
ERNIE 논문 설명(ERNIE - Enhanced Representation through Knowledge Integration)
14 Jun 2021 | Paper_Review NLP ERNIE목차
- ERNIE: Enhanced Representation through Knowledge Integration
이 글에서는 Baidu에서 만든 모델 시리즈 ERNIE 중 첫 번째(ERNIE: Enhanced Representation through Knowledge Integration)를 살펴보고자 한다.
ERNIE 시리즈는 다음과 같다. 참고로 2번째는 Baidu가 아닌 Tshinghus University에서 발표한 논문이다.
- ERNIE: Enhanced Representation through Knowledge Integration, Yu sun el al., 2019년 4월
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding, Yu Sun et al., 2019년 6월
- ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph, Fei Yu et al., 2019년 6월
- ERNIE-Doc: A Retrospective Long-Document Modeling Transformer, Siyu Ding et al., 2020년 12월
- ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation, Yu Sun et al., 2021년 7월
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
ERNIE: Enhanced Representation through Knowledge Integration
논문 링크: ERNIE: Enhanced Representation through Knowledge Integration
Official Code: Github
초록(Abstract)
Novel Language Representation Model인 ERNIE(Enhanced Representation through kNowledge IntEgration)을 제안한다. BERT가 masking 전략을 쓴 것처럼, ERNIE는 phrase-level masking과 entity-level masking을 포함한 여러 knowledge masking 표현을 학습하도록 설계되었다.
- Phrase-level masking은 conceptual unit으로서 여러 단어로 구성된 전체 phrase를 masking한다.
- Entity-level masking은 여러 단어로 이루어진 entity를 masking한다.
실험 결과는 ERNIE가 자연어 추론, 의미적 유사성, 명명 개체 인식, 감정분석, 질답 등 5개의 중국어 자연어처리 과제에서 SOTA를 능가하였다. 또 cloze test에서 더 강력한 지식 추론 능력을 가진다.
얘가 Ernie이다. ELMo 이후로 세서미 스트리트에 끼워맞추는 게 유행..

BERT가 강력한 파괴력을 가졌던 것처럼, 중국 바이두에서 만든 이 모델을 Ernie 시리즈로 밀고 나간다. GLEU benchmark 등 영어에서도 실험하지만, 만든 곳이 그 곳이니만큼 중국어에 상당 부분 초점이 맞춰져 있다.
1. 서론(Introduction)
이전까지 언어표현 사전학습 모델은 동시에 등장하는 단어들을 바탕으로(co-occurence) 학습을 진행해 왔다. Word2vec 등이 단어표현에서 대표적인 예시이고, ELMo, BERT 등의 연구에서는 여러 전략을 사용하여 단어표현을 발전시키고 downstream task에 더욱 효율적이게 만들었다.
이러한 모델들의 대부분은 단지 문맥 안에서 masking된 단어를 예측하는 방식으로 진행되는데 이는 문장에 대한 사전 지식을 고려하지 않는다. 예를 들어 “Harry Potter is a series of fantasy novels written by J. K. Rowling”이라는 문장에서, Harry Potter는 소설 이름, J.K. Rowling은 작가 이름이다. Harry Potter를 masking해서 지웠을 때 (사람은) 빠진 단어가 무엇인지 쉽게 유추할 수 있지만 모델은 Harry Potter와 J.K. Rowling의 관계를 알지 못하며 예측하지 못한다. 여기서 모델이 만약 사전지식을 더 잘 알 수 있다면, 언어표현을 더욱 유용하게 만들 수 있다고 생각할 수 있다.
이 논문에서, knowledge masking 전략을 사용한 ERNIE를 소개한다. 기본적인 masking 전략에 더해 entity-level masking과 phrase-level masking을 사용한다. Phrase를 하나의 entity로 취급하여 사용하는 방식으로 학습하며 학습 내내 하나의 entity처럼 사용된다. 이 방식으로, entity와 phrase에 대한 사전지식이 암묵적으로 학습된다. ERNIE는 knowledge를 명시적으로 입력받지 않고 암묵적으로 학습하고 더 긴 의미적 의존성을 파악함으로써 더 나은 일반화 및 적응 능력을 가질 수 있다.
