
ERNIE 논문 설명(ERNIE-ViL- Knowledge Enhanced Vision-Language Representations Through Scene Graph)
19 Jul 2021 | Paper_Review NLP ERNIE목차
- ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph
이 글에서는 Baidu에서 만든 모델 시리즈 ERNIE 중 세 번째(ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph)를 살펴보고자 한다.
ERNIE 시리즈는 다음과 같다. 참고로 2번째는 Baidu가 아닌 Tshinghus University에서 발표한 논문이다.
- ERNIE: Enhanced Representation through Knowledge Integration, Yu sun el al., 2019년 4월
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding, Yu Sun et al., 2019년 6월
- ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph, Fei Yu et al., 2019년 6월
- ERNIE-Doc: A Retrospective Long-Document Modeling Transformer, Siyu Ding et al., 2020년 12월
- ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation, Yu Sun et al., 2021년 7월
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph
논문 링크: ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph
Official Code: Github
초록(Abstract)
본 논문에서는 지식 강화된 접근법, ERNIE-ViL을 제안하며 이는 시각 및 언어의 결합표현(joint representation)을 학습하기 위해 scene graph로부터 얻은 구조화된 지식을 포함한다. ERNIE-ViL은 시각-언어 cross-model task에서 필수적인 상세한 의미적 연결(물체, 물체의 특성, 물체 간 관계)를 만드는 것을 목표로 한다. 시각적 장면에서 scene graph를 사용하며 ERNIE-ViL은 물체예측(Object Prediction), 특성예측(Attribute Prediction), 관계예측(Relation Prediction) 등의 Scene Graph Prediction task를 구성한다. 구체저으로, 이 예측 task들은 문장에서 분석된 scene graph에서 서로 다른 종류의 node를 예측하는 것으로 구성된다. 따라서, ERNIE-ViL은 시각 정보와 언어를 망라하는 상세한 의미적 정보의 alignments을 특징짓는 결합표현을 학습할 수 있게 된다. 대규모의 이미지-텍스트 데이터셋에서 사전학습한 후 ERNIE-ViL의 유효함을 5개의 cross-modal downstream task에서 검증한다. ERNIE-ViL은 이들 모두에서 SOTA 성능을 보였으며 VCR에서는 절대수치로 3.7%의 성능 개선을 보이며 1등 자리에 올랐다.

1. 서론(Introduction)
BERT, GPT와 같은 사전학습 모델들은 많은 자연어처리 문제에서 성능을 크게 향상시켰으며 VQA, VCR과 같은 시각-언어 task를 위한 사전학습의 중요성이 알려졌다.
현존하는 시각-언어 사전학습 방법은 임의로 subword를 masking하는 Masked Language Modelling, 이미지-
텍스트 수준에서 수행하는 Masked Region Prediction, Image-Text Matching을 포함한 대규모 이미지-텍스트 데이터셋에서 visual grounding task를 수행함으로써 결합표현을 학습하고자 하였다. 그러나, subword를 임의 masking하고 이를 예측하는 방식으로는 모델이 일반적 단어와 상세 의미를 묘사하는 단어를 구별하지 못한다. 예: 물체(“man”, “boat”), 물체의 특성(“boat is white”), 물체 간 관계(“man standing on boat”).
이러한 방법은 지식과 언어 간 세부적인 semantice alignments를 구성하는 중요성을 무시하여, 학습 모델은 몇몇 실제 장면에서 요구되는 세밀한(fine-grained) 의미정보를 잘 표현하지 못한다. 아래 그림 1에서와 같이, 세부 의미는 물체/특성/관계와는 다른 여러 장면들을 구별하는데 필수적이다. 따라서, 더 나은 시각정보-언어 결합표현은 modality를 넘는 세부적인 semantic alignments을 특징지을 수 있어야 한다.
ERNIE의 masking 전략에 힘입어 각 subword보다는 phrase와 명명 객체를 masking하는 방법으로 더 구조화된 지식을 학습하는 것으로 ERNIE-ViL을 제안한다. 이는 시각-언어 결합표현을 구성하기 위해 scene graph에서 얻은 지식을 통합한다. Scene Graph Prediction(SGP) task를 구성함으로써 시각-언어 정보의 상세한 semantic alignments에 더 많은 역점을 둔다. Scene graph 상의 여러 종류의 node를 masking하고 이를 다시 예측하는 사전학습 task를 구현하였다. 그리고 일반단어보다 더 세부적인 의미를 담고 있는 단어를 이해하는 데 집중함으로써 이러한 SGP task는 모델이 시각 정보에서 물체/특성/관계 정보를 추출하도록 강제하고 따라서 시각-언어 사이의 의미적 연결을 수립할 수 있다. SGP 사전학습 task를 통해 ERNIE-ViL은 시각-언어 간 세부적인 semantic alignments 정보를 학습한다.
ERNIE-ViL은 2개의 일반적으로 사용되는 대규모 이미지-텍스트 out-of-domain 데이터셋을 사용하였다(Conceptual Captions, SBU Captions). 성능 측정을 위해서는 VQA 2.0, VCR, RefCOCO+(Region-to-Phrase Grounding), Image-text Retrival, Text-image Retrival(Flickr30K)를 사용하였다. 위의 모든 task에 대해서 ERNIE-ViL은 이전의 모델보다 더욱 좋은 성능을 보여주었다. 특히 세부 semantic alignments에 크게 의존하는 Region-to-Phrase Grounding task에서는 2.4%의 개선을 보여준다.
