
ERNIE 논문 설명(ERNIE 2.0 - A Continual Pre-Training Framework for Language Understanding)
05 Jul 2021 | Paper_Review NLP ERNIE목차
- ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
이 글에서는 Baidu에서 만든 모델 시리즈 ERNIE 중 두 번째(ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding)를 살펴보고자 한다.
ERNIE 시리즈는 다음과 같다. 참고로 2번째는 Baidu가 아닌 Tshinghus University에서 발표한 논문이다.
- ERNIE: Enhanced Representation through Knowledge Integration, Yu sun el al., 2019년 4월
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding, Yu Sun et al., 2019년 6월
- ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph, Fei Yu et al., 2019년 6월
- ERNIE-Doc: A Retrospective Long-Document Modeling Transformer, Siyu Ding et al., 2020년 12월
- ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation, Yu Sun et al., 2021년 7월
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
논문 링크: ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
Official Code: Github
초록(Abstract)
최근 사전학습 모델들이 다양한 언어이해 문제에서 SOTA 결과를 달성해 왔다. 현재 사전학습 과정은 보통 모델을 여러 개의 단순한 task에서 학습시켜 단어나 문장의 동시 등장(co-occurrence)을 학습하는 것에 주안점을 둔다. 그러나, 이러한 동시등장성 외에도 다른 귀중한 정보인 named entity, 의미적 유사성, 담화 관계 등 어휘적, 구문, 의미적 정보가 학습 말뭉치에 존재한다. 이러한 정보를 추출하고 학습하기 위해서 사전학습 task를 점진적으로 증가시키고 연속적 multi-task 학습을 통해 이들 task에서 모델을 사전학습시키는 연속적 사전학습 framework인 ERNIE 2.0을 본 눈문에서 제안한다. 이 framework에 기반하여, 여러 task를 만들고 ERNIE 2.0을 학습시켜 영어(GLUE) 및 중국어 문제 총 16개의 task에서 BERT와 XLNet을 능가함을 보였다.

1. 서론(Introduction)
ELMo, OpenAI GPT, BERT, ERNIE 1.0, XLNet 등의 사전학습 언어표현은 감정분류, 자연어추론, 명명 객체 인식 등 다양한 자연어이해 문제에서 성능을 향상시킬 수 있다는 것이 입증되었다.
일반적으로 모델의 사전학습은 단어와 문장의 co-occurrence에 기반하여 모델을 학습시킨다. 그러나, 문장에는 사실 어휘적, 구문, 문맥적 정보가 존재하며 때로 이 정보가 더 중요할 수도 있다. 예를 들어 사람/지명 이름 등은 개념적 정보를 담고 있을 수 있다. 문장 순서나 문장의 유사성 등은 모델이 구조정보가 포함된 표현을 학습하는 것을 가능하게 한다. 그리고 문서 수준 의미적 유사성 혹은 문장 간 담화 관계는 모델이 의미정보가 포함된 표현을 학습할 수 있게 한다. 학습 말뭉치로부터 이러한 귀중한 정보를 활용하기 위해 연속적 사전학습 framework인 ERNIE 2.0을 제안한다.
ERNIE framework는 continual multk-task 학습 방식을 통해 다양한 customized task를 연속적으로 사용할 수 있다. 하나 혹은 여러 개의 새로운 task가 주어지면, 연속적 multi-task 학습 방식은 기존 지식을 잊어버리지 않으면서도 새로 소개된 task를 기존 task와 동시에 학습시킨다. 이러한 방식으로, ERNIE framework는 분산표현을 계속하여 학습할 수 있으며 모든 task는 같은 encoding network를 공유하여 이 인코딩의 어휘적, 구문, 의미적 정보가 여러 task 사이에서 공유되는 것을 가능하게 한다.
요약하면, 이 논문이 기여한 바는:
- customized 학습 task와 연속적 multi-task 학습 방식을 효과적으로 지원하는 ERNIE 2.0 framework를 제안하였다.
- 3가지의 비지도학습 task를 만들어 제안된 framework의 효율성을 확인하였다. 실험 결과는 ERNIE 2.0이 영어(GLUE)와 여러 중국어 task에서 BERT와 XLNet을 능가함을 보여주었다.
- ERNIE 2.0의 미세조정 코드와 모델을 Github에서 볼 수 있다.
2. 관련 연구(Related Work)
Unsupervised Learning for Language Representation
Annotation이 없는 많은 양의 데이터로 언어모델을 사전학습시켜 일반적인 언어표현을 학습하는 것은 효과적이다. 전통적인 방법은 보통 문맥무관 단어 임베딩에 초점을 두었다. Word2Vec과 GloVe가 단어별로 고정된 임베딩을 학습하는 대표적인 방식이다.
최근, 문맥 의존 언어표현을 학습하는 방식이 많이 연구되었다.
- ELMo는 언어모델에서 문맥민감(context-sensitive) 특징을 추출하는 방식을 제안하였고,
- OpenAI GPT는 Transformer를 수정하여 문맥민감 임베딩을 발전시켰다.
- BERT는 사전학습으로 다음 문장 예측 task를 추가하여 masked 언어모델을 만들었다.
- XLM은 교차 언어(cross-lingual) 언어모델을 학습하기 위해 1) 단일 언어 데이터에 의존하는 비지도학습 2) 2개의 언어 데이터를 leverage하는 지도학습 두 가지 방식을 결합하였다.
- MT-DNN은 여러 지도학습 방식을 사용하여 GLUE에서 좋은 결과를 냈으며,
- XLNet은 Transformer-XL을 사용하여 우도를 최대화하는 양방향 문맥을 학습하는 일반화된 자동회귀 사전학습 방식을 제안하였다.
Continual Learning
연속적 학습(continual learning)은 모델이 여러 task를 차례로 학습하도록 하되 새로 학습하면서 이전 학습한 task를 잊어버리지 않도록 하는 것을 목표로 한다. 이러한 방법은 계속해서 학습하고 정보와 지식을 쌓아가는 사람의 학습 방식에서 영감을 받은 것으로, 이러한 연속적 학습을 통해 모델은 이전 학습에서 얻은 지식을 활용하여 새로운 task에서도 좋은 성능을 발휘할 것으로 기대된다.
