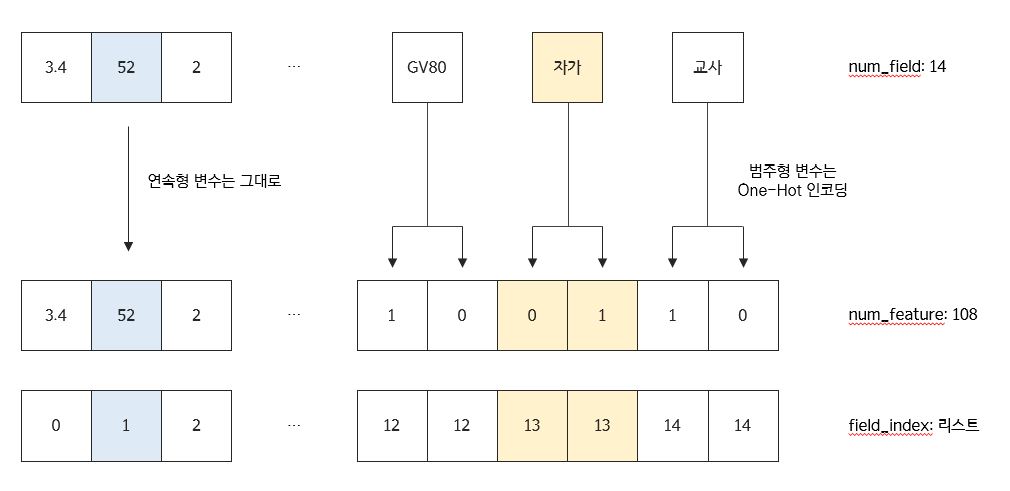
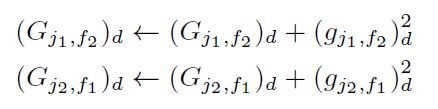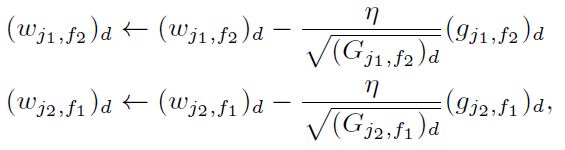저번 글에서는 Conflict에 대해서 알아보았다.
이번 글에서는, 전체 Git 명령어들의 사용법을 살펴본다.
명령어에 일반적으로 적용되는 규칙:
- 이 글에서
<blabla>와 같은 token은 여러분이 알아서 적절한 텍스트로 대체하면 된다.
- 각 명령에는 여러 종류의 옵션이 있다. ex)
git log의 경우 --oneline, -<number>, -p 등의 옵션이 있다.
- 각 옵션은 많은 경우 축약형이 존재한다. 일반형은
-가 2개 있으며, 축약형은 -가 1개이며 보통 첫 일반형의 첫 글자만 따온다. ex) --patch = -p. 축약형과 일반형은 효과가 같다.
- 각 옵션의 순서는 상관없다. 명령의 필수 인자와 옵션의 순서를 바꾸어도 상관없다.
- 각 명령에 대한 자세한 설명은
git help <command-name>으로 확인할 수 있다.
- ticket branch는 parent branch로부터 생성되어, 어떤 특정 기능을 추가하고자 만든 실험적 branch라 생각하면 된다.
Working tree(작업트리) 생성
git init
빈 디렉토리나, 기존의 프로젝트를 git 저장소(=git repository)로 변환하고 싶다면 이 문단을 보면 된다.
일반적인 디렉토리(=git 저장소가 아닌 디렉토리)를 git working tree로 만드는 방법은 다음과 같다. 명령창(cmd / terminal)에서 다음을 입력한다.
git init
# 결과 예시
Initialized empty Git repository in blabla/sample_directory/.git/
그러면 해당 디렉토리에는 .git 이라는 이름의 숨김처리된 디렉토리가 생성된다. 이 디렉토리 안에 든 것은 수동으로 건드리지 않도록 한다.