Out-domain과 in-domain 비교를 위해 ERNIE-ViL은 MS-COCO와 Visual Genome에서 사전학습을 하여 VCR의 Q$\rightarrow$AR task에서 3.7%의 개선을 보였다.
이 논문의 기여한 바는:
- ERNIE-ViL은 시각-언어 사전학습을 향상시키는 구조화된 지식을 소개한 첫 번째 연구이다.
- ERNIE-ViL은 시각-언어 결합표현의 사전학습을 위한, cross-modal 세부적 semantics alignments에 특히 집중하는 Scene Graph Prediction task를 구성하였다.
- 5개의 downstream cross-modal task에서 SOTA 결과를, VCR에서 1등의 자리에 올랐다.
2. 관련 연구(Related Work)
Cross-modal Pre-training
BERT와 같은 시각-언어 문제를 위한 cross-modal 사전학습 모델이 많이 제안되었다. 이들 연구자들은 모델구조, 사전학습 task, 사전학습 데이터라는 3가지 관점에서 노력하였다.
Model Architecture: 현재 연구들은 Transformer 및 그 변형으로 구성된다. 대부분 한 종류의 cross-modal Transformer를 사용하지만 ViLBERT나 LXMERT는 이미지와 텍스트에 더 특화된 표현을 얻을 수 있는 2종류의 cross-modal Transformer를 사용하였다.
Pre-training Tasks: Masked Language Model과, 비슷한 Masked Region Prediction task가 cross-modal 사전학습에서 많이 사용되어 왔다. Next Sentence Prediction과 비슷하게 Image-Text Matching task가 널리 사용되었다. 그러나 subwords를 임의 masking 및 예측하는 방법은 일반단어와 세부 의미를 구별하지 못하며 결합표현을 제대로 특징짓기 어렵다.
Pre-training Data: 자연어의 방대한 것과 다르게 시각-언어 task는 고품질의 대규모 데이터셋을 구하기 어렵다. Conceptual Captions와 SBU Captions는 이미지-텍스트 사전학습에서 널리 사용되는 데이터셋으로 각각 3.0M / 1.0M개의 이미지-설명 쌍을 포함한다. 이들 2개의 데이터셋은 시각-언어 downstream task의 전문 분야는 아니다. 현존하는 연구들은 MS-COCO와 Visual-Genome과 같은 downstream task와 연관이 깊은 데이터셋을 사용하는 것과는 대조적이다.
Scene Graph
Scene Graph는 존재하는 물체들, 물체의 특성, 물체 간 관계를 포함하는 시각 장면의 구조화된 지식을 포함한다. 이미지와 caption의 세부지식을 묘사하는 사전지식에 힘입어, scene graph는 image captioning, image retrival, VQA, image generation 등에서 SOTA 모델을 만드는 데 큰 도움을 주었다.
3. 접근법(Approach)
이 섹션에서, ERNIE-ViL의 구조를 소개하고, Scene Graph Prediction task를 설명한다. 마지막으로 SGP task로 ERNIE-ViL을 사전학습하는 방법을 기술한다.
이 framework의 효율성을 검증하기 위해 3가지의 비지도 언어처리 task를 구성하고 사전학습 모델 ERNIE 2.0을 개발하였다. 이 섹션에서 모델의 구현 방법을 설명한다.
Model Architecture
시각-언어 모델은 2개의 modality와 두 modality 간 alignment의 정보를 통합한 결합표현을 학습하는 것을 목표로 한다. ERNIE-ViL의 입력은 문장과 이미지이다. 단어의 sequence와 이미지가 주어지면 feature space로 embedding시키고 시각-언어 encoder에 주는 방법을 소개한다.
Sentence Embedding
BERT와 유사한 단어 전처리 작업을 적용한다. 입력 sequence는 WordPiece에 의해 sub-word token으로 변환되고 특수 token이 추가된다. 최종 embedding은 원래의 word/segment/position embedding의 결합으로 이루어진다.
\[\lbrace [CLS], w_1, ..., w_T, [SEP] \rbrace\]Image Embedding
중요한 이미지 영역을 탐지하기 위해 물체 탐지 모델을 사용한다. multi-class 분류 layer 전 pooling feature가 region feature로 사용된다. 위치 feature는 위치와 이미지 영역의 비율로 구성되는 5차원 벡터로 표현된다. 이미지 크기를 $W, H$와 좌상단 좌표 $x_1, y_1$, 우하단 좌표 $x_2, y_2$에 대해 벡터는 다음과 같다.
\[\Bigl( \frac{x_1}{W}, \frac{y_1}{H}, \frac{x_2}{W}, \frac{y_2}{H}, \frac{(y_2-y_1)(x_2-x_1)}{WH} \Bigl)\]이미지 벡터는 위치 feature를 위해 사용된 후 region visual feature와 합해진다. 특수 토큰 [IMG]를 추가하여 이미지 표현임을 나타내어 최종 region sequence는 다음과 같이 된다.
