
ERNIE 논문 설명(ERNIE - Enhanced Language Representation with Informative Entities)
01 Jul 2021 | Paper_Review NLP ERNIE목차
- ERNIE: Enhanced Language Representation with Informative Entities
이 글에서는 ERNIE 타이틀을 달고 나온 Tsinghua University에서 발표한 ERNIE: Enhanced Language Representation with Informative Entities 논문을 살펴본다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
ERNIE: Enhanced Language Representation with Informative Entities
논문 링크: ERNIE: Enhanced Representation through Knowledge Integration
Official Code: Github
초록(Abstract)
대규모 말뭉치에서 사전학습하는 BERT같은 자연어표현 모델은 텍스트로부터 충분한 의미적 패턴을 잘 잡아내며 다양한 NLP 문제에서 미세조정을 통해 일관되게 성능이 향상되는 모습을 보인다.
그러나, 현존하는 자연어 모델은 더 나은 언어 이해를 위한 풍부한 구조적 지식을 제공할 수 있는 지식 그래프(Knowledge Graphs, KGs)를 거의 고려하지 않는다. 우리는 KGs 내의 유익한 entity들이 외부 지식을 통해 언어표현을 향상시킬 수 있다고 주장한다. 본 논문에서, 대규모 텍스트 말뭉치와 KGs를 사용하여 향상된 언어표현 모델 ERNIE를 학습하며 이는 어휘적, 의미적, 지식 정보를 동시에 학습할 수 있다.
실험 결과는 ERNIE가 다양한 지식기반 문제에서 상당한 발전을 이루었고 또한 다를 NLP 문제에서도 SOTA 모델 BERT에 필적할 만하다.

1. 서론(Introduction)
Feature 기반이나, 미세조정 등을 사용하는 언어표현 사전학습 모델들은 텍스트로부터 풍부한 언어표현을 얻을 수 있고 이는 많은 자연어처리 문제에서 상당한 효과를 거두었다. 최근 제안되었던 BERT와 그 응용 모델들은 named entity, 질답, 자연어추론, 텍스트 분류 등 많은 자연어 문제에서 뛰어난 성과를 보여주었다.
그러나 이러한 언어표현 사전학습 모델은 언어이해를 위해 필요한 연관 지식을 무시한다. 아래 그림에서 보듯이, Blowin’ in the Wind and Chronicles: Volume One are song and book라는 지식 없이 Bob Dylan의 직업 songwriter and writer를 식별하는 것은 어려운 일이다. 더욱이, 관계 분류 문제에서 composer과 author와 같은 fine-grained 관계를 찾는 것은 거의 불가능하다. UNK wrote UNK in UNK와 같은 문장은 언어표현 사전학습 모델에게 구문으로 모호하다. 따라서, 풍부한 지식 정보를 활용하는 것이 언어이해에 도움을 주고 다양한 지식기반 문제에서 이득을 가져다줄 것이다.