3. The ERNIE 2.0 Framework
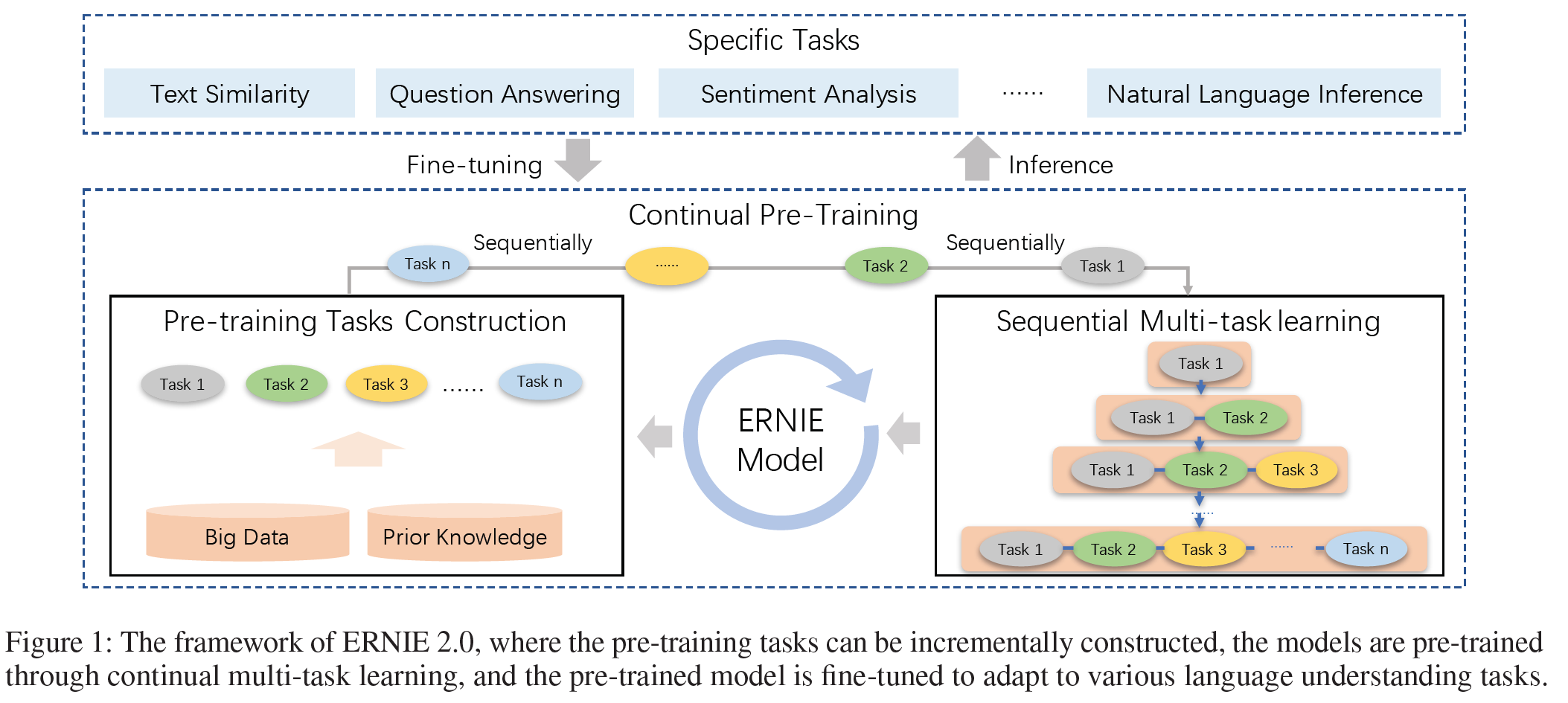
위 그림 1에서 보듯이 ERNIE 2.0은 널리 쓰이는 사전학습-미세조정 구조에 기초한다. 다른 점은 사전학습 단계에서 적은 수의 목적함수 대신 더 광범위한 사전학습 task를 사용하여 모델이 효율적으로 어휘적, 문맥적, 의미적 표현을 학습할 수 있도록 한 것이다. 이에 기초하여 ERNIE 2.0은 연속적 multi-task 학습을 통해 사전학습 모델을 업데이트할 수 있게 한다. 미세조정 단계에서 ERNIE는 먼저 사전학습 parameter를 사용하여 초기화한 다음 특정 task에 대해 미세조정하게 된다.
Continual Pre-training
연속적 사전학습은 두 단계로 이루어진다.
- 많은 데이터와 사전지식이 포함되도록 비지도 사전학습 task를 구성한다.
- ERNIE를 연속적 multi-task 학습을 통해 점진적으로 학습시킨다.
Fine-tuning for Application Tasks
각 단계에서 다른 종류의 task(word/structure/semantic - aware task)를 구성한다. 모든 사전학습 task는 자기지도 또는 약한 지도 signal에 의존하여 annotation 없이 대규모 데이터로부터 얻을 수 있다. 명명 객체나 구, 담화 관계와 같은 사전 지식은 대규모 데이터로부터 label을 생성하는 데 쓰인다.
Continual Multi-task Learning
ERNIE 2.0은 여러 개의 다른 task로부터 어휘적, 문맥적, 의미적 정보를 학습하는 것을 목표로 한다. 따라서 극복해야 할 두 가지 문제가 있다.
- 이전에 학습한 지식을 잊어버리지 않으면서 학습을 연속적으로 할 수 있을지
- 어떻게 효율적으로 사전학습할 것인지
이를 해결하기 위해 연속적 multi-task 학습 방법을 제안한다. 새로운 task를 만나면, 연속적 multi-task 학습 방법은 먼저 이전 학습된 parameter를 사용하고, 원래 학습하던 task와 새로운 task를 동시에 사용하여 학습한다. 이는 학습된 parameter가 이미 학습된 지식을 encode하도록 할 수 있다. 남은 문제는 효율적으로 학습할 방법인데, 이는 각 학습 task마다 $N$번의 반복학습을 배정함으로써 해결했다. 이러한 $N$번의 반복을 task에 자동으로 배정할 것을 필요로 하는데 이러한 방법을 통해 모델이 이전 지식을 잊어버리지 않도록 할 수 있다.