Vision-Language Encoder
이미지 영역과 단어의 embedding이 주어지면 modal 간 모델 및 modal 내 모델 표현을 결합한 two-stream cross-modal Transformer에 넣는다. VilBERT와 비슷하게 ERNIE-ViL은 이미지/텍스트를 위한 2개의 평행한 Transformer encoder로 구성된다. 이미지와 텍스트 표현 전체는 각각 다음으로 표시된다.
\[h_{[IMG]}, h_{[CLS]}\]Scene Graph Prediction
물체, 물체의 특성, 물체 간 관계를 포함하는 세부 semantics은 시각적 장면을 이해하는데 필수적이다.
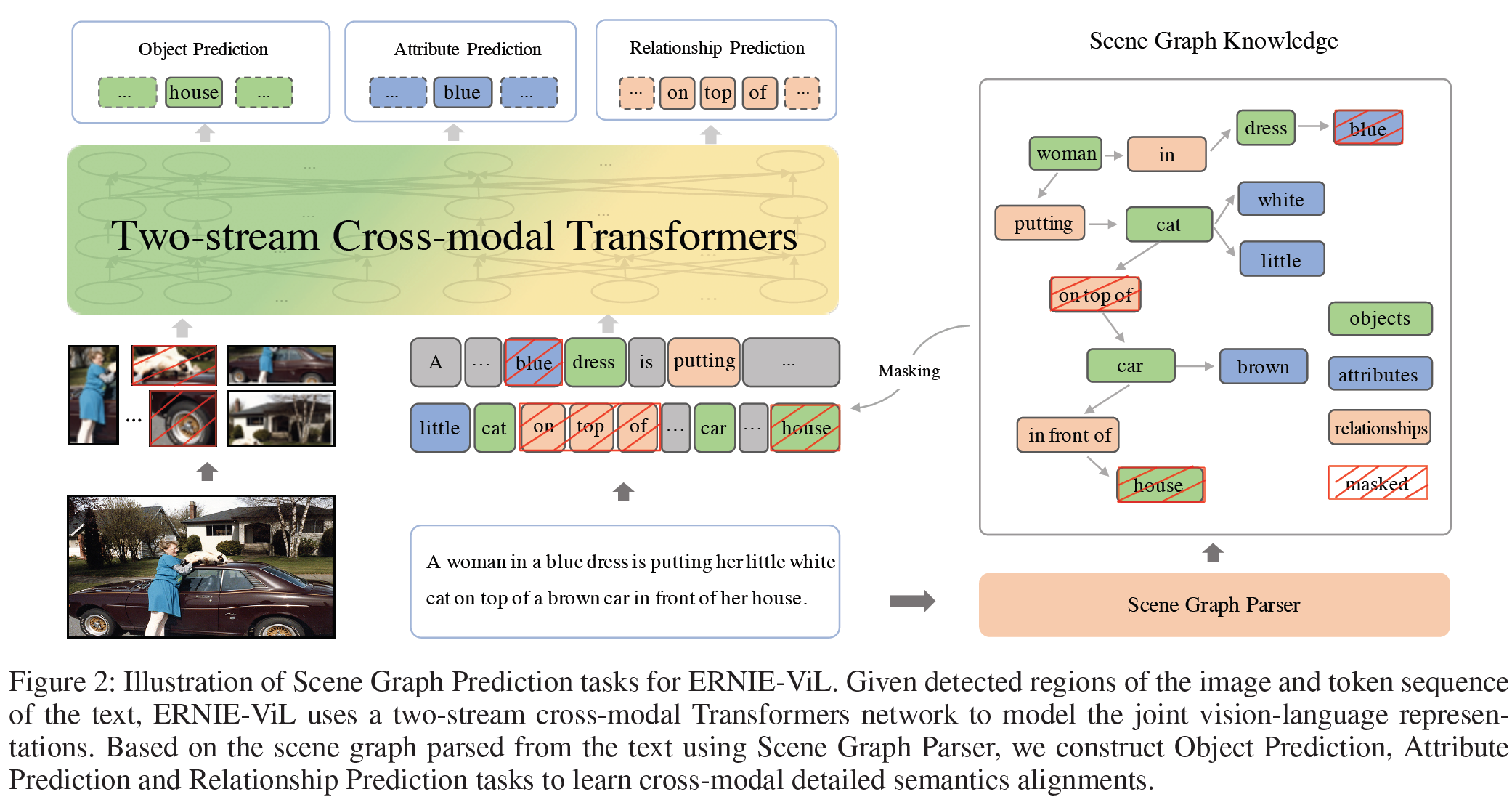
그림 2와 같이, 세부 semantic은 여러 방면에서 시각 장면을 묘사한다. "cat", "car", "woman"과 같은 물체(object)는 장면에서 핵심 요소이다. 이와 연관된 "little", "brown", "blue"와 같은 특성(attributes)은 물체의 모양과 색깔을 특징짓는다. "on top of", "putting"과 같은 관계는 물체 사이의 공간적인 연결과 action을 표현한다. 따라서 세부적인 semantic은 시각 장면을 정확히 이해하는 데 필수적이다. 시각-언어 결합표현의 목적은 modality 간 의미적 연결을 새기는(engrave, 혹은 학습하는) 것으로 세부적 semantic alignments는 cross-modal 학습에서 매우 중요하다.