학습 비용을 위해서 5가지 중국어 NLP task에서 사전학습을 진행하며, 대부분에서 SOTA 결과를 달성했다.
이 논문의 기여한 바는,
- Entity와 Phrase를 하나의 unit으로 취급하여 masking하고 학습하는 방식으로 문맥적, 의미적 정보를 암묵적으로 학습하는 새로운 언어모델을 제시하였다.
- ERNIE는 다양한 중국어 NLP task에서 SOTA 결과를 달성하였고,
- ERNIE의 코드와 사전학습된 모델을 공개하였다.
2. 관련 연구(Related Work)
Context-independent Representation
단어표현을 연속적인 벡터로 표현하는 방식은 긴 역사를 가지고 있다. 2003년 NNLM에서는 MLP를 사용하여 단어 벡터표현을 학습하였다.
전통적인 방법은 문맥과 독립적으로 학습하는 방식으로 WordVec, Glove 등이 있다. 이들은 대규모 말뭉치를 입력으로 받고 수백 차원 정도의 단어표현을 학습하며 각 단어에 대해 하나의 embedding 표현을 생성한다.
Context-aware Representation
그러나, 문맥을 고려하지 않고서는 완전한 단어표현을 학습할 수 없다. 각 단어는 문맥에 따라서 다양한 의미를 갖기 때문이며 Cove, ELMo, BERT, GPT2 등에서는 문맥을 고려하여 단어표현을 생성하도록 했다.
Heterogeneous Data
다차원적 비지도 데이터에서 사전학습한 의미적 encoder는 전이학습 성능을 높일 수 있다. Universal sentence encoder(Cer et al., 2018), XLM(Lample and Conneau, 2019)이 Wikipedia 등에서 학습하여 여러 MT task에서 좋은 성능을 보였다.
3. Methods
모델의 Transformer encoder는 3.1절, Knowledge Integration은 3.2절, BERT와 ERNIE의 비교는 아래 그림을 참조한다.
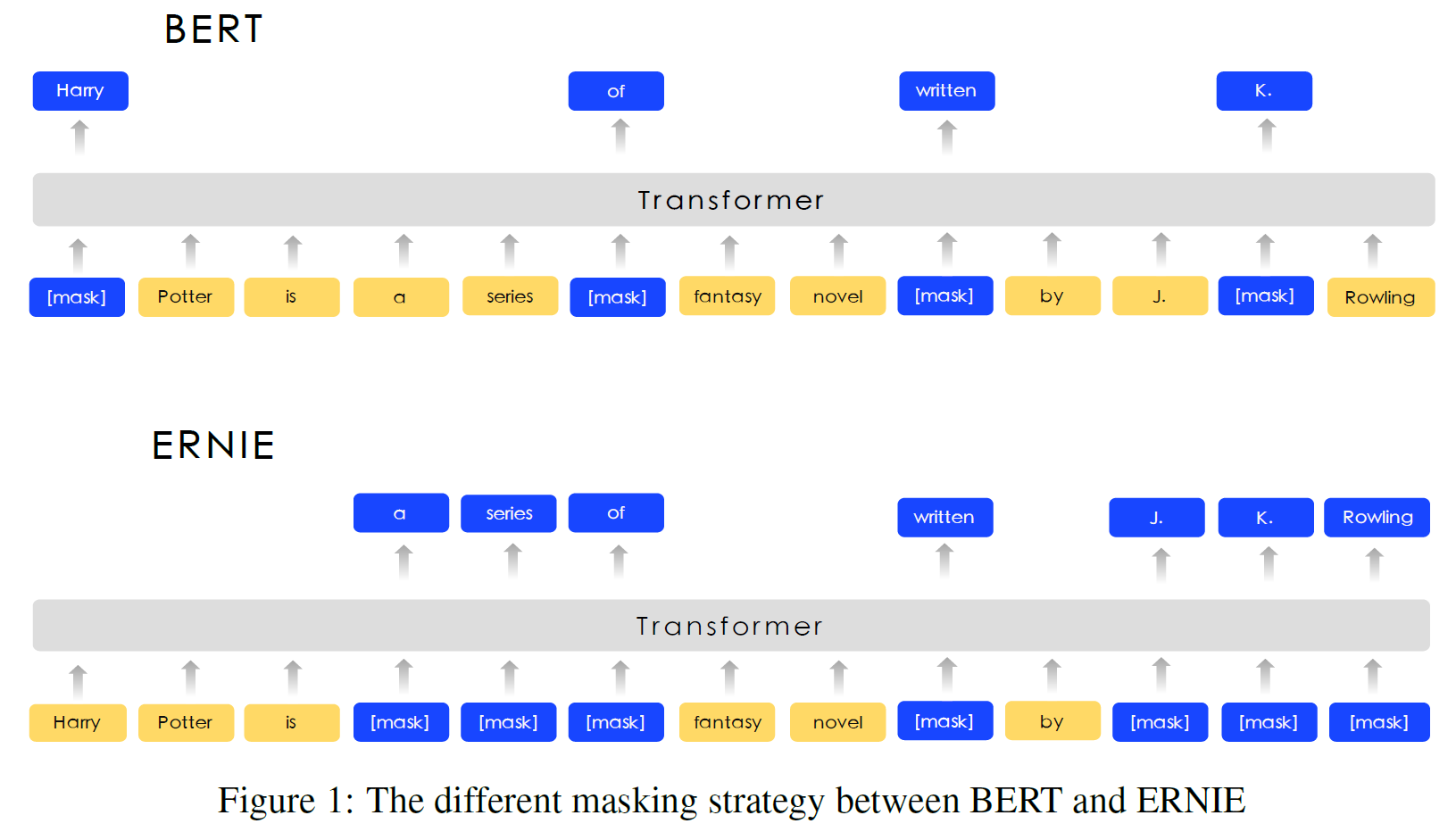
BERT는 각 단어를 일정 확률로 masking하고 이를 예측하지만, ERNIE는 단어뿐 아니라 독립체(entity), 구(phrase) 전체를 하나의 unit으로 취급하여 masking한다.
3.1. Transformer Encoder