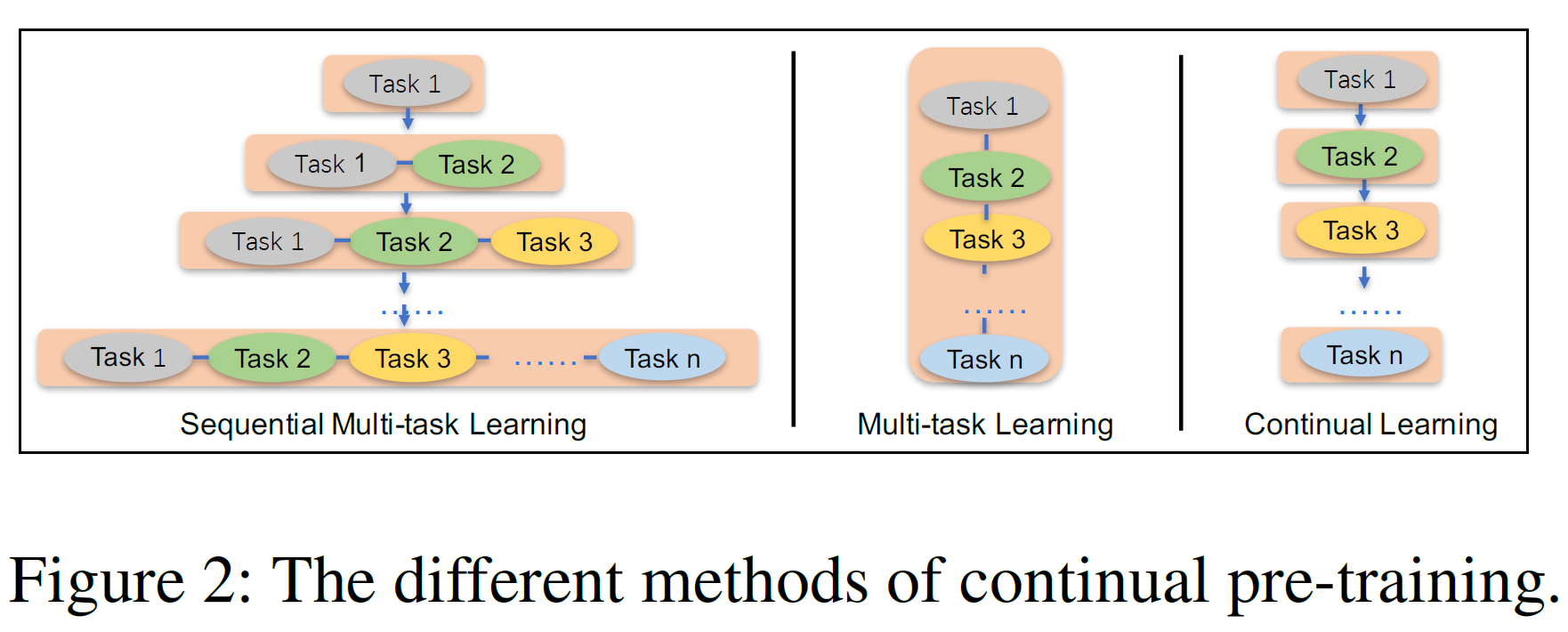
위 그림은 ERNIE와 기존의 multi-task 학습 및 연속학습 모델과의 차이를 보여준다. Scratch로부터 학습하는 Multi-task 학습은 같은 시간에 여러 개의 task를 학습할 수 있으나 모두 customized된 사전학습 task가 준비되어야 한다. 따라서 이 방법은 연속학습 이상의 학습 시간을 필요로 한다. 전통적인 연속학습 방법은 모델이 각 단계에서 오직 하나의 task만을 학습하는 문제가 있고 또한 그 구조상 이전 학습에서 얻은 지식을 잊어버릴 수 있다.
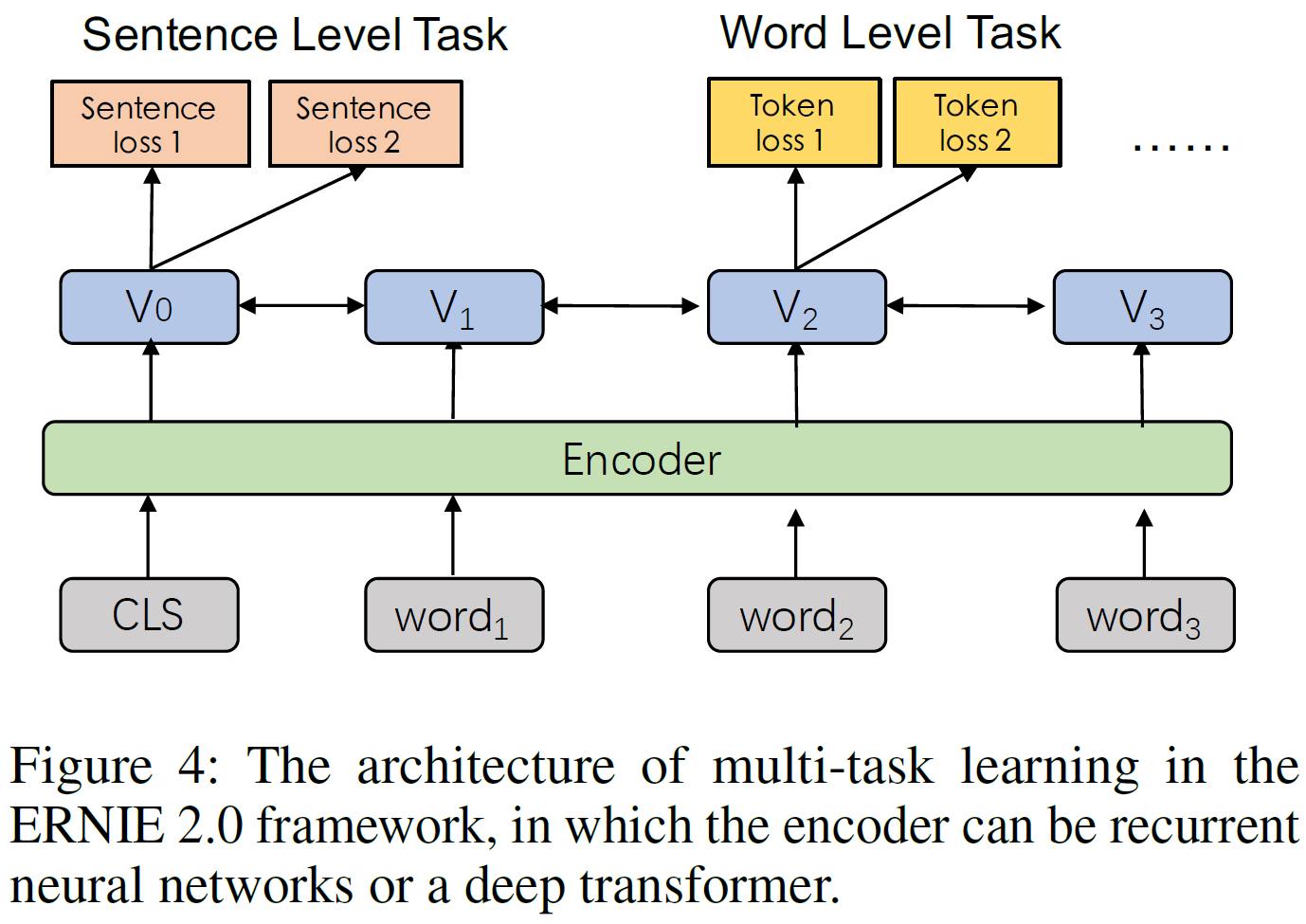
위의 그림에서 연속적 multi-task 학습의 각 단계가 문맥 정보를 인코딩하는 여러 개의 공유된 text encoding layer를 포함하고 있고 이는 RNN 혹은 deep Transformer를 통해 customized될 수 있다. 인코더의 parameter는 모든 학습 task에서 업데이트될 수 있다.
이 framework에서는 BERT와 비슷하게 두 가지 손실함수가 존재한다.
- 문장 수준 loss
- token 수준 loss
각 사전학습 task는 고유한 손실함수를 갖는다. 사전학습하는 동안, 하나의 문장수준 손실함수는 모델을 연속적으로 업데이트하기 위해 여러 개의 token 수준 손실함수와 결합될 수 있다.
Fine-tuning for Application Tasks
Task-specific 지도 데이터에서 사전학습의 장점은, 사전학습 모델은 여러 언어의 이해 task(예. QA, 자연어추론, 의미적 유사성 task)에 적용될 수 있다는 것이다. 각각의 downstream task는 미세조정 이후 고유한 미세조정 모델을 갖는다.
4. ERNIE 2.0 Model
이 framework의 효율성을 검증하기 위해 3가지의 비지도 언어처리 task를 구성하고 사전학습 모델 ERNIE 2.0을 개발하였다. 이 섹션에서 모델의 구현 방법을 설명한다.