Scene graph는 다양한 세밀한 의미적 정보를 표현한다. Scene graph로부터 얻은 지식을 바탕으로 ERNIE-ViL은 cross-modal detailed semantic alignments를 학습한다. 위 그림에서와 같이 텍스트로부터 분석된 scene graph에 따라 물체/특성/관계예측 task를 포함하는 Scene Graph Prediction task를 구성한다. 이들 task는 모델이 modality 간 세부적 semantic을 학습하도록 강제한다.
예를 들어 on top of가 masking되었다고 하면, 문맥에 기반하여 모델은 가려진 단어가 under 혹은 into 정도일 것으로 예측할 것이다. 이는 구문으로는 맞지만 the cat in in top of the car이라는 이미지의 내용과 맞지 않다. 관계예측 task로 학습함으로써 모델은 물체 간 공간적 관계를 이미지로부터 학습하고 빠진 단어 on top of를 바르게 예측할 수 있다. SGP task를 구성함으로써 ERNIE-ViL은 cross-modal detailed semantic alignments를 학습하게 된다.
Scene graph parsing
텍스트 sequence $\mathbf{w}$가 주어지면 scene graph로 parse한다. Scene Graph는
\[G(\mathbf{w}) = < O(\mathbf{w}), E(\mathbf{w}), K(\mathbf{w}) >\]이다.
- $O(\mathbf{w})$는 $\mathbf{w}$에서 언급된 물체
- $R(\mathbf{w})$는 관계
- $E(\mathbf{w}) \subseteq O(\mathbf{w}) \times R(\mathbf{w}) \times O(\mathbf{w}) $는 물체 간 관계를 나타내는 hyper-edge
- $K(\mathbf{w}) \subseteq O(\mathbf{w}) \times A(\mathbf{w})$는 특성 쌍
- $A(\mathbf{w})$는 물체 node와 연관된 특성 node의 집합이다.
Scene graph는 물체의 여러 특성과 관계를 포함하여 물체를 상세히 묘사한다. scene graph의 지식을 통합하는 것은 더욱 세밀한 시각-언어 결합표현을 학습하는 데 도움이 된다. 이 논문에서, Anderson의 Scene Graph parser를 사용하여 scene graph를 생성하였다. 아래 표에서 생성된 scene graph의 일부 예시를 확인할 수 있다.

Object Prediction
물체는 시각 장면의 지배적 존재로 의미정보 표현을 구성하는 데 중요한 역할을 차지한다. 물체를 예측하는 것은 모델이 물체 수준 시각-언어 연결을 구축하는 것을 강제한다.
먼저 scene graph의 모든 물체 node에 대해 30%를 임의로 masking한다. 선택된 각 물체 node $O(\mathbf{w})$에 대해 80%를 [MASK]로 대체하고 10%는 임의의 다른 token으로, 나머지 10%는 그대로 둔다. 물체는 사실 문장의 sub-sequence와 연관되어 있으므로 물체를 masking하는 것은 텍스트에서 sub-sequence를 masking하는 것으로 구현된다.
물체 예측을 위해 ERNIE-ViL은 주변단어 $\mathbf{w}$와 모든 이미지 영역 $\mathbf{v}$에 기반하여 masking된 물체 token $w_{o_i}$를 복구한다. 다음 log-likelihood를 최소화한다.
\[\mathcal{L}_{obj}(\theta) = -E_{(\textbf{w, v}) \sim D} \log(P(\textbf{w}_{o_i} \vert \textbf{w}_{\backslash \textbf{w}_{o_i}}))\]Attribute Prediction
물체의 특성은 물체를 표현하는 데 있어서 중요한 역할을 한다.
비슷하게, 30%의 특성 쌍을 임의로 택하여 Object Prediction과 같은 masking 전략을 취한다. 특성은 어느 물체에 속하기 때문에 $K(\mathbf{w}) \subseteq O(\mathbf{w}) \times A(\mathbf{w})$에서 선택된 $A(\mathbf{w})$를 masking하는 동안 물체 $O(\mathbf{w})$는 그대로 둔다.
특성예측 task는 특성 쌍 $<w_{o_i}, w_{a_i}>$에서 물체에 해당하는 단어 $w_{o_i}$가 주어지면 $w_{a_i}$를 복구해야 한다. 물체예측과 비슷하게, 다음 로그 우도를 최소화한다.
\[\mathcal{L}_{attr}(\theta) = -E_{(\textbf{w, v}) \sim D} \log(P(\textbf{w}_{a_i} \vert \textbf{w}_{o_i}, \textbf{w}_{\backslash \textbf{w}_{a_i}}, \textbf{v}))\]Relationship Prediction
관계예측 task는 $E(\mathbf{w}) \subseteq O(\mathbf{w}) \times R(\mathbf{w}) \times O(\mathbf{w}) $를 선택하여 물체는 그대로 두고 관계 $ R(\mathbf{w})$만 masking한다. 즉 $<w_{o_{i1}}, w_{r_i}, w_{o_{i2}}>$에서 물체 $w_{o_{i1}}, w_{o_{i2}}$가 주어지면 관계 $w_{r_{i}}$를 복구해야 한다. 손실함수는 다음과 같다.