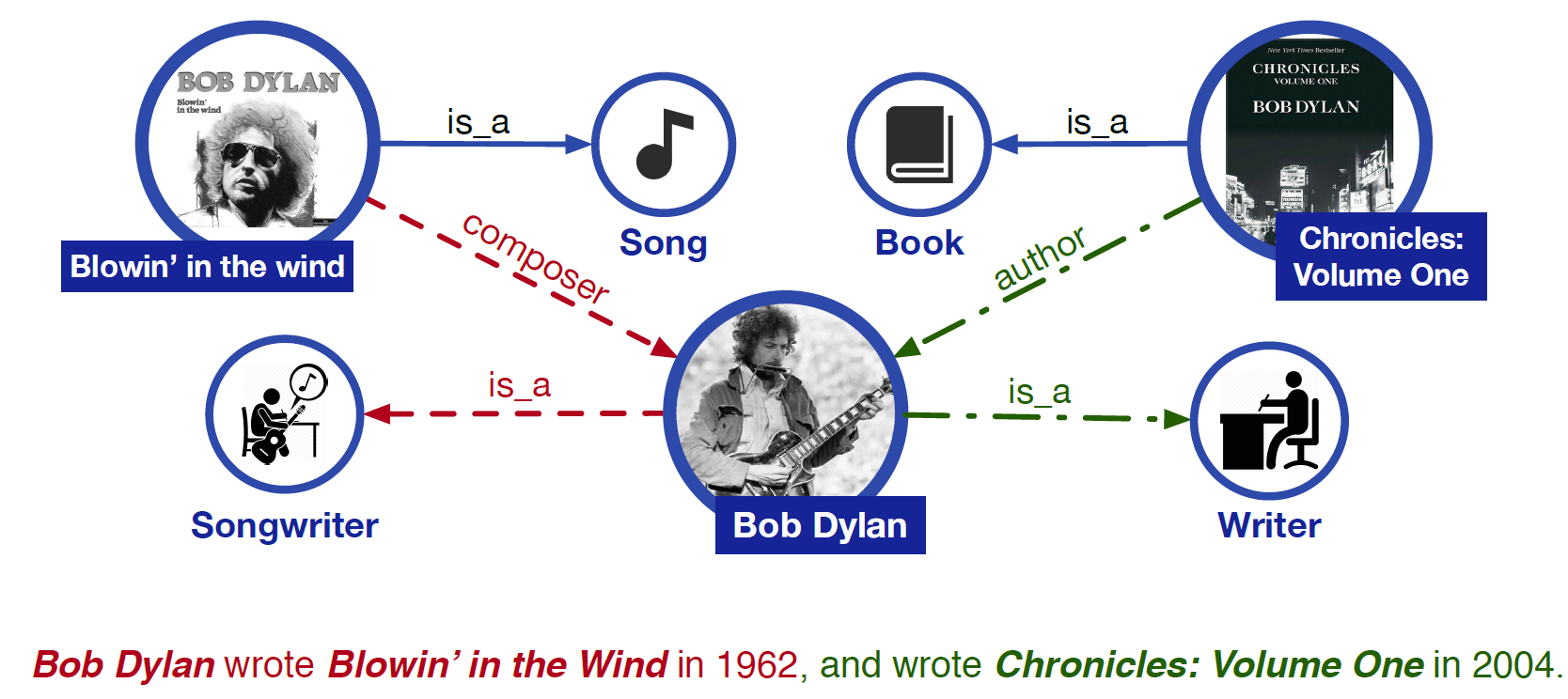
언어표현 모델에 외부 지식을 잘 포함시키려면 다음 두 가지를 해결해야 한다.
- 구조화된 지식 Encoding
- 주어진 텍스트와 관련하여 효율적으로 추출하고 언어표현 모델을 위해 KGs에서 유용한 정보를 찾는 것은 중요한 문제이다.
- 다차원적 정보 융합
- 언어표현을 위한 사전학습 절차는 지식표현과는 상당히 다른데, 2개의 독립적인 벡터공간을 다루기 때문이다.
어떻게 특별한 사전학습 목적함수를 어휘적, 구문, 지식정보와 융합하는 것은 또 다른 도전적인 과제이다.
위와 같은 문제를 극복하기 위해 ERNIE(Enhanced Language RepresentatioN with Informative Entities)를 제안한다. 대규모 말뭉치와 KGs를 모두 사용한다.
- 지식 정보를 추출하고 인코딩하기 위해, 텍스트에서 named entity(명명 객체)를 구분하고 KGs 안의 해당하는 entity를 언급하는 것과 묶는다. KGs의 그래프 기반 사실들을 직접 사용하기보다는 TransE를 사용하여 그래프 구조를 인코딩하고 지식 embedding을 ERNIE의 입력으로 사용한다. 텍스트와 KGs 사이의 alignment에 기반하여 entity 표현을 통합하고 의미 모듈로 보낸다.
- BERT와 비슷하게 maksed 언어모델을 적용하여 사전학습 목적함수로 다음 문장 예측을 사용한다. 텍스트와 지식 feature의 융합을 위해 named entity alignment의 일부를 임의로 masking하고 alignment를 완성하도록 모델을 학습시킨다. 오직 지역적 문맥만을 활용하는 기존의 목적함수와는 다르게 본 모델에서는 token과 entity를 모두 예측하도록 문맥과 지식 정보를 모두 사용한다.
실험은 지식기반 자연어처리 문제, entity typing과 관계분류(relation classification)에 대해 진행하였다. 결과는 ERNIE가 어휘적, 구문, 의미정보를 최대한 사용하여 SOTA인 BERT를 압도하는 것을 보여주었다. 또한 다른 NLP 문제에도 실험하여 충분히 괜찮은 결과를 얻었다.
2. 관련 연구(Related Work)
단어를 분산표현(distributed representations)으로 변환하는 feature 기반 접근법이 2008~2018년까지 있었다. 텍스트 말뭉치를 갖고 사전학습 목적함수를 통해 학습하였으나 이전에는 단어의 다의성(polysemy)으로 인해 부정확했다. 2018년에는 문맥을 고려하여 이를 어느 정도 해결한 ELMo가 발표되었다.
사전학습에 더해 미세조정을 수행하는 방법으로 BERT, GPT2 등이 제안되어 다양한 자연어처리 문제에서 뛰어난 성과를 보였다.