ERNIE는 GPT, BERT, XLM처럼 multi-layer Transformer를 기본 인코더로 사용한다. Transformer는 self-attention을 통해 각 token의 문맥 정보를 잡아낼 수 있고 문맥적 embedding의 sequence를 생성한다.
중국어 말뭉치를 위해, CJK Unicode range에 있는 모든 문자 주변에 공백을 추가하고 WordPiece tokenizer를 사용하였다. 주어진 token에 대해서 그 입력 표현은 주변 token, segment & position embedding(잘 모르겠으면 BERT 참고)의 embedding을 더하여 구성한다. 첫 번째 token은 [CLS]이다.
3.2. Knowledge Integration
사전지식을 사용하는데, 이를 직접 집어넣지는 않고, entity와 phrase 수준 지식을 통합하기 위해 다단계 knowledge masking 전략을 제안한다. 문장에서 여러 masking 수준은 Figure 2에서 볼 수 있다.

3.2.1. Basic-Level Masking
기본 단위(영어는 한 단어, 중국어는 한 글자)을 학습하는 단계로 15%의 기본 단위를 임의로 masking하고 Transformer는 이를 예측하도록 한다. 여기서는 고수준의 의미 정보를 얻기는 힘들다.
3.2.2. Phrase-Level Masking
여러 단어나 글자를 하나의 개념적 단위로 묶은 것으로 영어는 어휘분석과 chunking, 언어의존적 분할 도구를 사용하여 단어/phrase 정보를 얻는다. 이 단계에서는 한 phrase 안에 속하는 모든 단어(글자)를 한 번에 masking한다. 이를 통해 phrase 정보가 단어 임베딩에 포함된다.
3.2.3. Entity-Level Masking
Name Entity는 사람, 지역, 조직, 상품 등을 포함하며 적절한 “이름”으로 나타내어진다. 추상적이거나 물리적 실체를 가질 수도 있다. 보통 entity는 문장에서 중요한 정보를 갖는다. Phrase 단계와 비슷하게 named entity가 문장에서 어떤 것이 있는지 분석하고 masking할 때는 한 entity 안에 속하는 모든 단어/글자를 한 번에 masking하고 이를 예측하도록 학습한다.