참고) git init 명령만으로는 인터넷(=원격 저장소 = remote repository)에 그 어떤 연결도 되어 있지 않다. 여기를 참조한다.
git clone
인터넷에서 이미 만들어져 있는 작업트리를 본인의 컴퓨터(=로컬)로 가져오고 싶을 때에는 해당 git repository의 https://github.com/blabla.git 주소를 복사한 뒤 다음과 같은 명령어를 입력한다.
git clone <git-address>
# 명령어 예시
git clone https://github.com/greeksharifa/git_tutorial.git
# 결과 예시
Cloning into 'git_tutorial'...
remote: Enumerating objects: 56, done.
remote: Total 56 (delta 0), reused 0 (delta 0), pack-reused 56
Unpacking objects: 100% (56/56), done.
그러면 현재 폴더에 해당 프로젝트 이름의 하위 디렉토리가 생성된다. 이 하위 디렉토리에는 인터넷에 올라와 있는 모든 내용물을 그대로 가져온다(.git 디렉토리 포함).
단, 다른 branch의 내용물을 가져오지는 않는다. 다른 branch까지 가져오려면 추가 작업이 필요하다.
Git Repository 연결
이 과정은 git clone으로 원격저장소의 로컬 사본을 생성한 경우에는 필요 없다.
먼저 github 등에서 원격 저장소(remote repository)를 생성한다.
로컬 저장소를 원격저장소에 연결하는 방법은 다음과 같다.
git remote add <remote-name> <git address>
# 명령어 예시
git remote add origin https://github.com/greeksharifa/git_tutorial.git
<remote-name>은 원격 저장소에 대한 일종의 별명인데, 보통은 origin을 쓴다. 큰 프로젝트라면 여러 개를 쓸 수도 있다.
이것만으로는 완전히 연결되지는 않았다. upstream 연결을 지정하는 git push -u 명령을 사용해야 수정사항이 원격 저장소에 반영된다.
연결된 원격 저장소 확인
git remote --verbose
git remote -v
# 결과 예시
origin https://github.com/greeksharifa/git_tutorial.git (fetch)
origin https://github.com/greeksharifa/git_tutorial.git (push)
git remote -v의 결과는 <remote-name> <git-address> <fetch/push>로 이루어져 있다.
(fetch)는 새 작업을 다운로드하는 장소이고, (push)는 새 작업을 업로드하는 장소이다.
원격 저장소의 이름만을 보거나, 해당 이름의 자세한 정보를 알고 싶다면 git remote show나, git remote show <remote-name>을 입력한다.
git remote show
---
git remote show origin
# 결과 예시
origin
---
* remote origin
Fetch URL: https://github.com/greeksharifa/git_tutorial.git
Push URL: https://github.com/greeksharifa/git_tutorial.git
HEAD branch: main
Remote branches:
2nd-branch tracked
3rd-branch tracked
fourth-branch tracked
main tracked
Local branches configured for 'git pull':
2nd-branch merges with remote 2nd-branch
main merges with remote main
Local refs configured for 'git push':
2nd-branch pushes to 2nd-branch (up to date)
main pushes to main (local out of date)
해당 원격 저장소의 url은 무엇인지, 어떤 branch가 있는지, 로컬 branch는 원격 저장소의 어떤 branch와 연결되어 있는지 등을 확인할 수 있다.
원격 저장소 이름 변경
git remote rename <old-remote-name> <new-remote-name>
# 명령어 예시
git remote rename origin official
원격 연결 삭제
git remote remove <remote-name>
Git 설정하기
git 설정에는 계정 설정이나 변경 등이 있다. 그리고, 모든 git 설정은 2종류가 있다.
- 해당 컴퓨터의 모든 git 프로젝트에 적용되는 전역(global) 설정
- Linux에서는
~/.gitconfig 파일에 저장된다. 윈도우에서는 C:/Users/<user-name>/.gitconfig에 있다.
- 특정 프로젝트에만 적용되는 로컬(local) 설정
- 해당 프로젝트 root directory의
.git/config 파일에 저장된다.
컴퓨터를 공유해서 쓰는 것이 아니라면 보통은 global 설정을 주로 다루게 될 것이다.