Model Structure
Transformer Encoder 이 모델은 GPT나 BERT, XLM과 비슷하게 multi-layer Transformer를 기본 인코더로 사용한다.
Transformer는 self-attention을 통해 sequence에서 각 token의 문맥 정보를 잡아낼 수 있으며 문맥 임베딩의 sequence를 생성할 수 있다. Sequence가 주어지면 [CLS]를 맨 앞에 추가하고 여러 개의 입력이 들어오는 경우 구분을 위해 그 사이에 [SEP] token을 추가한다.
Taxk Embedding 모델은 서로 다른 task의 특성을 표현하기 위해 task embedding을 입력받는다. Task들은 각각 $0 \sim N$의 번호를 부여받으며 고유한 embedding을 갖는다. 이에 대응되는 token, segment, position, task embedding은 모델의 입력으로 사용된다. 각 task id를 미세조정 단계에서 모델을 초기화하는 데 사용한다. 모델 구조는 아래와 같다.
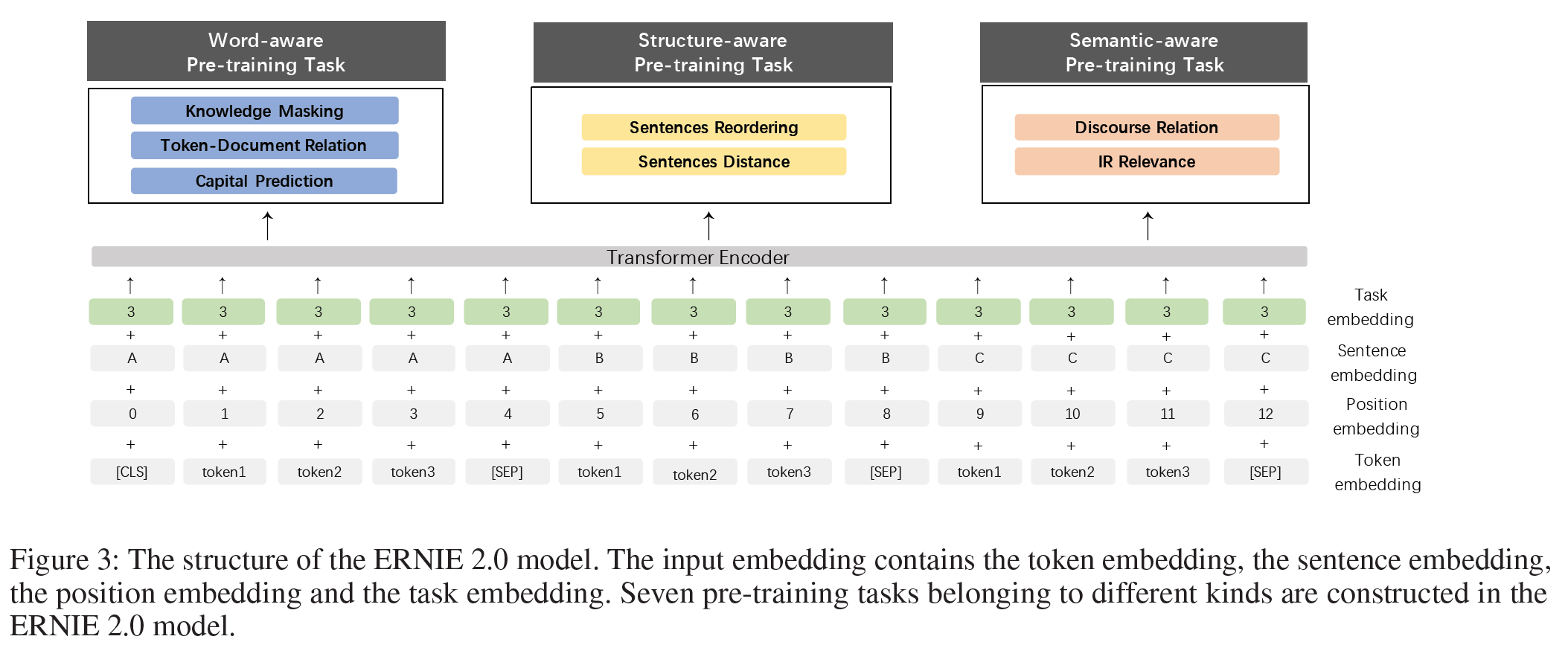
Pre-training Tasks
3가지의 사전학습 task를 구성하여 학습 데이터로부터 서로 다른 정보를 가져올 수 있도록 했다. 단어수준 task는 모델이 어휘적 정보를, 문장수준 task에서는 말뭉치의 구문 정보를, 의미수준 task는 의미정보를 가져오는 것에 초점을 둔다.
Work-aware Pre-training Tasks
- Knowledge Masking Task: ERNIE 1.0에서는 지식통합을 통해 표현의 질을 높이는 효과적인 방법을 제시하였다. phrase 및 명명 객체 전체의 masking과 masking된 전체 부분을 예측하는 task를 도입함으로써 지역적 및 전반적인 문맥에서의 의존 정보를 학습할 수 있게 하였다. 이를 ERNIE 2.0 모델의 초기 버전으로 학습하도록 하였다.
- Capitalization Prediction Task: 전체가 대문자로 쓰여진 단어는 보통 특별한 의미를 담고 있다. 이러한 경우 모델은 명명 객체 인식과 같은 문제에서 이점을 가지며 이를 고려하지 않는 모델은 다른 task에 더 적합하다. 두 모델의 장점을 합쳐서 어떤 단어가 대문자화된 단어인지 아닌지를 판별하는 task를 추가했다.
- Token-Document Relation Prediction Task: 이 task는 어느 segment의 token이 원본 문서의 다른 segment에 나타나는지를 예측하는 task이다. 경험적으로, 문서의 많은 부분에서 등장하는 단어는 보통 사용 빈도 자체가 높은 단어이거나 문서의 주요 주제와 관련이 있다. 따라서, 문서에서 자주 등장하는 단어를 판별하는 것을 통해 모델이 문서의 keyword를 찾는 능력을 증대시켜줄 수 있다.
Structure-aware Pre-training Tasks
- Sentence Reordering Task: 이 task는 문장 간의 관계를 학습하는 데 주안점을 둔다. 이 task의 사전학습 단계 동안 주어진 문단은 $1 \sim m$개의 segment로 임의로 쪼개어 이들 permutation의 모든 조합(combination) 중 하나로 섞는다. 사전학습 모델은 이 segment들의 원래 순서를 찾는 것이 목적이다. 경험적으로 이 문장 재배치 task는 사전학습이 문서 내 문장 간 관계를 학습할 수 있게 한다.
- Sentence Distance Task: 문서 수준 정보를 사용하여 문장 간 거리를 학습하는 task이다. 3-class 분류 문제로 모델링되는데, 0은 두 문장이 같은 문서에서 인접해 있는 것, 1은 두 문장이 같은 문서에 있는 것, 2는 두 문장이 서로 다른 문서에 존재함을 나타낸다.