4. Experiments
ERNIE는 비교를 위해 Bert-base와 같은 모델 크기를 갖는다. 12 Encoder layers, 768 hidden units, 12 attention heads를 포함한다.
4.1. Heterogeneous Corpus Pre-training
중국 Wikipedia, Baidu Baike/News/Tieba 말뭉치를 사용하였으며 각 문장 수는 21M~54M이다. 각각 언어모델링의 기초가 되는 백과사전 글과 영화/배우 이름 등에 대한 정보, Reddit과 같은 토론, DLM의 것과 같은 내용을 포함한다. 한자는 번체에서 간체로, 영어는 소문자로 변환하고 17,964개의 공유 유니코드 문자를 포함한다.
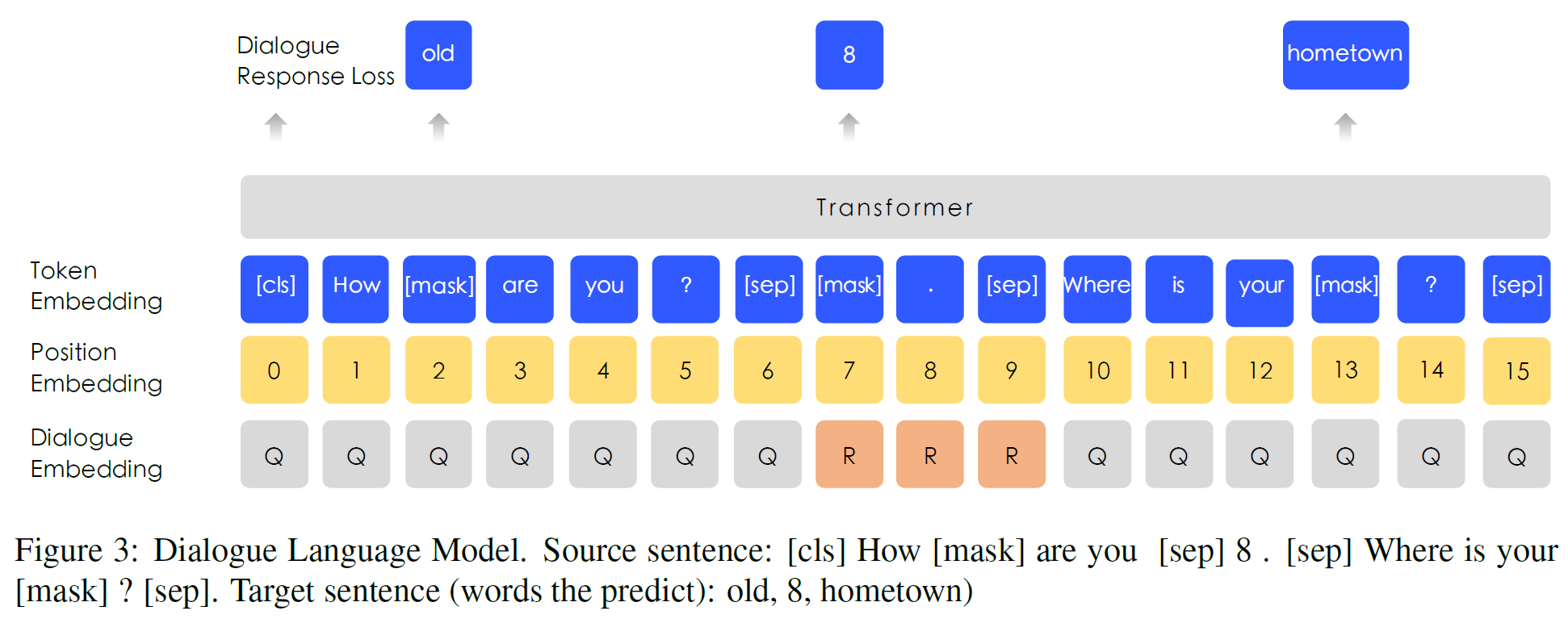
4.2. DLM
Dialogue Language Model의 약자로 BERT의 token-position-segment embedding과 비슷한 구조를 가지지만, segment embedding이 2개의 문장을 뜻하는 0, 1이 아닌 multi-turn 대화를 나타내도록 되어 있다(Question-Response-Question 등. QRQ, QRR, …)
이는 ERNIE가 대화에서 암묵적인 관계를 학습할 수 있게 한다.