설정된 값 보기:
git config --get <setting-name>
git config --get user.name
# 모든 설정값 보기
git config --list
설정값 설정하기: 보통 자신의 계정명과 계정을 설정하게 될 것이다. 최초 로그인 창이 뜰 수 있다.
git config --global <setting-name> <value>
# 명령어 예시
git config --global user.name 'greeksharifa'
git config --global user.name 'greeksharifa@gmail.com'
전역 설정이 아닌 해당 프로젝트에만 적용시키고 싶다면 --global 대신 --local을 사용한다.
git 기본 에디터 변경
git의 기본 에디터는 Vim인데, 이를 변경할 수 있다. bash 등이 있다.
# 명령어 예시
git config --global core.editor mate -w
git config --global core.editor subl -n -w
git config --global core.editor '"C:\Program Files\Vim\gvim.exe" --nofork'
더 자세한 설정들은 git help config를 입력해서 찾아보자.
인증 정보 저장: Credential
SSH protocol을 사용하여 원격 저장소에 접근할 때는 암호를 매번 입력하지 않아도 되지만 HTTP protocol을 사용한다면 매번 인증 정보를 입력해야 한다.
하지만 git에는 이런 인증 정보(credential)을 저장해 둘 수 있다.
인증 정보를 임시로(cache) 저장하려면 다음을 사용한다. 기본적으로 15분간 임시로 저장하며, timeout 시간을 설정해 줄 수도 있다. 아래는 1시간(3600초) 기준이다.
git config --global credential.helper cache
git config --global credential.helper 'cache --timeout=3600'
임시가 아니라 계속 저장해 두려면 cache 대신 store를 사용한다. 저장할 파일을 지정할 수도 있다.
git config --global credential.helper store
git config --global credential.helper 'store --file <file-path>'
Git 준비 영역(index)에 파일 추가
로컬 저장소의 수정사항이 반영되는 과정은 총 3단계를 거쳐 이루어진다.
git add 명령을 통해 준비 영역에 변경된 파일을 추가하는 과정(stage라 부른다)git commit 명령을 통해 여러 변경점을 하나의 commit으로 묶는 과정git push 명령을 통해 로컬 commit 내용을 원격 저장소에 올려 변경사항을 반영하는 과정
이 중 git add 명령은 첫 단계인, 준비 영역에 파일을 추가하는 것이다.
git add <filename1> [<filename2>, ...]
git add <directory-name>
git add *
git add --all
git add .
# 명령어 예시
git add third.py fourth.py
git add temp_dir/*
*은 와일드카드로 그냥 쓰면 변경점이 있는 모든 파일을 준비 영역에 추가한다(git add *). 특정 directory 뒤에 쓰면 해당 directory의 모든 파일을, *.py와 같이 쓰면 확장자가 .py인 모든 파일이 준비 영역에 올라가게 된다.
git add .을 현재 directory(.)의 모든 파일을 추가하는 명령으로 git add --all과 효과가 같다.
git add 명령을 실행하고 이미 준비 영역에 올라간 파일을 또 수정한 뒤 git status 명령을 실행하면 같은 파일이 Changes to be committed 분류와 Changes not staged for commit 분류에 동시에 들어가 있을 수 있다. 딱히 오류는 아니고 해당 파일을 다음 commit에 반영할 계획이면 한번 더 git add를 실행시켜주자.
한 파일 내 수정사항의 일부만 준비 영역에 추가
예를 들어 fourth.py를 다음과 같이 변경한다고 하자.
# 변경 전
print('hello')
print(1)
print('bye')
#변경 후
print('hello')
print('git')
print('bye')
print('20000')
이 중 print('bye'); print('20000')을 제외한 나머지 변경사항만을 준비 영역에 추가하고 싶다고 하자. 그러면 git add <filename> 명령에 다음과 같이 --patch 옵션을 붙인다.
git add --patch fourth.py
git add fourth.py -p
# 결과 예시
diff --git a/fourth.py b/fourth.py
index 13cc618..4c8cfb6 100644
--- a/fourth.py
+++ b/fourth.py
@@ -1,5 +1,5 @@
print('hello')
+print('git')
-print(1)
-
-print('bye')
\ No newline at end of file
+print('bye')
+print('20000')
\ No newline at end of file
stage this hunk [y,n,q,a,d,s,e,?]?
그러면 수정된 코드 덩이(hunk)마다 선택할지를 물어본다. 인접한 초록색(+) 덩이 또는 인접한 빨간색 덩이(-)가 하나의 코드 덩이가 된다.