\[\mathcal{L}_{rel}(\theta) = -E_{(\textbf{w, v}) \sim D} \log(P(\textbf{w}_{r_i} \vert \textbf{w}_{o_{i1}}, \textbf{w}_{o_{i2}}, \textbf{w}_{\backslash \textbf{w}_{r_i}}, \textbf{v}))\]Pre-training with Scene Graph Prediction
VilBERT와 비슷하게, ERNIE-ViL은 텍스트의 구문, 어휘적 정보를 얻기 위해 Masked Language Modelling(MLM) task를 적용한다. 또한, 시각 modality와 cross-modality를 위해 Masked Region Prediction과 Image-text Matching을 각각 사용한다. 모든 사전학습 task의 손실함수는 합산한다.
4. Experiments
Training ERNIE-ViL
Pre-training Data
Conceptual Captions와 SBU Captions 데이터셋을 사전학습 데이터로 사용했다. CC는 3.3M개의 이미지-캡션 쌍을 포함하며 SBU는 1.0M쌍을 포함한다. 깨진 링크 일부를 제외하고 각각 3.0M, 0.8M쌍의 데이터를 사용하였고 추후의 downstream task와는 별 연관이 없는 데이터로 out-of-domain 데이터셋 역할을 한다.
Implementation Details
각 이미지-텍스트 쌍에 대해 다음 전처리를 한다.
- 이미지에 대해서는 Faster R-CNN을 사용하여 중요 부분을 찾고 region feature를 추출한다.
- 0.2 이상의 점수를 갖는 영역만을 취하고 10~36개의 영역을 택한다.
- 각 영역에 대해 mean-pooled convolutional 표현이 사용된다.
- 텍스트는 BERT와 비슷하게 Scene Graph Parser를 통해 scene graph를 생성하고 WordPieces를 사용하여 tokenize한다.
- Masking 전략은 다음과 같다.
- token의 15%, scene graph node의 30%, 이미지 영역의 15%만큼 임의로 masking한다.
- Image-text Matching task에 대해서는 부정 이미지-텍스트 쌍을 만들기 위해 임의의 이미지와 텍스트를 택한다. Token과 region 예측 task에 대해서는 긍정 쌍만 고려됨을 참고하라.
모델의 깊이(및 규모)가 다른 2개의 모델 ERNIE-ViL-base와 ERNIE-ViL-large를 학습시킨다.
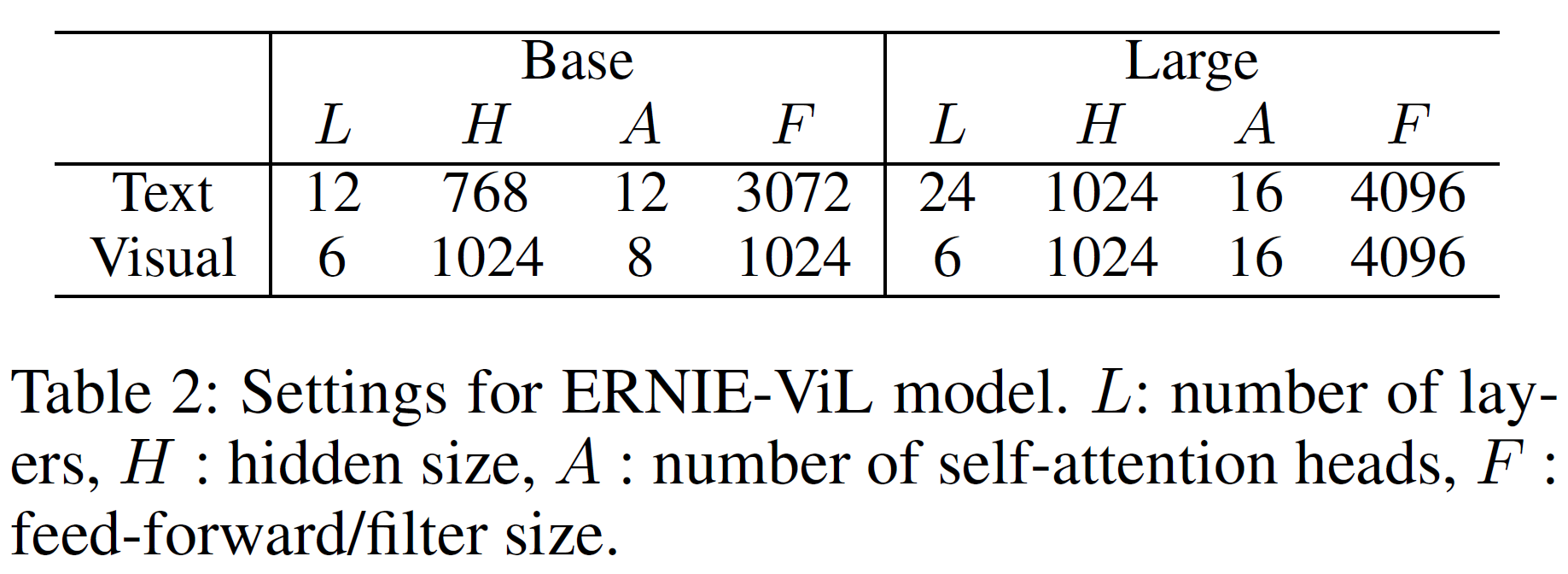
ViLBERT와 비슷하게 cross-transformers가 사용된다. Baidu에서 만든 플랫폼인 PaddlePaddle를 통해 구현하였으며 8개의 V100 GPU를 사용, batch size 512로 700K step만큼 학습시켰다. Adam optimizer, learning rate는 1e-4이며 Noam decay를 사용했다.