Semantic-aware Pre-training Tasks
- Discourse Relation Task: 위에서 언급한 거리 (측정) 문제에 더하여, 두 문장 간 의미적 혹은 수사적인 관계를 예측하는 task를 소개한다. 영어 task를 위한 사전학습 모델을 학습시키기 위한 데이터를 사용하였다. 같은 논문에서 제안된 방법을 따라 사전학습을 위한 중국어 데이터셋을 구성하였다.
- IR Relevance Task: 정보 검색에서 짧은 텍스트 관계를 학습하는 사전학습 task를 추가하였다. Query를 첫 번째 문장, title을 두 번째 문장으로 구성하며 상업 검색엔진에서 얻은 검색 기록 데이터를 사전학습 데이터로 사용하였다. 이 task는 3-class 분류 문제로 query과 title 간 관계를 예측한다. 0은 강한 관계(유저가 검색 후 제목을 클릭함), 1은 약한 관계(제목이 검색 결과로 나왔지만 유저가 클릭하지는 않음), 2는 query와 title이 무관하며 의미 정보의 관점에서 임의(로 선택됨)임을 나타낸다.
Experiments
ERNIE 2.0을 다른 SOTA 모델들과 비교하였다. 영어 task를 위해 GLUE에서 BERT 및 XLNet, 중국어 task를 위해 여러 task에서 BERT와 ERNIE 1.0과 비교하였다. 또한 본 논문의 방법을 multi-task 학습과 전통적인 연속학습 방법과 비교하였다.
Pre-training and Implementation
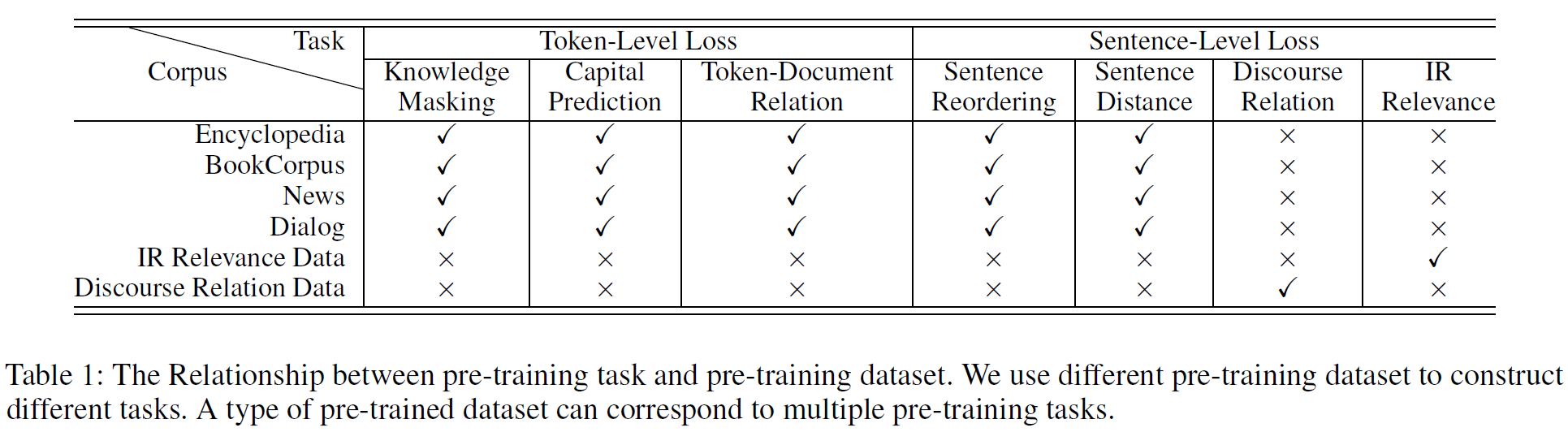
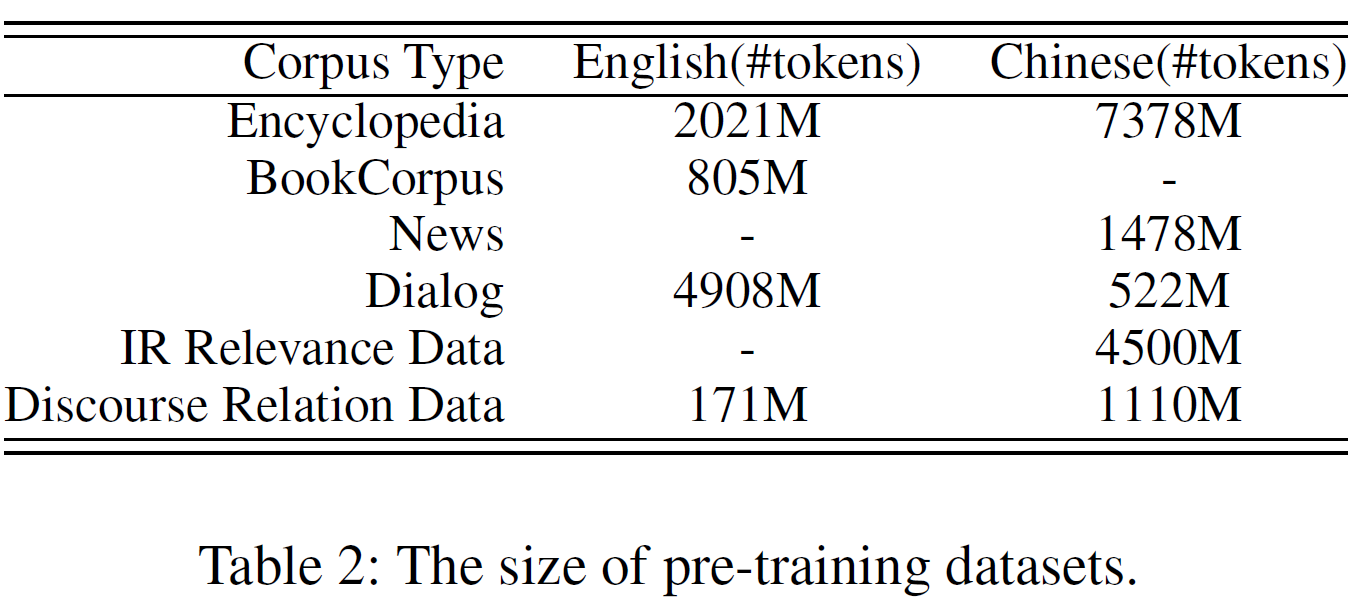
Pre-training Data: BERT와 비슷하게 일부 영어 말뭉치는 Wikipedia와 Book-Corpus에서 크롤링하여 가져왔다. 또한 Reddit과 Discovery data를 담화 관계 데이터로 사용하였다. 중국어 말뭉치는 검색 엔진으로부터 백과사전, 뉴스, 대화, 정보검색, 담화관계 데이터 등을 수집하였다. 표 1에서 사전학습 task와 데이터의 관계를, 데이터의 세부 정보를 표2에 기술하였다.
Pre-training Settings: BERT와 비교를 위해 같은 크기의 Transformer 모델을 만들었다(base: 12 layers, 12 self-attention heads, 768-dim hidden size, large: 24 layers, 16 self-attention heads, 1024-dim hidden size). XLNet의 모델 세팅은 BERT와 같다.