각 옵션에 대한 설명은 다음과 같다. ?를 입력해도 도움말을 볼 수 있다.
| Option |
Description |
| y |
stage this hunk |
| n |
do not stage this hunk |
| q |
quit; do not stage this hunk or any of the remaining ones |
| a |
stage this hunk and all later hunks in the file |
| d |
do not stage this hunk or any of the later hunks in the file |
| s |
split the current hunk into smaller hunks |
| e |
manually edit the current hunk |
| ? |
print help |
여기서는 y, y, n을 차례로 입력하면 원하는 대로 추가/추가하지 않을 수 있다. (영어 원문을 보면 알 수 있듯이 (stage) = (준비 영역에 추가하다)와 같은 의미라고 보면 된다.)
-p 옵션으로는 인접한 추가/삭제 줄들이 전부 하나의 덩이로 묶이기 때문에, 이를 더 세부적으로 하고 싶다면 위 옵션에서 e를 선택하면 된다.
git add -p 명령을 통해 준비 영역에 파일의 일부 변경사항만 추가하고 나면 같은 파일이 Changes to be committed 분류와 Changes not staged for commit 분류에 동시에 들어가게 된다.
Commit하기
준비 영역에 올라간 파일들의 변경사항을 하나로 묶는 작업이라 보면 된다. Git에서는 이 commit(커밋)이 변경사항 적용의 기본 단위가 된다.
git commit [-m “message”] [–amend]
기본적으로, commit은 다음 명령어로 수행할 수 있다.
git commit
# 결과 예시:
All text in first line will be showed at --oneline
Maximum length is 50 characters.
Below, is for detailed message.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# On branch main
# Your branch is up to date with 'origin/main'.
#
# Changes to be committed:
# modified: .gitignore
# new file: third.py
#
~
~
git commit을 입력하면 vim 에디터가 열리면서 commit 메시지 편집을 할 수 있다. 방법은:
i를 누른다. insert의 약자이다.- 이후 메시지를 마음대로 수정할 수 있다. 이 때 규칙이 있는데,
- 첫 번째 줄은 log를 볼 때
--oneline 옵션에서 나타나는 대표 commit 메시지이다. 기본값으로, 50자 이상은 무시된다.
- 그 아래 줄에 쓴 텍스트는 해당 commit의 자세한 메시지를 포함한다.
- 맨 앞에
#이 있는 줄은 주석 처리되어 commit 메시지에 포함되지 않는다.
- 편집을 마쳤으면 다음을 순서대로 누른다.
ESC, :wq, Enter.
ESC는 vim 에디터에서 명령 모드로 들어가가, :wq는 저장 및 종료 모드 입력을 뜻한다. 잘 모르겠으면 그냥 따라하라.
- 맨 밑에 있는 물결 표시(
~)는 파일의 끝이라는 뜻이다. 빈 줄도 아니다.
commit의 자세한 메시지를 작성하기 귀찮다면(별로 좋은 습관은 아니다.), 간단한 메시지만 작성할 수 있다:
git commit -m "<message>"
# 명령 예시:
git commit -m "hotfix for typr error"
물론 이미 작성한 commit 메시지를 변경할 수 있다.
그러면 vim 에디터에서 수정할 수 있다.
원래는 git add 후 git commit을 하는 것이 일반적이지만, 모든 파일을 추가하면서 commit을 한다면 다음 단축 명령을 쓸 수 있다: -a 옵션을 붙인다.
git commit -a -m "<commit-message>"
수정사항을 원격저장소에 반영하기: git push
upstream 연결
git remote add 명령으로 원격저장소를 연결했으면 git push <git-address> 명령으로 로컬 저장소의 commit을 원격 저장소에 반영할 수 있다. 즉, 최종 반영이다.
git push <git-address>
git push https://github.com/greeksharifa/gitgitgit.git
# 결과 예시
Enumerating objects: 3, done.
Counting objects: 100% (3/3), done.
Writing objects: 100% (3/3), 200 bytes | 200.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/greeksharifa/gitgitgit.git
* [new branch] main -> main
그러나 매번 git address를 인자로 주어가며 변경사항을 저장하는 것은 매우 귀찮으니, 다음 명령을 통해 upstream 연결을 지정할 수 있다. 이는 git remote add 명령을 통해 원격 저장소의 이름을 이미 지정한 경우의 얘기이다.