이러한 feature 기반 및 미세조정 언어표현 모델은 상당한 성과를 보여주었으나 지식 정보를 활용하지 않는 단점이 있다. 외부 지식정보를 주입하는 방식으로 독해, 기계번역, 자연어추론 등에서 많은 논문들이 발표되었다. 그리고 여기서 우리는 외부 지식정보를 사용하는 것이 기존의 사전학습 모델에 도움이 될 것을 주장한다. 본 논문에서는 말뭉치와 KGs를 모두 활용, BERT에 기반하여 향상된 언어표현을 학습한다.
3. 방법론(Methodology)
3.1절은 표기법, 3.2절은 전체 구조, 3.4절은 사전학습 task, 3.5절은 미세조정 세부를 다룬다.
3.1. Notations
$n$은 token sequence의 길이, $m$은 entity sequence의 길이라 할 때 token sequence와 entity sequence는 다음과 같이 나타낸다. 모든 token이 KGs의 entity와 align되는 것은 아니므로 $n \ne m$일 수 있다.
\[\lbrace w_1, ..., w_n\rbrace , \lbrace e_1, ..., e_m\rbrace\]모든 token을 포함하는 사전을 $\mathcal{V}$, KGs의 모든 entity를 포함하는 entity list를 $\mathcal{E}$라 한다. 어떤 token $w \in \mathcal{V}$가 해당하는 entity $e \in \mathcal{E}$를 가질 때, alignment는 $f(w) = e$로 정의한다. 그림 2에서 보듯이 entity는 named entity phrase에서 첫 번째 token으로 정한다.
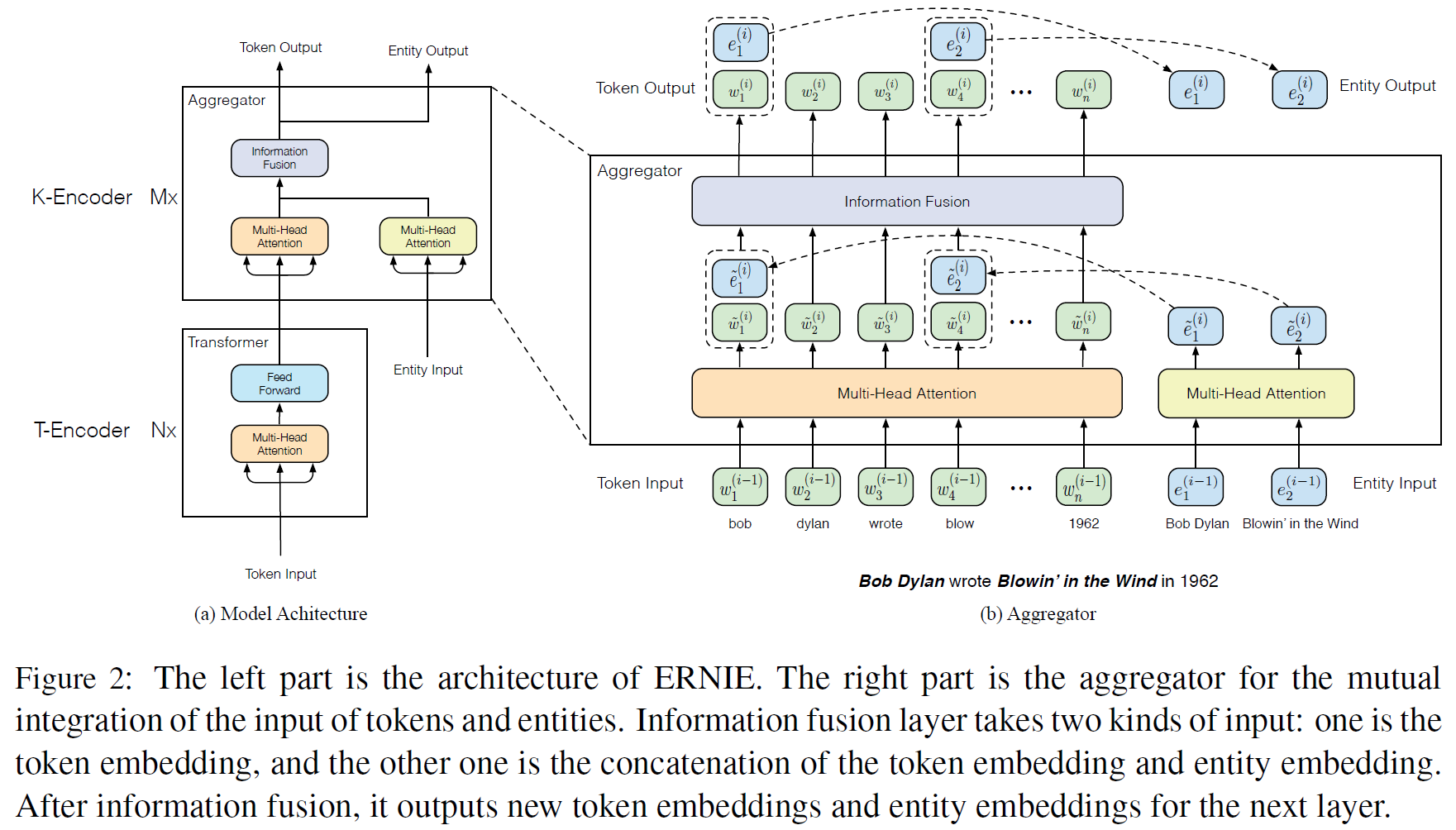
3.2. Model Architecture
2개의 모듈을 쌓아 만들었다.