Downstream Tasks
Visual Commonsense Reasoning (VCR)
2개의 다지선다형 문제, Visual Question Answering($Q \rightarrow A$)와 Anser Justification($QA \rightarrow R$)의 sub-task로 구성되어 있다. 전체 세팅($QA \rightarrow R$)는 문제에 대한 답뿐만 아니라 그 이유까지 맞춰야 한다.
VQA($Q \rightarrow A$)에서는 언어 modality에서 질문과 각 선택지를 이어 붙인다. 최종 은닉상태 $h_{[CLS]}, h_{[IMG]}$에 내적을 취하여 FC layer를 통해 matching score를 예측한다.
답변 타당성 문제($QA \rightarrow R$)에서는 질문, 각 이유 선택지를 이어 붙인다. UNITER와 비슷하게 2번째 사전학습이 VCR 데이터셋에서 행해진다. 6 epoch, batch size 64, learning rate 1e-4, Adam optimizer를 사용했다.
Visual Question Answering (VQA)
204k개의 이미지와 1.1M개의 질문을 포함하는 VQA 2.0 데이터셋을 사용한다. UNITER와 같이 데이터 증강을 위해 Visual Genome에서 얻은 질답 쌍을 추가로 사용했다. 본 논문에서는 VQA를 multi-label 분류문제로 생각(10개의 사람의 답변 반응에 대한 연관도에 기반한 답변의 soft target score를 부여)하였다.
$h_{[CLS]}, h_{[IMG]}$을 내적하고 2-layer MLP를 추가하여 3129개의 가능한 답변에 매칭을 시킨다. 12 epoch, batch size 256, learning rate 1e-4, Adam optimizer를 사용했다.
Grounding Referring Expressions
자연어 reference가 주어질 때 (원하는) 이미지 영역을 특정하는 task로 RefCOCO+ 데이터셋을 사용했다. 각 이미지 영역의 표현 $h_{v_i}$와 FC layer에 의해 표현된다. 각 영역 $i$는 GT bounding box와 IoU가 0.5 이상일 때에만 label이 부여된다. 20 epoch, batch size 256, learning rate 1e-4, Adam optimizer를 사용했다.
Image Retrieval & Text Retrieval