혹시 로컬에서 git을 처음 쓰거나 다른 사람의 작업트리를 처음 쓰는 경우라면 github id/pw를 입력해야 할 수 있다.
git push --set-upstream <remote-name> <branch-name>
git push -u <remote-name> <branch-name>
# 명령어 예시
git push --set-upstream origin main
git push -u origin main
# 결과 예시
Everything up-to-date
Branch 'main' set up to track remote branch 'main' from 'origin'.
git push --set-upstream <remote-name> <branch-name> 명령은 <branch-name> branch의 upstream을 원격 저장소 <remote-name>로 지정하는 것으로, 앞으로 git push나 git pull 명령 등을 수행할 때 <branch name>과 <remote name>을 지정할 필요가 없도록 지정하는 역할을 한다. 즉, 앞으로는 commit을 원격 저장소에 반영할 때 git push만 입력하면 된다.
위와 같은 방법으로 지정하지 않은 branch나 원격 저장소에 push하고자 하는 경우, git push <remote-name> <branch-name>을 사용한다.
# 명령어 예시
git push origin ticket-branch
upstream 삭제
더 이상 필요 없는 원격 branch를 삭제할 때는 다음 명령을 사용한다.
git push --delete <remote-name> <remote-branch-name>
# 명령어 예시
git push --delete origin ticket-branch
git push -d origin ticket-branch
수정사항 반영하기
일반적으로 로컬 저장소의 commit을 원격 저장소에 반영하려면 다음 명령어를 입력한다.
git push <remote-name> <branch-name>
# 명령어 예시
git push origin main
위에서 --set-upstream 옵션을 사용해 업로드 branch와 장소를 지정했다면 git push만으로도 원격 저장소에 업로드가 가능하다.
위와 같은 방식으로는 기본적으로 로컬 branch의 이름(<branch-name>)과 원격 저장소에 저장될 branch의 이름이 같게 된다. 이를 다르게 지정해서 업로드하려면 다음과 같이 쓴다.
git push <remote-name> <local-branch-name>:<remote-branch-name>
# 명령어 예시
git push origin fourth:ticket
목적지인 원격 저장소의 해당 branch에 현재 로컬 저장소에는 없는 commit이 존재한다면 push가 진행되지 않는다. 원격 저장소의 변경점을 먼저 로컬에 복사해야 한다. 이는 git pull 명령을 써서 해결한다. 여기를 참고한다.
모든 branch의 수정사항 반영하기
git push --all <remote-name>
모든 branch의 수정사항을 반영하므로 <branch-name>은 지정할 필요 없다.
원격 저장소의 수정사항을 로컬로 가져오기: git pull
사실 git pull 명령은 git fetch와 git merge FETCH_HEAD를 합친 명령과 같다. 즉 원격 저장소의 수정사항을 먼저 확인한 다음, 로컬 저장소에는 없는 모든 commit들을 로컬로 가져오는 작업과 같다.
다음 상황을 가정하자:
A---B---C main on origin
/
D---E---F---G main
^
origin/main in your repository
현재 로컬 저장소의 main branch에는 A, B, C commit이 존재하지 않는다. 이를 로컬에 반영하려면 git pull을 입력한다. 어디서 받아올지 지정되어 있지 않다면 git pull <remote-name> <remote-branch-name>을 입력한다.
A---B---C origin/main
/ \
D---E---F---G---H main
수정사항 사이에 충돌이 없다면 자동으로 진행된다. 만약 충돌이 일어났다면, 먼저 충돌 사항을 해결한 다음 add/commit/push 과정을 거치면 된다.
Git Directory 상태 확인
git status
현재 git 저장소의 상태를 확인하고 싶다면 다음 명령어를 입력한다.
git status
# 결과 예시 1:
On branch main
Your branch is up to date with 'origin/main'.
nothing to commit, working tree clean
# 결과 예시 2:
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: first.py
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: .gitignore
deleted: second.py
Untracked files:
(use "git add <file>..." to include in what will be committed)
third.py
git status로는 로컬 git 저장소에 변경점이 생긴 파일을 크게 세 종류로 나누어 보여준다.