ERNIE 2.0은 base 모델에서 48개의 Nvidia v100 GPU, large 모델에서 64개의 Nvidia v100 GPU를 사용하였다. ERNIE는 Baidu에서 end-to-end 오픈소스 딥러닝 플랫폼으로 개발한 PaddlePaddle 위에서 구현되었다.
Hyperparameter 세팅은 $\beta_1 = 0.9, \beta_2 = 0.98$이고 batch size는 393216 token이다. Learnint rate는 영어에서 $lr=5e-5$, 중국어 모델에서 $lr=1.28e-4$이며 decay scheme noam(4000 step의 warmup 포함)을 따른다. float16 연산으로 학습을 가속화했고 각 사전학습 task는 수렴할 때까지 진행되었다.
Fine-tuning Tasks
English Task: GLEU benchmark를 사용하였다.
Chinese Tasks: 9개의 중국어 자연어처리 task에서 실험을 진행하였다(독해, 명명 객체 인식, 자연어추론, 의미적 유사성, 감정분석, 질의응답 등). 중국어 데이터셋은 다음 중에서 선택되었다.
- Machine Reading Comprehension (MRC): CMRC 2018 (Cui et al. 2018), DRCD (Shao et al. 2018), and DuReader (He et al. 2017).
- Named Entity Recognition (NER): MSRA-NER (Levow 2006).
- Natural Language Inference (NLI): XNLI (Conneau et al. 2018).
- Sentiment Analysis (SA): ChnSentiCorp.
- Semantic Similarity (SS): LCQMC (Liu et al. 2018), and BQ Corpus (Chen et al. 2018).
- Question Answering (QA): NLPCC-DBQA.
Implementation Details for Fine-tuning
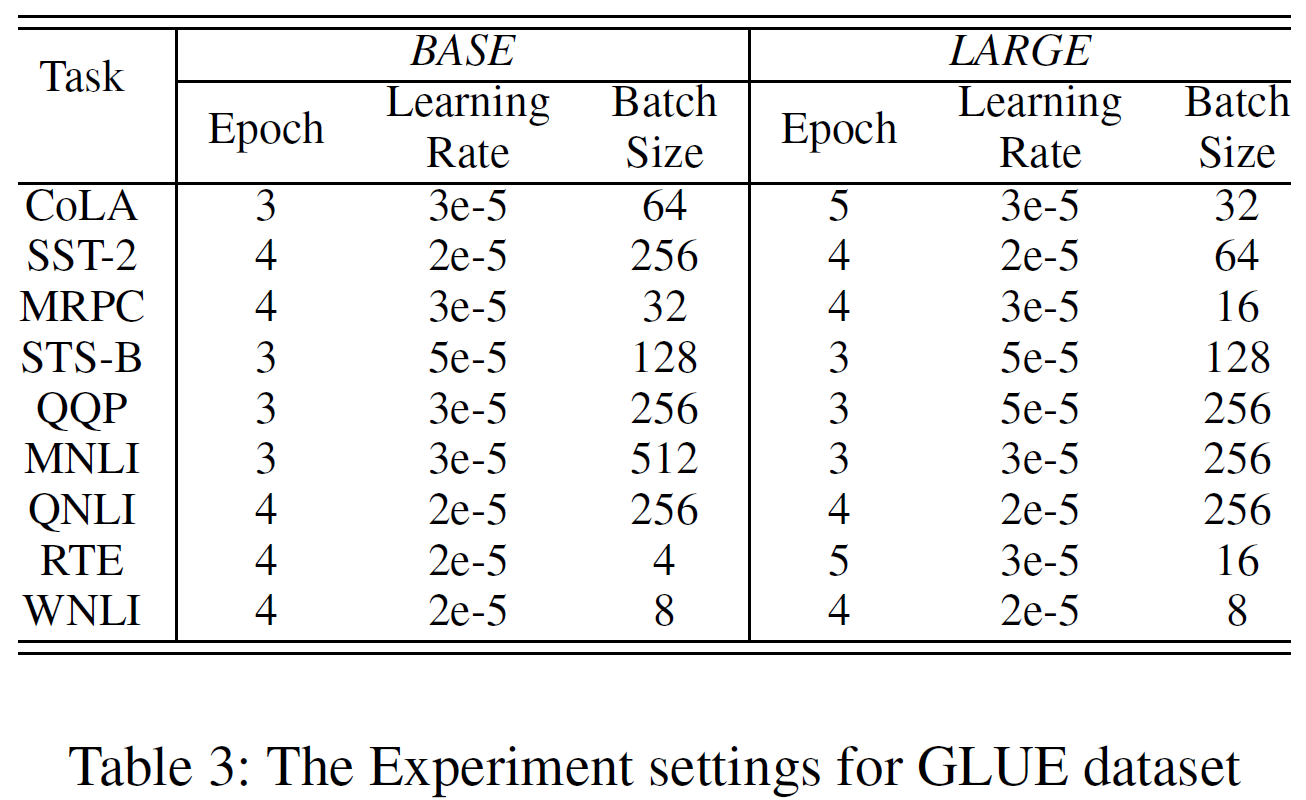
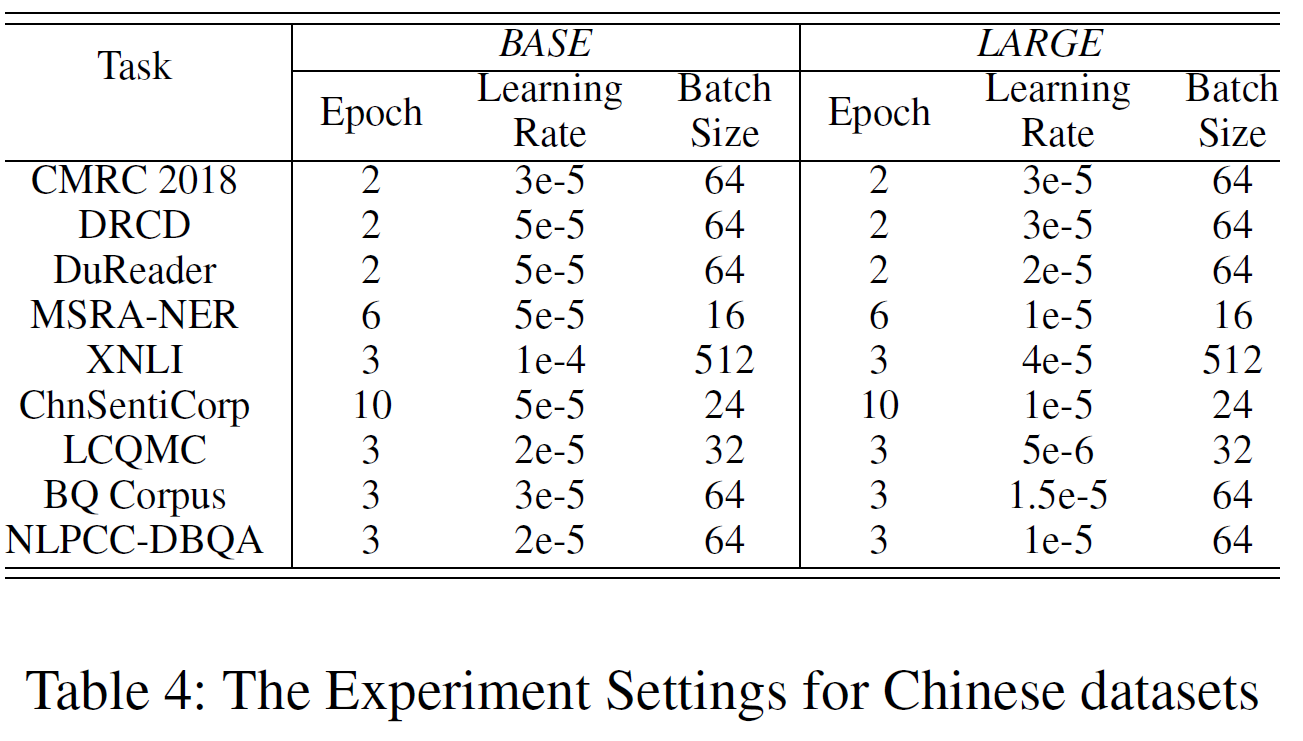
영어 및 중국어 세팅(Epoch, Learning rate, Batch size)을 아래 표에 표시하였다.