- 아래쪽에 있는 textual encoder(
T-Encoder)는 주어진 token에서 기본적인 어휘적, 문맥적 정보를 얻는다. - 위쪽의 knowledgeable encoder(
K-Encoder)는 token에서 유래한 추가적인 지식 정보와 아래 layer의 textual 정보를 통합한다. 즉 token과 entity라는 다차원적 정보를 통합된 feature 공간에 표현할 수 있게 된다.
T-Encoder layer의 수를 $N$, K-Encoder layer의 수를 $M$이라 한다.
구체적으로, token sequence와 entity sequence가 주어지면, textual encoder는 먼저 각 token에 대해 token/segment/positional embedding을 합하고 어휘적, 구문 feature를 계산한다.
\[\lbrace w_1, ..., w_n\rbrace = \text{T-Encoder}(\lbrace w_1, ..., w_n\rbrace)\]T-Encoder($\cdot$)은 multi-layer 양방향 Transformer encoder이다. T-Encoder($\cdot$)은 BERT 구현체와 동일하다. 자세한 구조는 BERT와 Transformer 참조.
feature를 계산하면 ERNIE는 knowledgeable encoder K-Encoder를 사용하여 언어표현에 지식정보를 주입한다. 구체적으로, 지식 임베딩 모델 TransE로 사전학습된 entity embedding을 표현하고, $w$와 $e$ 모두를 K-Encoder에 입력으로 주어 다차원적 정보를 융합하고 최종 embedding 출력을 뽑아낸다.
$ \lbrace w_1^o, …, w_n^o\rbrace, \lbrace e_1^o, …, e_n^o\rbrace $는 특정 task를 위한 feature로 사용된다. K-Encoder의 세부적인 내용은 아래 절 참고.
3.3. Knowledgeable Encoder
K-Encoder는 aggregator를 쌓아 만든 구조로 token과 entity 모두를 인코딩하여 그 다차원적 feature를 융합하는 것을 목표로 한다. $i$-th aggregator에서, $(i-1)$-th aggregator에서 올라온 입력 token embedding $\lbrace w_1^{(i-1)}, …, w_n^{(i-1)}\rbrace$와 entity embedding $\lbrace e_1^{(i-1)}, …, e_m^{(i-1)}\rbrace$을 2개의 multi-head self-attentions(MH-ATTs)에 각각 넣는다.
그리고, $i$-th aggregator는 token과 entity sequence의 상호 통합을 위한 정보융합 layer를 사용, 각 token과 entity에 대한 출력 embedding을 계산한다. Token $w_j$와 상응하는 entity $e_k = f(w_j)$에 대해, 정보융합 과정은 아래와 같다.
\[h_j = \sigma(\tilde{W}_t^{(i)}\tilde{w}_j^{(i)} + \tilde{W}_e^{(i)}\tilde{e}_k^{(i)} + \tilde{b}^{(i)})\] \[w_j^{(i)} = \sigma(W_t^{(i)}h_j + b_t^{(i)}) \qquad \qquad \qquad\] \[e_k^{(i)} = \sigma(W_e^{(i)}h_j + b_e^{(i)}) \qquad \qquad \qquad\]$h_j$는 token과 entity의 정보를 통합하는 inner hidden state이다. $\sigma(\cdot)$은 비선형 활성함수로 GELU를 사용했다.
상응하는 entity가 없는 token의 경우, 정보융합 layer는 통합 없이 embedding을 계산한다.
\[h_j = \sigma(\tilde{W}_t^{(i)}\tilde{w}_j^{(i)} + \tilde{b}^{(i)})\] \[w_j^{(i)} = \sigma(W_t^{(i)}h_j + b_t^{(i)})\]단순히, $i$-th aggregator 연산은 아래와 같이 쓸 수 있다.
\[\lbrace w_1^{(i)}, ..., w_n^{(i)}\rbrace, \lbrace e_1^{(i)}, ..., e_m^{(i)}\rbrace = \text{Aggregator}(\lbrace w_1^{(i-1)}, ..., w_n^{(i-1)}\rbrace, \lbrace e_1^{(i-1)}, ..., e_m^{(i-1)}\rbrace)\]가장 위의 aggregator에서 나온 출력은 K-Encoder의 최종 output embedding으로 사용된다.