4.3. Experiments on Chinese NLP Tasks
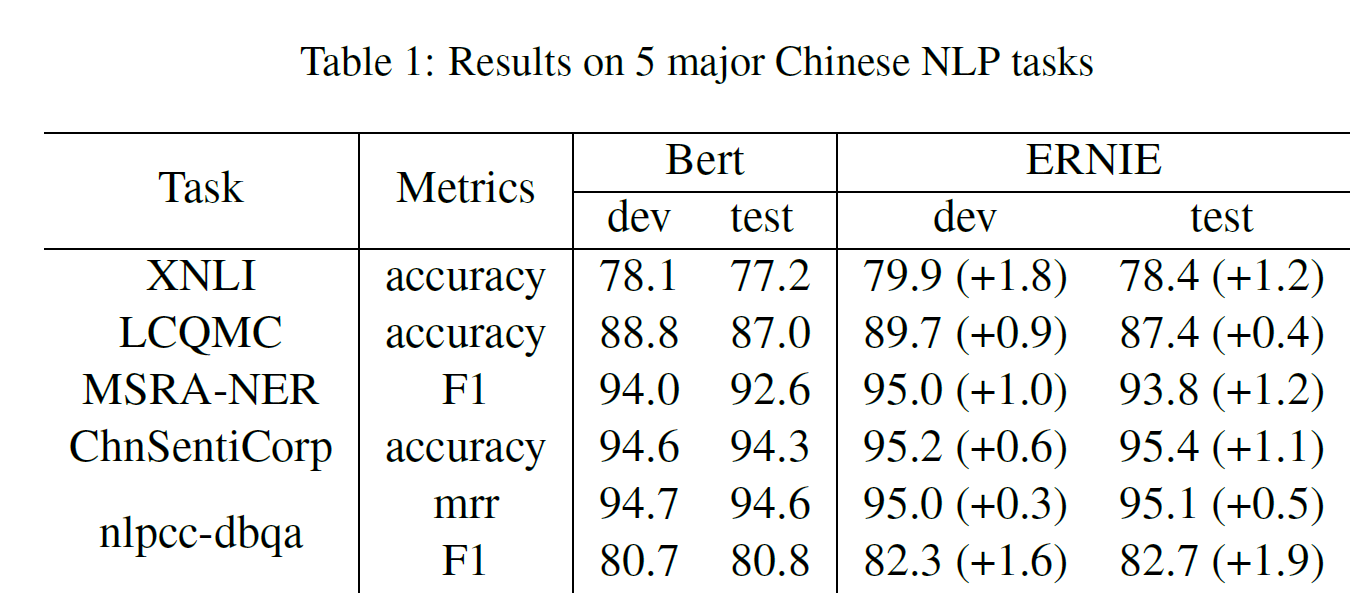
5가지 task에 대해 진행하였다.
- 자연어추론: XNLI(Cross-lingual NLI) 말뭉치는 모순, 중립, 함의를 포함하며 중국어 포함 14개 언어 쌍이 있다.
- Semantic Similarity: LCQMC 데이터셋 사용, 두 문장이 같은 내용(intention)을 포함하는지를 판별하는 task.
- Name Entity Recognition: Microsoft Research Asia에서 배포한 MSRA-NER 데이터셋 사용. 사람/장소/조직 이름 등을 포함하는 entity를 갖고 있으며 sequence labeling task로도 볼 수 있다.
- Sentiment Analysis: ChnSentiCorp 데이터셋 사용. 호텔, 책, 전자컴퓨터와 같은 여러 domain의 comment를 포함하며 어떤 문장의 긍정/부정을 평가한다.
- Retrieval Question Answering: NLPCC-DBQA 데이터셋 사용. 질문에 맞는 답을 선택하는 것이다. 평가 방법은 MRR과 F1 score 사용.