Experimental Results
Results on English Tasks: 각 방법의 base와 large 모델을 GLUE에서 평가하였다. XLNet의 dev set만 보고되어 있는 관계로 다른 방법도 dev set에서의 결과를 표시한다. BERT와 XLNet과 비교를 위해 단일 task와 단일 모델 ERNIE 2.0을 테스트하였다. GLUE에 대한 결과는 표 5와 같다.
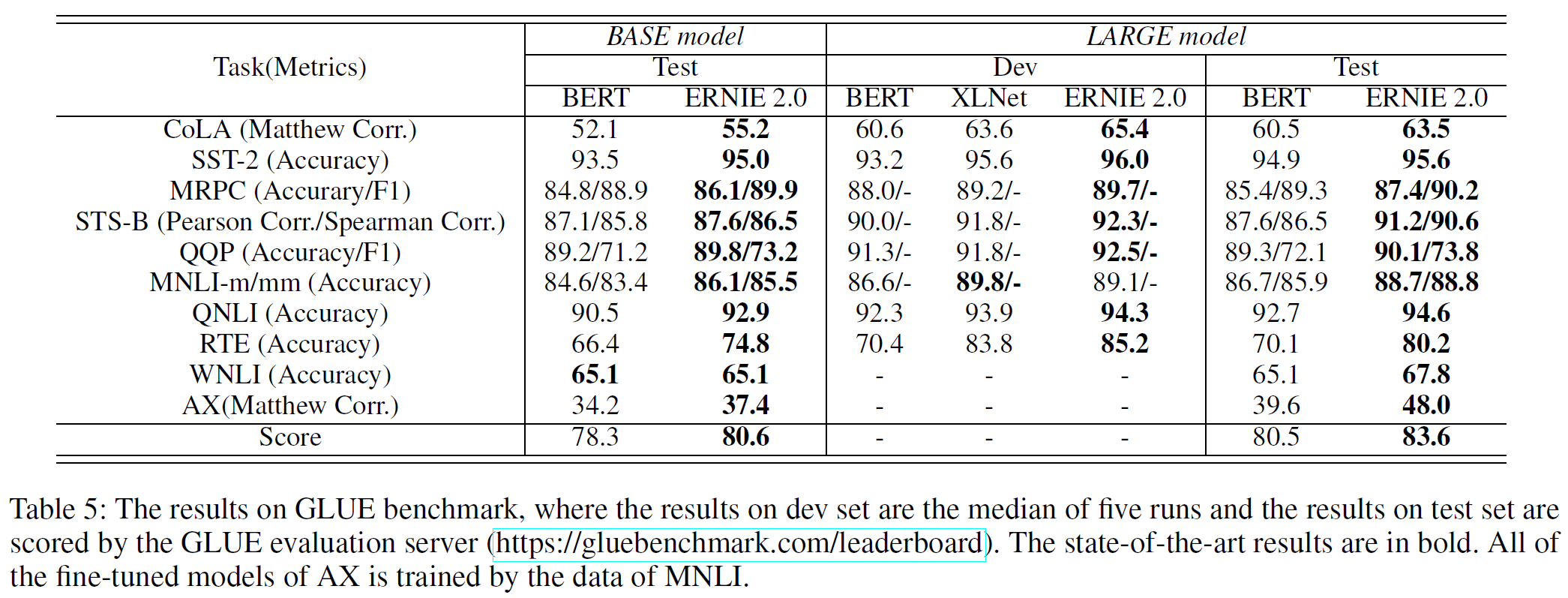
ERNIE 2.0 base 모델이 BERT base 모델을 모든 task에서 상회하며 80.6점을 얻었다. Large 모델의 경우 ERNIE 2.0이 BERT와 XLNet을 단 한 개의 task를 제외하고 모든 부분에서 상회하며 GLUE 점수는 83.6점으로 3.1% 향상시킨 것을 볼 수 있다.
Results on Chinese Tasks: 표 6은 중국어 task에서 결과를 보여준다.
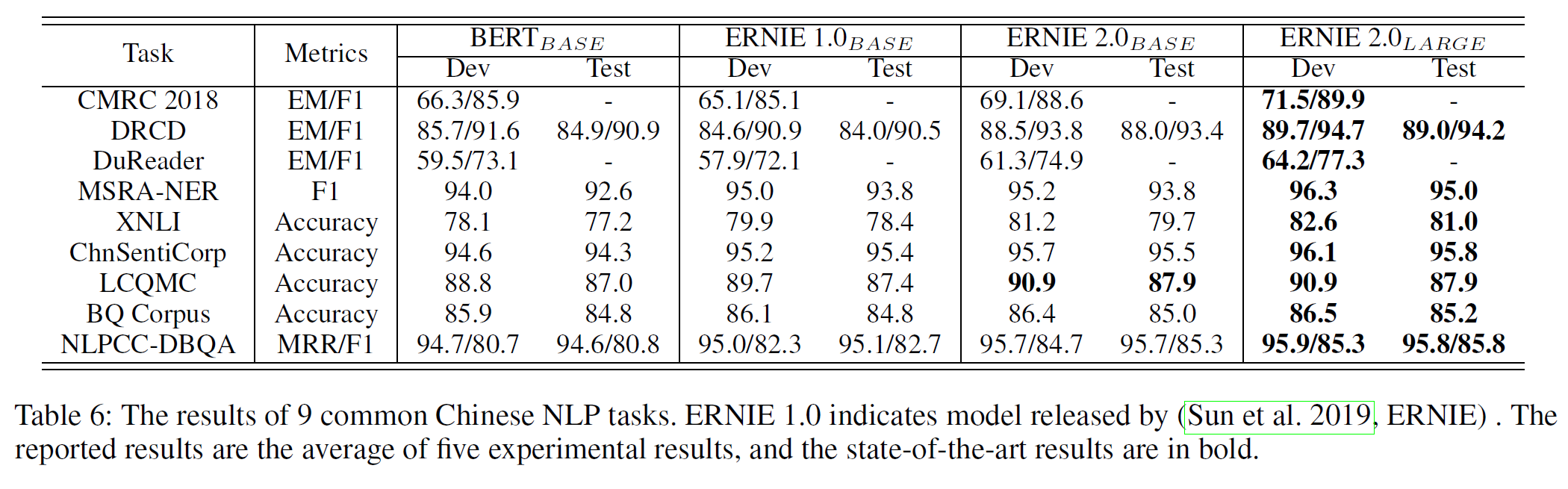
ERNIE 1.0이 BERT base를 5개의 task에서 상회함을 보여주지만 이상적이지는 않은 결과인데 사전학습의 차이로 보인다. 구체저으로 ERNIE 1.0 base의 경우 길이 128 이상의 instance를 포함하지 않으나 BERT base는 512까지 사용한다. ERNIE 2.0은 BERT base를 모든 task에서 압도하며 ERNIE 2.0 large 모델은 제시된 모든 중국어 task에서 SOTA 결과를 얻었다.