3.4. Pre-training for Injecting Knowledge
언어표현에 지식정보를 집어넣기 위해서 ERNIE를 위한 새 사전학습 task를 만들었다. 일부 token-entity alignments를 임의로 masking하고 시스템은 aligned token에 대한 모든 상응하는 entity를 찾는 것을 목표로 한다. 이는 auto-encoder를 denoising하는 것과 비슷하기에 이를 denoising entity auto-encoder(dEA)라 한다.
$\mathcal{E}$의 크기는 softmax layer에 비해 너무 크기 때문에, 시스템은 전체 KGs에 있는 것이 아닌 주어진 entity sequence만에 대해서 대응되는 entity를 찾으면 된다. token sequence $\lbrace w_1, …, w_n \rbrace$과 entity sequence $\lbrace e_1, …, e_n \rbrace$가 주어지면, token $w_i$에 대한 aligned entity 분포는 다음과 같이 나타낸다.
\[p(e_j \vert w_i) = \frac{\text{exp(linear}(w_i^o) \cdot e_j)}{\Sigma_{k=1}^m \text{exp(linear}(w_i^o)\cdot e_k)}\]위의 식은 dEA를 위한 cross-entropy loss 함수로 사용될 것이다.
token-entity alignment에서 오류가 있을 수 있기 때문에, dEA를 위해 다음과 같은 연산을 수행하였다.
- 5%의 경우에는 주어진 token-entity alignment에 대해 entity를 다른 임의의 entity로 교체하고 모델이 이를 바로잡도록 목표로 하였다.
- 15%의 경우에는 token-entity alignment를 masking하여 모델이 entity alignment 시스템이 존재하는 모든 alignment를 추출하지 않도록 학습하는 것을 목표로 한다.
- 나머지(80%)는 token alignment를 바꾸지 않고 두어 더 나은 언어이해를 위해 entity 정보를 token 정보와 통합하는 것을 목표로 한다.
BERT와 비슷하게, ERNIE는 MLM(Masked Language Model)과 NSP(Next Sentence Prediction)을 사전학습 task로 하여 어휘적, 구문 정보를 얻을 수 있게 한다.
사전학습 task의 전체 손실함수는 dEA, MLM, NSP loss를 전부 합한 것이다.
3.5. Fine-tuning for Specific Tasks
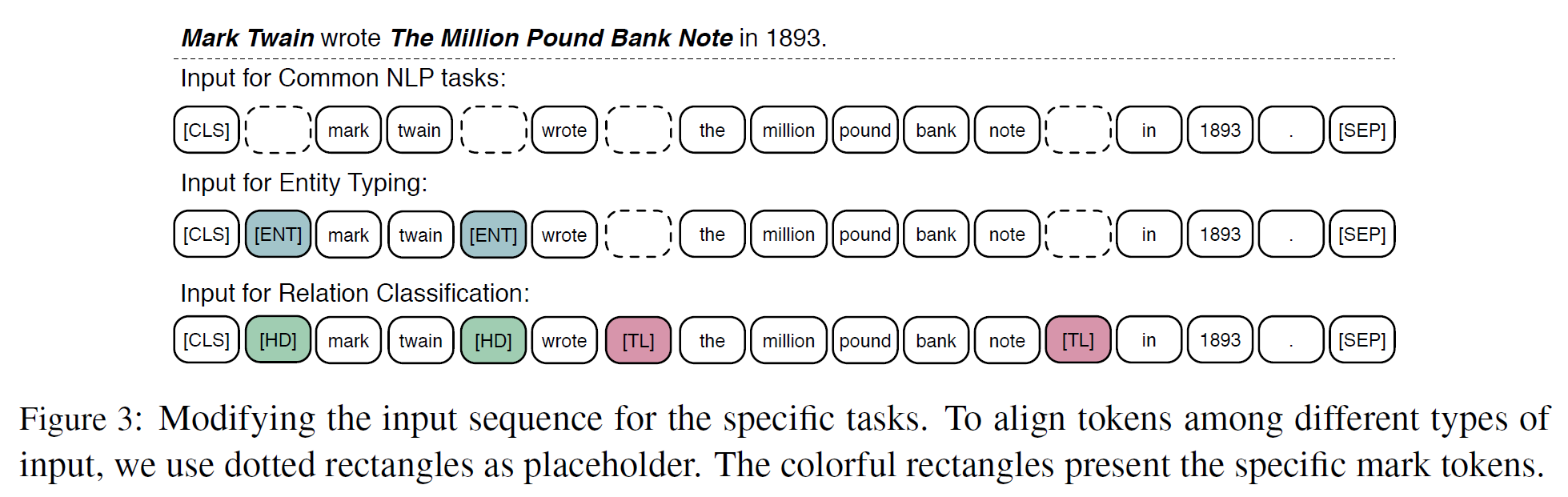
BERT와 비슷한 미세조정 과정을 거친다. [CLS]를 특별 token으로 문장의 처음을 가리키는 것으로 사용한다.