4.4. Experiment results
ERNIE가 모든 task에서 BERT를 능가한다. 중국어 NLP task에서는 SOTA를 찍고, BERT에 비해서 절대오차 1% 이상으로 우세하다. 이러한 이득은 지식 통합 전략에 따른 것이다.
4.5. Ablation Studies
Knowledge Masking 전략의 효과를 알아보기 위해 전체의 10% 학습 데이터를 뽑고, 각 level(word/phrase/entity)의 masking 전략 중 어느 것을 적용하는지에 따라 성능 차이가 좀 난다. phrase와 entity 수준에서 masking을 하는 것이 성능이 더 좋은 것을 볼 수 있다. 전체 데이터셋을 사용하면 10%일 때에 비해 0.8%의 향상이 있다.
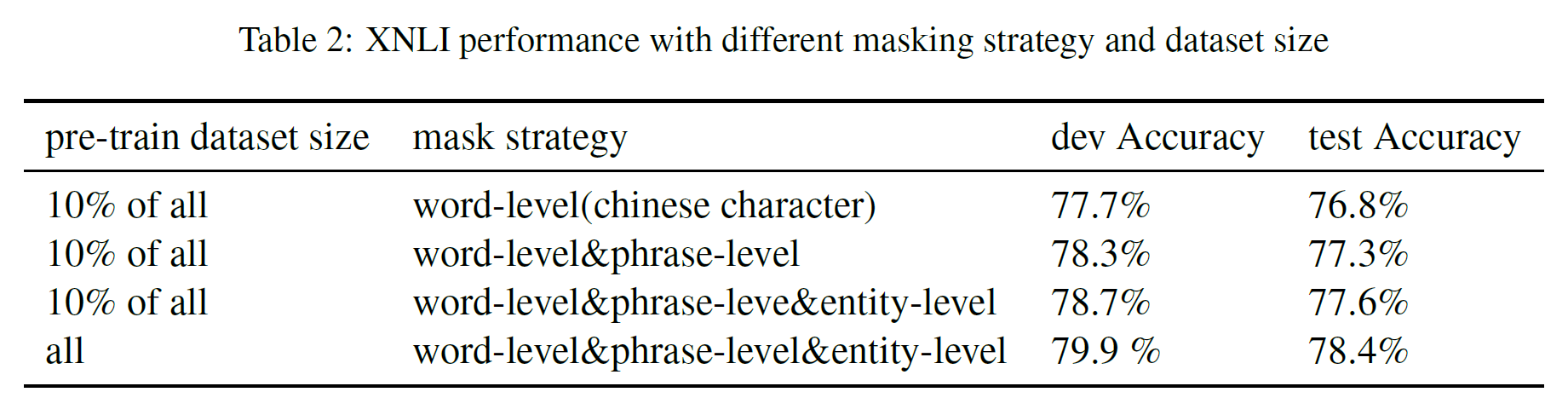
DLM을 학습에 포함시키는 경우 그렇지 않은 경우에 비해 0.7%/1.0%의 향상이 있다.