Comparison of Different Learning Methods
ERNIE 2.0 framework에 적용한 연속적 mult-task 학습 전략의 효과를 분석하기 위해 그림 2에서 나온 2가지 방법을 비교하였다. 아래 표 7에서 세부 사항을 볼 수 있다. 모든 방법에서 학습 반복횟수는 각 task에서 같다고 가정한다. 각 task는 50k회의 반복 학습을 하며 총 200k번의 학습을 한다. multi-task는 한 단계에서 모든 task를, 연속적 사전학습 방법은 한 번에 하나의 task를, 연속적 multi-task 학습 방법(본 논문에서 제시)는 각 단계마다 서로 다른 반복횟수를 적용하여 점진적으로 학습하는 것을 볼 수 있다.
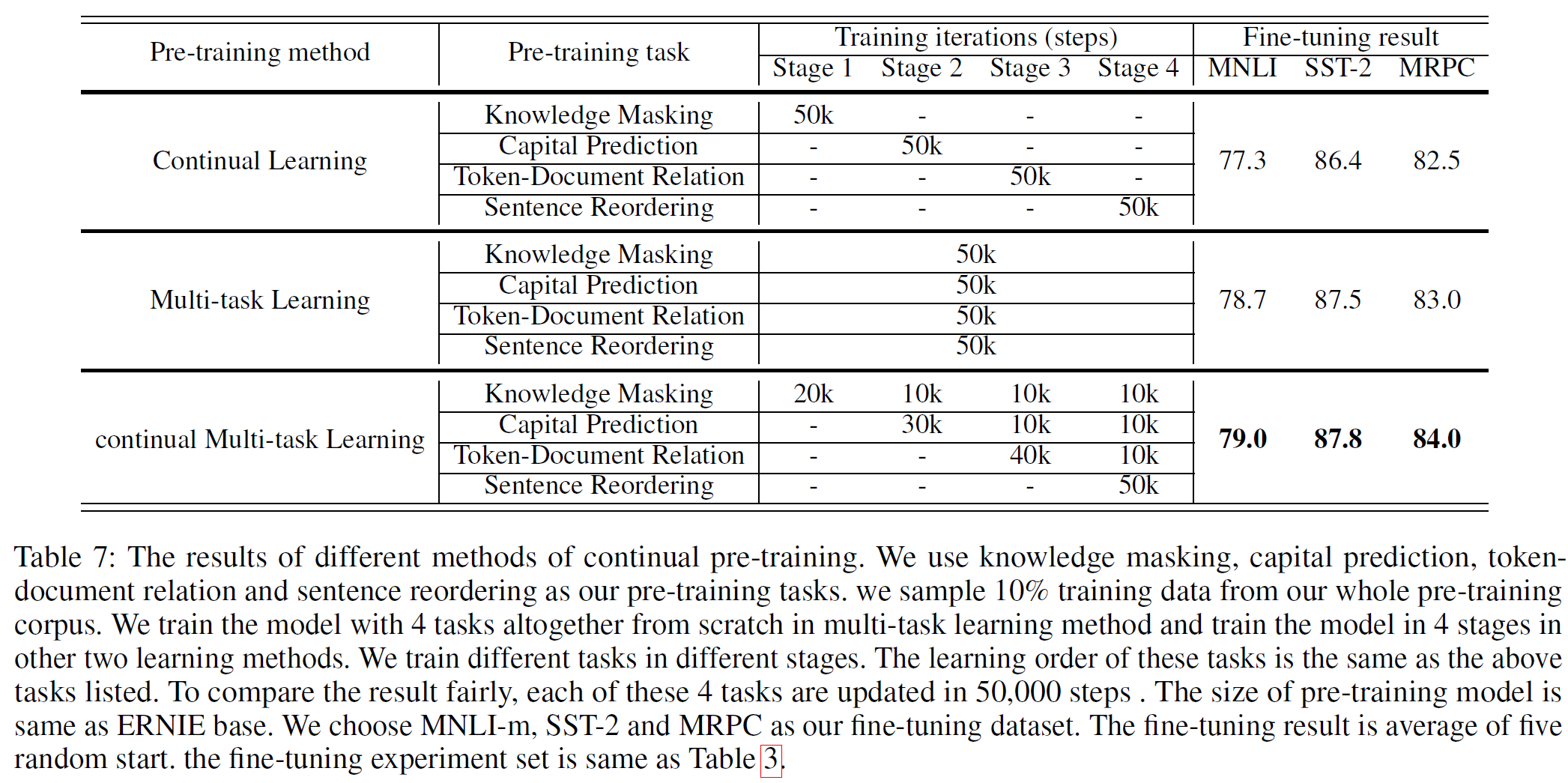
실험 결과에서 본 논문에서 제시된 방법이 효율을 희생하지 않으면서 가장 효과가 좋다는 것을 확인할 수 있다. 이는 본 논문에서 제시된 사전학습 방식이 새로운 task를 학습하는 데 있어 더 효율적이고 효과적임을 보여준다. 또한, 이 비교 결과는 연속적 학습 방법이 단순 multi-task 학습 방법을 능가한다는 것을 뜻하고 새로 제시된 방법은 이전 학습에서 얻은 지식을 잘 잊어버리지 않는다는 것을 의미한다.
결론(Conclusion)
본 논문에서 연속적 사전학습 framework인 ERNIE 2.0을 제안하였고 사전학습 task들은 점진적으로 추가되며 연속적 multi-task 학습 방법을 통해 학습된다. 이 framework에 기반하여 언어의 다양한 부분을 커버하는 여러 사전학습 task를 구성하였다. GLUE와 여러 중국어 task에서 좋은 결과를 보였으며 BERT와 XLNet을 상회하는 성과를 얻었다. 앞으로 모델의 성능을 더 발전시킬 수 있는 사전학습 task들을 소개하며 더 세련된 학습 방식을 연구할 계획이다.
참고문헌(References)
논문 참조!