관계분류(relation classification) 문제에서, 시스템은 주어진 entity pair가 문맥에 기반하여 어떤 관계를 갖는지 판별해야 한다. 입력 token sequence에 2개의 mark token을 추가하여 entity mention을 강조한다. 이러한 추가적인 mark token은 전통적인 관계분류 문제에서 position embedding과 비슷한 역할을 한다. 그리고 [CLS] token을 분류를 위해 사용한다. [HD]와 [TL]은 각각 head entity와 tail entity를 나타낸다.
Entity typing을 위한 미세조정 과정은 관계분류에서 사용한 방법을 간소화한 것과 같다. 전체 문맥 embedding과 entity mention embedding을 쓰는 대신 Mention mark token [ENT]는 ERNIE가 문맥정보와 entity mention 정보를 잘 결합할 수 있게 해 준다.
4. Experiments
4.1. Pre-training Dataset
사전학습 과정은 이전의 다른 사전학습 모델과 비슷하다. Transformer 블록을 초기화할 때는 BERT의 것을 가져다 썼다. 영문 위키를 말뭉치와 align 텍스트로 사용하였다. 말뭉치를 사전학습을 위한 형식화된 데이터로 변환한 후에는, 주석 포함된(annotated) 입력은 4500M 보조단어와 140M개의 entity를 포함하며, 3개 이하의 entity를 가진 문장은 제외하였다.
ERNIE를 사전학습하기 전에는 Wikidata에서 학습된 knowledge embedding을 적용하였다. Wikidata는 5M개의 entity와 24M개의 fact triplet을 포함한다.
4.2. Parameter Settings and Training Details
token / entity embedding의 hidden dimension을 $H_w=768, H_e=100$이고, self-attention head의 수는 $A_w=12, A_e=4$, $N=6, M=6$이다. 전체 parameter의 개수는 114M개이다. 이는 BERT-base와 비슷한 수치(110M)로 ERNIE의 knowledgeable module이 언어 module보다 더 작으며 실행시간에 더 적은 영향을 미친다.
학습을 가속하기 위해 최대 sequence 길이를 512에서 256으로 조정하고(self-attention의 학습 시간은 길이의 제곱에 비례) token의 수를 유지하기 위해 batch size는 256에서 두 배로 늘렸다.
4.3. Entity Typing
entity mention과 그 문맥이 주어질 때, entity typing은 시스템이 entity mention과 해당하는 의미 종류를 레이블링하도록 요구한다. 이 task에서 성능 측정은 FIGER와 Open Entity에 ERNIE를 미세조정하여 수행한다. FIGER의 학습 데이터셋은 distant supervision으로 레이블링되어 있으며 테스트셋은 사람에 의해 annotate되어 있다. Open-Entity는 완전히 사람에 의해 만들어진 데이터셋이다.
ERNIE를 다른 baseline 모델과 비교하였다. 아래는 데이터셋 통계와 실험 결과를 나타낸 것이다.

NFGEC
NFGEC는 hybrid 모델로 entity mention, 문맥, 수동으로 만든 추가 feature를 입력으로 하는 모델로 FIGER에서 SOTA이다. 단 본 논문에서는 수동 생성 feature는 쓰지 않았다.
UFET
UFET는 Open Entity 데이터셋에서 제안된 것으로 2개의 Bi-LSTM을 분리하여 사용하는 NFGEC와는 다르게 하나의 Bi-LSTM을 문맥 표현을 위해 사용한다.
또한 추가적으로 BERT를 비교하였다.
