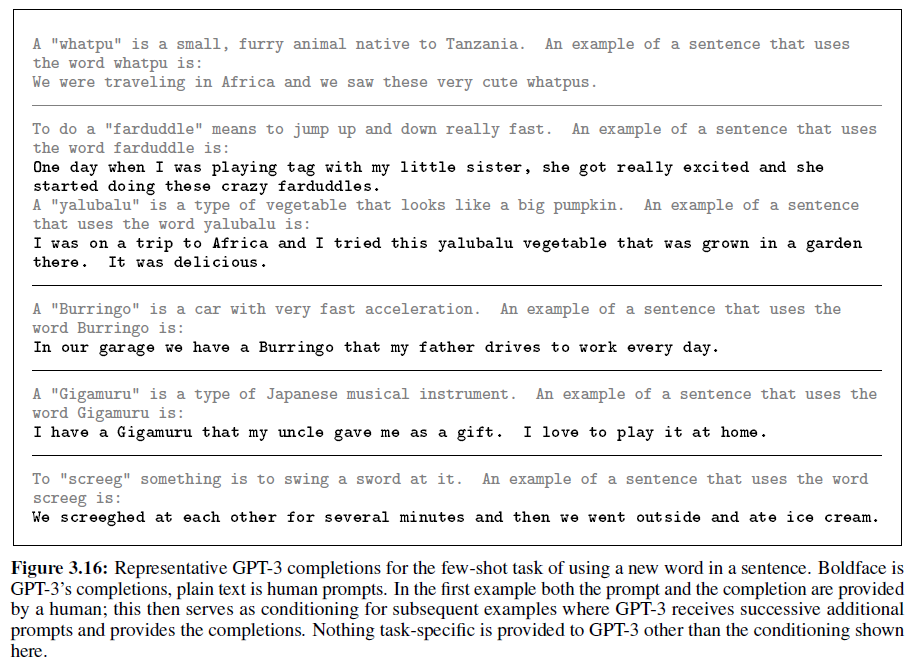
모든 경우에서 정확하거나 합리적인 수준으로 사용하였음을 볼 수 있다. 적어도, GPT-3은 새로운 단어를 사용하는 능력은 꽤 수준이 있는 것 같다.
3.9.6 Correcting English Grammar
few-shot에 적합한 또 다른 task는 영문법을 교정하는 것이다. 다음과 같이 few-shot 예시를 주었다:
"Poor English Input: <sentence>\n Good English Output: <sentence>".
결과는 아래 그림에서 볼 수 있다.

4. 벤치마크를 외웠는지 측정하고 예방하기(Measuring and Preventing Memorization Of Benchmarks)
5. 한계(Limitations)
6. 광범위한 영향(Broader Impacts)
7. 관련 연구(Related Work)
이 논문
8. 결론(Conclusion)
큰 크기
Acknowledgements
언제나 있는 감사의 인사
Appendix A: Details of Common Crawl Filtering
Appendix B: Details of Model Training
Appendix C: tails of Test Set Contamination Studies
Appendix D: Total Compute Used to Train Language Models
Appendix E: Human Quality Assessment of Synthetic News Articles
Appendix F: Additional Samples from GPT-3
Appendix G: Details of Task Phrasing and Specifications
Appendix H: Results on All Tasks for All Model Sizes
Refenrences
논문 참조. 많은 레퍼런스가 있다.
Citation
@misc{brown2020language,
title={Language Models are Few-Shot Learners},
author={Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert-Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and Christopher Hesse and Mark Chen and Eric Sigler and Mateusz Litwin and Scott Gray and Benjamin Chess and Jack Clark and Christopher Berner and Sam McCandlish and Alec Radford and Ilya Sutskever and Dario Amodei},
year={2020},
eprint={2005.14165},
archivePrefix={arXiv},
primaryClass={cs.CL}
}