내용을 묘사하는 caption에 기반한 pool로부터 이미지를 식별하는 task이다. Flickr30K는 31K개의 이미지와 각 이미지당 5개의 caption을 포함한다. VilBERT와 같은 분할을 적용하여 1K개의 validation/test set을 만든다. 역시 최종 은닉상태를 내적하고 FC layer를 사용하여 matching score $s(\textbf{w}, \textbf{v})$를 예측한다.
각 이미지-텍스트 쌍에 대해 20개의 부정 쌍을 사용하여 circle loss를 사용하였고, 40 epoch, learning rate 1e-4, Adam optimizer를 사용했다.
Results
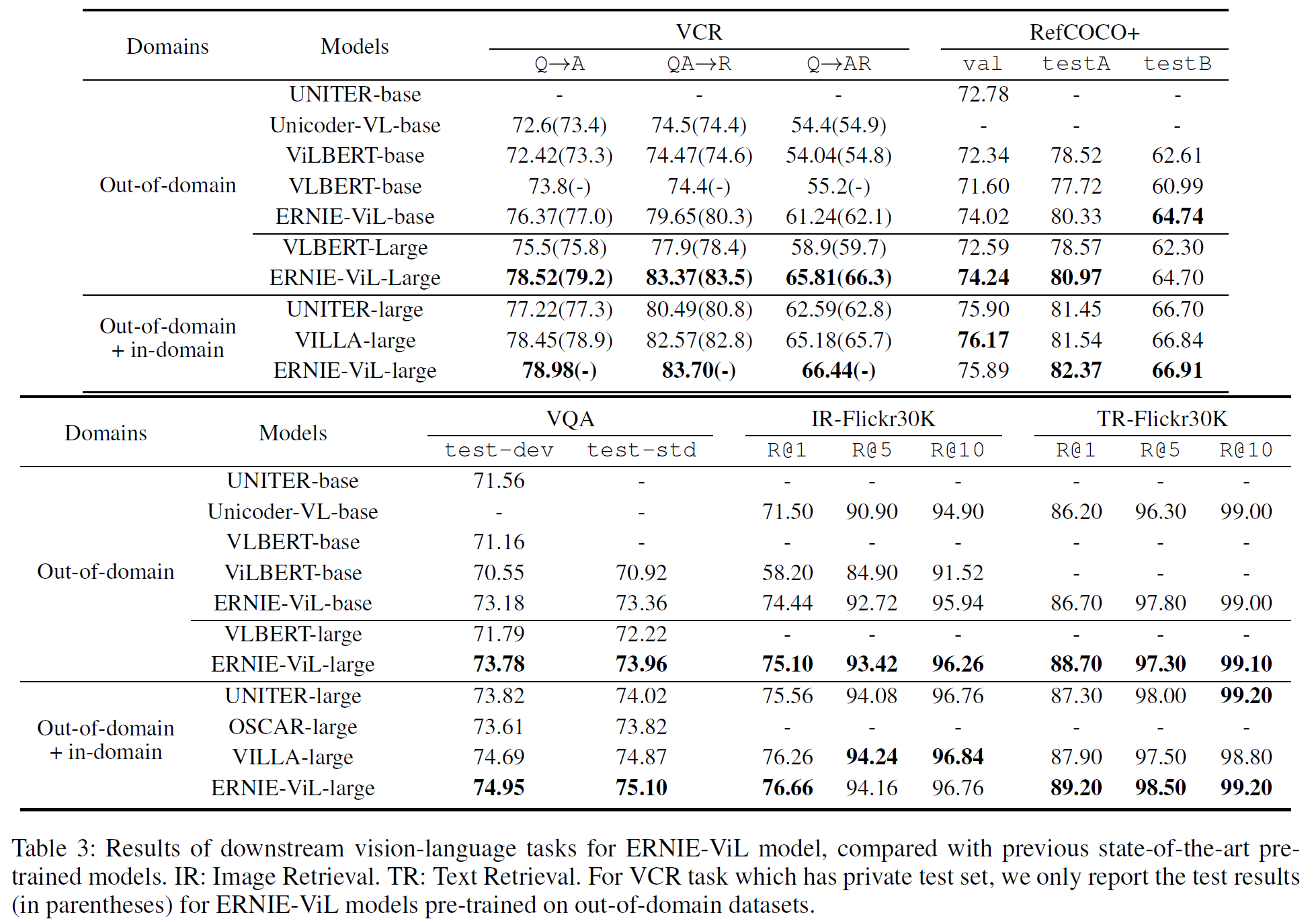
같은 out-of-domain 데이터셋으로 사전학습한 경우 중 ERNIE-ViL이 5개의 모든 downstream task에서 가장 좋은 성능을 보였다. 시각추론 문제에서 ERNIE-ViL-large는 VLBERT-large에 비해 VCR($Q \rightarrow AR$)에서 6.6%, VQA에서 1.74%의 향상을 이루었다. Visual Grounding task에서는 testA/B에서 2.4%, Cross-modal Retrieval task에서는 ERNIE-ViL-base가 R@1 이미지에서 2.94%, R@1 텍스트에서 0.5%만큼의 성능 향상이 있었다.
Out-of-domain과 in-domain에서 사전학습한 모델들의 비교를 표 3의 아래에서 볼 수 있는데, UNITER, OSCAR, VILLA보다 더 좋은 결과를 얻었다.
Analysis
Effectiveness of Scene Graph Prediction tasks
SGP task의 효과를 알아보기 위해 우선 BERT로 초기화한 ERNIE-ViL-base를 사용한다.
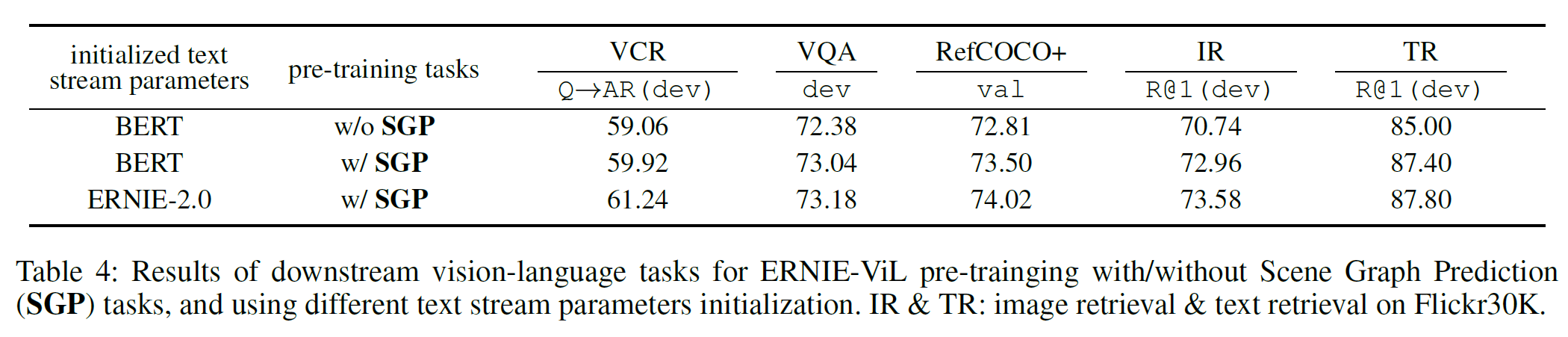
SGP가 있을 때가 더 좋은 성능을 보임을 알 수 있다.
Cloze Test
SGP task의 향상을 더 이해하기 위해 cloze test를 수행한다. 텍스트에서 물체, 특성, 관계 등 세부 semantic이 masking된 상태에서 모델은 텍스트와 이미지 모두의 문맥에서 그것들을 추론해야 한다. Flickr30K에서 15K개의 이미지-텍스트 쌍, 5K개의 물체를 선택하여 top-1, top-5 정확도를 평가 지표로 사용했다. SGP가 있을 때와 없을 때의 차이를 아래에서 볼 수 있다.