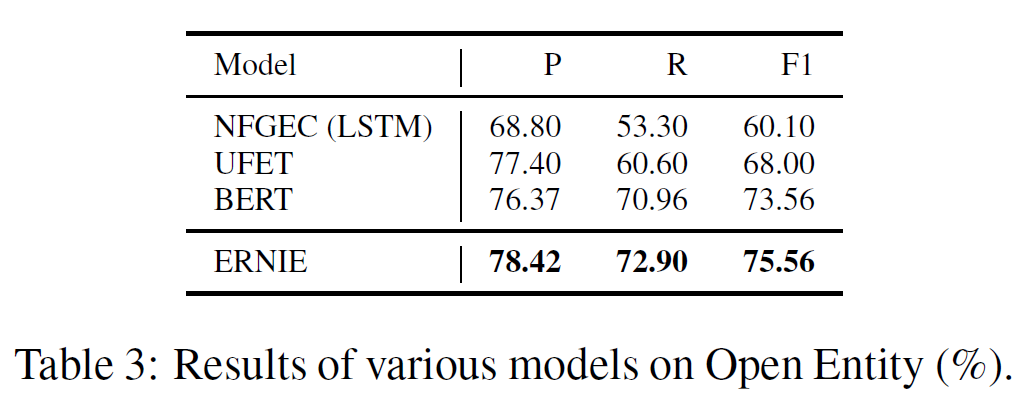
전체 실험 결과를 요약하면, ERNIE는 KGs에서 얻은 정보를 잘 주입하는 것으로 FIGER에서 noisy label 문제를 효과적으로 줄일 수 있다. 또한 Open Entity에서는 다른 baseline 모델을 능가한다.
4.4. Relation Classification
문장에서 두 entity의 관계를 판별하는 문제로 knowledge-driven 자연어처리 task에서 중요한 문제이다. 성능 측정을 위해서 FewRel과 TACRED를 사용하였으며, 비교 모델로 CNN, PA-LSTM, C-GCN을 사용하였다.
CNN
textCNN을 사용하는 모델로 position embedding이 사용되었다.
PA-LSTM
Position-Aware LSTM을 사용한 네트워크로 최종 문장표현을 위한 sequence의 각 단어에 대한 상대적 기여도를 평가한다.
C-GCN
Graph Convolution 연산을 사용한 모델로 의존성 parsing 문제를 줄이고 단어 순서를 인코딩하기 위해 Contextualized GCN(C-GCN)을 사용한 것으로 Bi-LSTM을 사용한다.
또한 BERT도 비교하였다.
Relation Classification 비교 실험 결과는 아래에서 볼 수 있다.
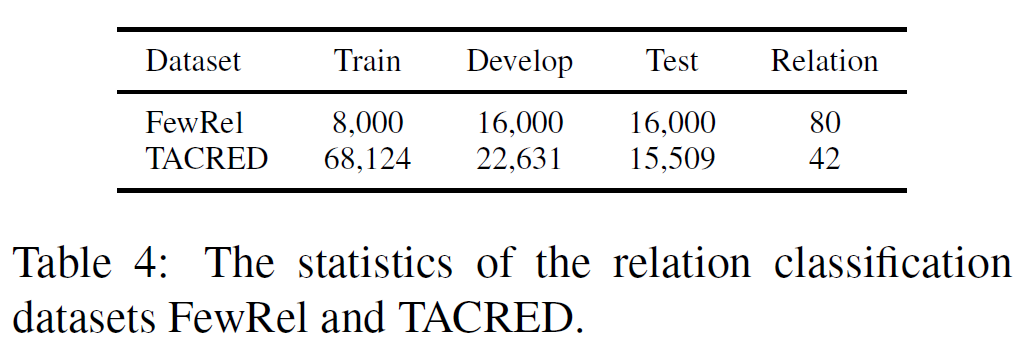
전체적으로, 추가 지식은 적은 데이터로도 모델 학습이 가능하게 하며, 이는 많은 데이터를 모으기가 어려운 대부분의 자연어처리 문제에서 상당히 중요한 결과이다.
4.5. GLUE
자연어처리에서 다양한 task에 대해 평가를 할 수 있는 GLUE benchmark에서 실험한 결과를 아래에 나타내었다.