4.6. Cloze Test
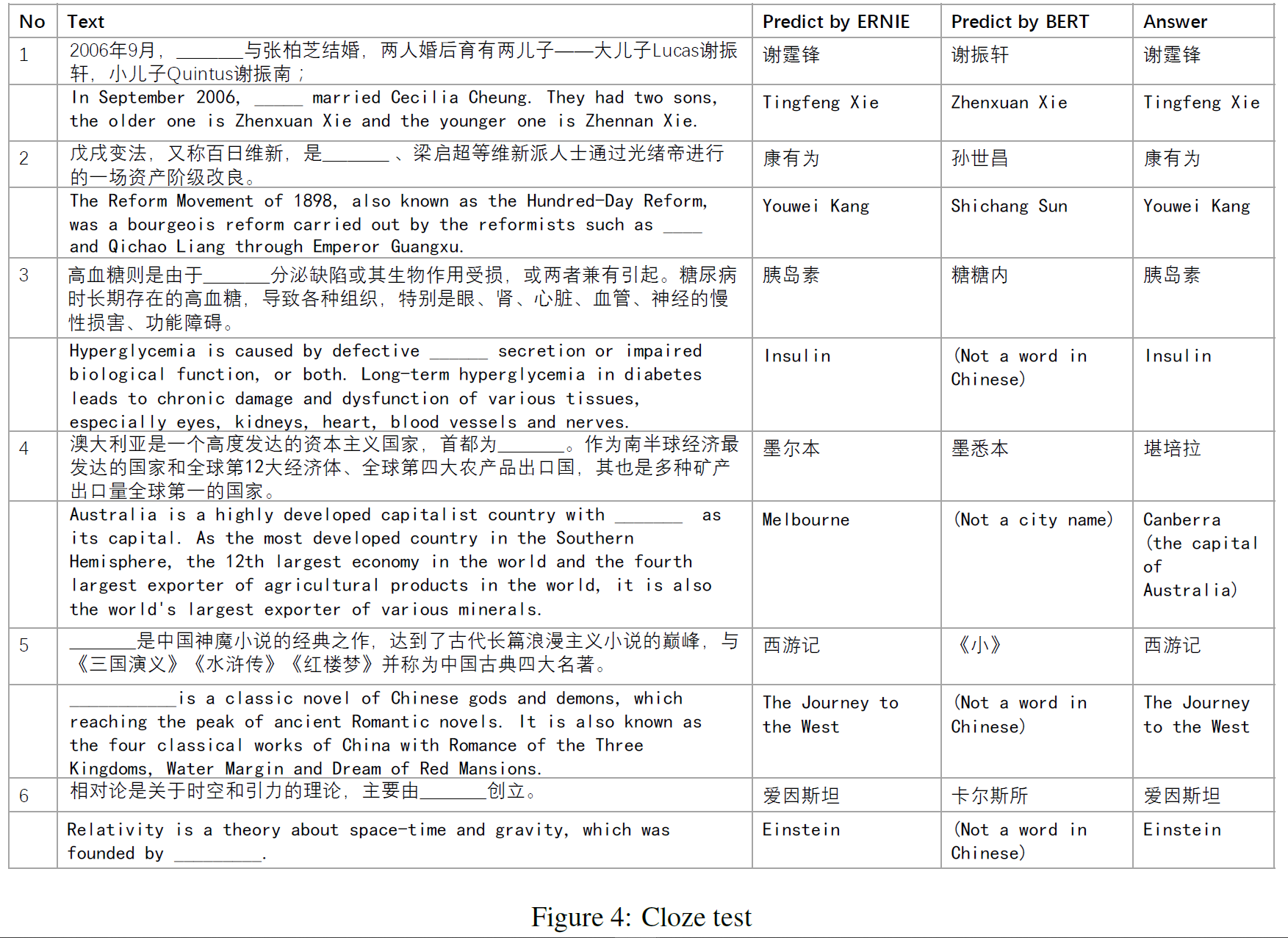
Name Entity를 단락에서 제거하고 모델이 이를 추론하는 Cloze test를 진행하였다. BERT는 문장에서 복사하려고 한 반면에 ERNIE는 기사에서 언급된 지식 관계를 기억하고 있다거나(Case 1), BERT는 entity 종류는 맞췄지만 제대로 채우는 데에는 실패했다거나(Case 2,5), 빈 칸을 여러 글자로 채웠지만 의미는 맞추지 못했다거나(Case 3, 4, 6) 하는 예시가 있다. 중국어라서 봐도 잘은 모르겠지만..(ERNIE는 Case 4에서 맞추지는 못했지만 semantic type은 맞췄다고 한다.)
결론(Conclusion)
지식 통합 전략으로 지식을 사전학습 언어모델에 넣는 새로운 방법을 제시했다. 5가지의 중국어 NLP task에서 BERT보다 우수한 성능을 보였으며 지식통합과 사전학습이 언어표현 학습에 모두 도움이 되는 것을 확인하였다.
이후에는 다른 종류의 지식을 의미적 표현모델에 넣는 방법(구문 parsing, 약한 지도학습 등)과 다른 언어에 적용할 방법을 연구한다고 한다.
참고문헌(References)
논문 참조!