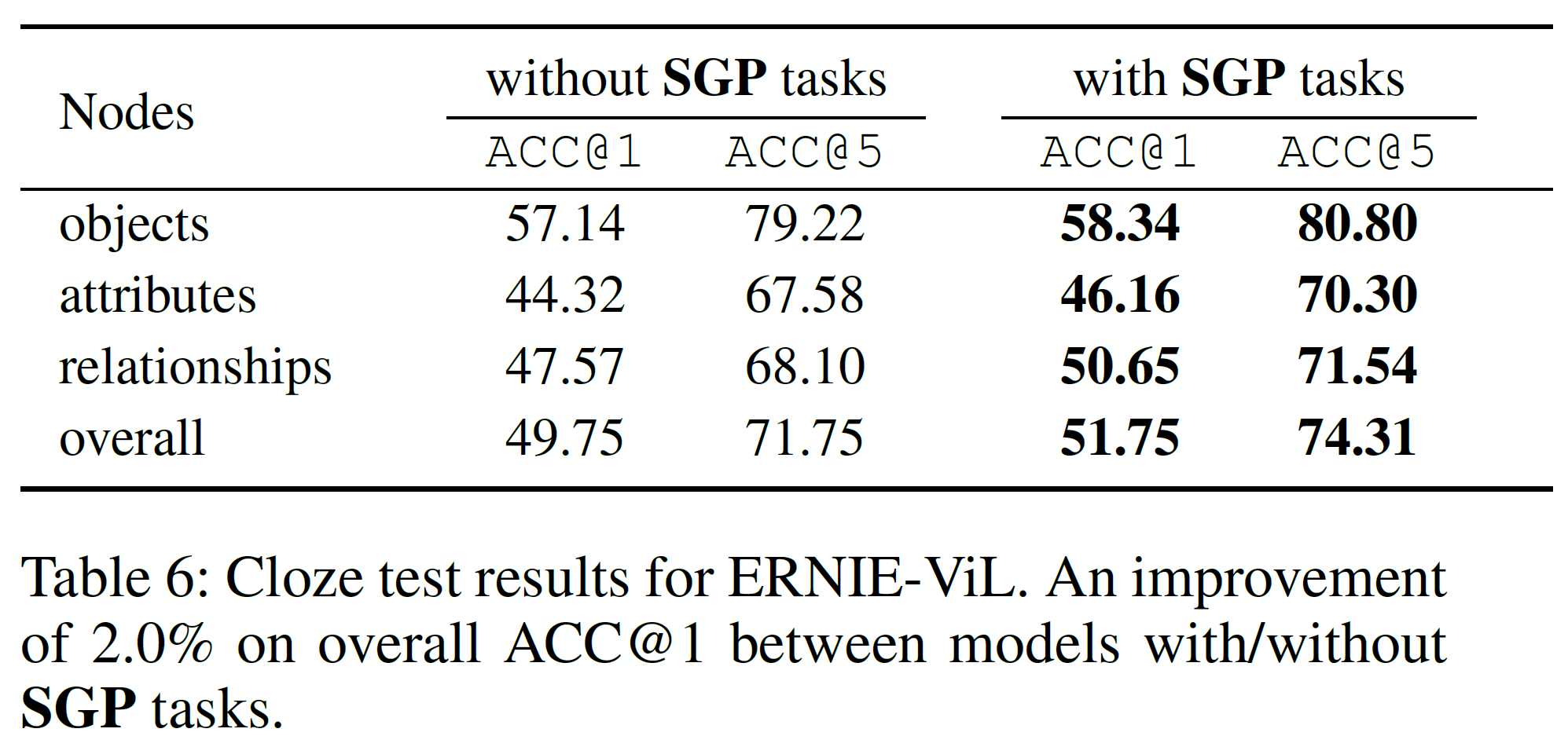
결과 예시를 아래에서 볼 수 있다.

SGP task 없이 학습한 모델은 세부 semantic alignments를 정확히 학습하지 못했기 때문에(일반단어와 세부 의미를 포함하는 단어를 구분하지 못하므로) 맞는 추론을 하기가 어렵다. 경우 3에서, 모델은 합리적인 token을 추론하긴 했으나 확신하는 정도가 SGP가 있을 때에 비해 더 낮다.
5. 결론(Conclusion)
시각-언어 결합표현을 학습하는 ERNIE-ViL을 제안하였다. Cross-modal 사전학습을 위한 전통적인 MLM task에 더하여 Scene Graph Prediction task를 새로 구성하여 cross-modal detailed semantic alignments를 특징화할 수 있다. 실험 결과로 SGP task로 인해 구조화된 지식을 통합하여 향상함으로써 다양한 downstream task에서 좋은 결과를 보였다.
추후 연구로 이미지에서 추출한 scene graph도 cross-modal 사전학습에 통합할 수 있을 것이다. 또 Graph Neural Networks는 더욱 구조화된 지식을 통합하는 데 고려할 수도 있다.
참고문헌(References)
논문 참조!