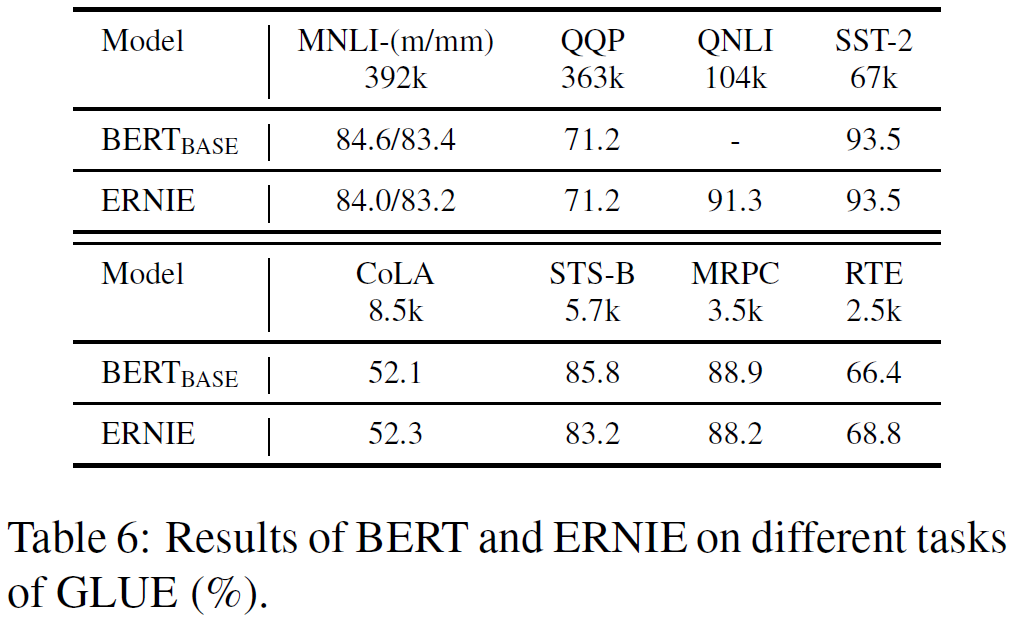
BERT-large와 비교하여 비등하거나 조금 더 나은 결과를 보이는 것을 알 수 있다. 이를 통해 ERNIE는 다양한 정보융합 이후에도 textual 정보를 잃어버리지 않는다는 것을 알 수 있다.
4.6. Ablation Study
추가 정보 entity와 dEA의 효과를 알아보기 위해 entity와 dEA가 없는 버전의 모델을 갖고 실험하였다.
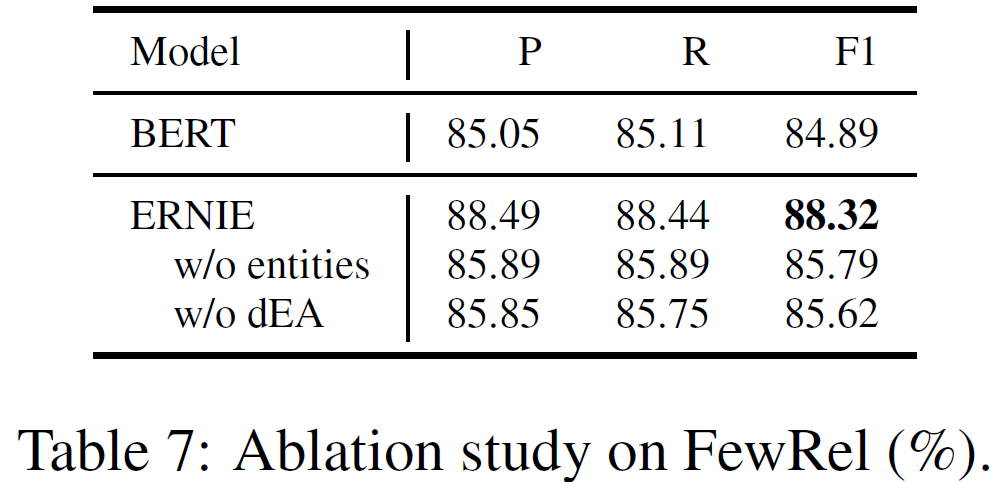
해당 모듈이 없을 때는 BERT와 비교하여 P, R, F1 score가 비슷하지만, 모듈을 추가한 최종 버전은 결과가 제일 좋음을 알 수 있다. 따라서 entity 정보와 dEA가 추가 지식을 잘 활용하여 모델의 성능에 도움을 준다는 것을 확인할 수 있다.
결론(Conclusion)
본 논문에서, ERNIE라는 정보통합 모델을 제안하였고 knowledgeable aggregator와 사전학습 task dEA를 제안하였다. 실험 결과를 통해 ERNIE는 추가 지식을 잘 활용하여 다양한 자연어처리 문제에서 성능 향상에 도움을 준다는 것을 확인하였고 데이터가 적은 상황에서도 유용함을 알 수 있었다.
추가 연구로,
- ELMo와 같은 feature 기반 사전학습 모델에 지식을 주입하는 것
- Wikidata와 같은 지식 데이터베이스와는 다른 형태인 ConceptNet과 같은 언어표현 모델에 다양한 구조화된 지식을 넣는 것
- 더 큰 사전학습 데이터를 위한 실세계 말뭉치들을 annotate하는 것
을 생각해 볼 수 있다. 이는 더 범용적이고 효과적인 언어이해에 도움을 줄 수 있는 방향이 될 수 있을 것이다.
참고문헌(References)
논문 참조!