- Changes to be committed
- Tracking되는 파일이며, 준비 영역(stage)에 이름이 올라가 있는 파일들. 이 단계에 있는 파일들만이 commit 명령을 내릴 시 다음 commit에 포함된다. (그래서 to be commited이다)
- 마지막 commit 이후
git add 명령으로 준비 영역에 추가가 된 파일들.
- Changes not staged for commit:
- Tracking되는 파일이지만, 다음 commit을 위한 준비 영역에 이름이 올라가 있지 않은 파일들.
- 마지막 commit 이후
git add 명령의 대상이 된 적 없는 파일들.
- Untracked files:
- Tracking이 안 되는 파일들.
- 생성 이후 한 번도
git add 명령의 대상이 된 적 없는 파일들.
위와 같이 준비 영역 또는 tracked 목록에 올라왔는지가 1차 분류이고, 2차 분류는 해당 파일이 처음 생성되었는지(ex. third.py), 변경되었는지(modified), 삭제되었는지(deleted)로 나눈다.
수정된 파일을 보다 간략히 보려면 --short 옵션을 사용한다.
git status --short
git status -s
# 결과 예시
M .gitignore
A doonggoos.py
D first.py
M fourth.py
R third.py -> what.py
추가된 파일은 A, 수정된 파일은 M, 삭제된 파일은 D, 이름이 바뀐 파일은 R로 표시된다.
특정 파일/디렉토리 무시하기: .gitignore
프로젝트의 최상위 디렉토리에 .gitignore라는 이름을 갖는 파일을 생성한다. 윈도우에서는 copy con .gitignore라 입력한 뒤, 내용을 다 입력하고, Ctrl + C를 누르면 파일이 저장되면서 생성된다.
.gitignore 파일을 열었으면 안에 원하는 대로 파일명이나 디렉토리 이름 등을 입력한다. 그러면 앞으로 해당 프로젝트에서는 git add 명령으로 준비 영역에 해당 종류의 파일 등이 추가되지 않는다.
예시는 다음과 같다.
dum_file.py # `dum_file.py`라는 이름의 파일을 무시한다.
*.zip # 확장자가 `.zip`인 모든 파일을 무시한다.
data/ # data/ 디렉토리 전체를 무시한다.
!data/regression.csv # data/ 디렉토리는 무시되지만, data/regression.csv 파일은 무시되지 않는다.
# 이 경우는 data/ 이전 라인에 작성하면 적용되지 않는다.
**/*.json # 모든 디렉토리의 *.json 파일을 무시한다.
.gitignore 파일을 저장하고 나면 앞으로는 해당 파일들은 tracking되지 않는다. 즉, 준비 영역에 추가될 수 없다.
그러나 이미 tracking되고 있는 파일들은 영향을 받지 않는다. 따라서 git rm --cached 명령을 통해 tracking 목록에서 제거해야 한다.
전체 프로젝트에 .gitignore 적용하기
특정 프로젝트가 아닌 모든 프로젝트 전체에 적용하고 싶으면 다음 명령을 입력한다.
git config --global core.excludesfile <.gitignore-file-path>
# 명령 예시
git config --global core.excludesfile ~/.gitignore
git config --global core.excludesfile C:\.gitignore
그러면 해당 위치에 .gitignore 파일이 생성되고, 이는 모든 프로젝트에 적용된다. 일반적으로 git config --global 명령을 통해 설정하는 것은 특정 프로젝트가 아닌 해당 로컬에서 작업하는 모든 프로젝트에 영향을 준다. 여기를 참고하라.
History 검토
현재 존재하는 commit 검토: git log
저장소 commit 메시지의 모든 history를 역순으로 보여준다. 즉, 가장 마지막에 한 commit이 가장 먼저 보여진다.
git log
# 결과 예시
commit da446019230a010bf333db9d60529e30bfa3d4e3 (HEAD -> main, origin/main, origin/HEAD)
Merge: 4a521c5 2eae048
Author: greeksharifa <greeksharifa@gmail.com>
Date: Sun Aug 19 20:59:24 2018 +0900
Merge branch '3rd-branch'
commit 2eae048f725c1d843cad359d655c193d9fd632b4
Author: greeksharifa <greeksharifa@gmail.com>
Date: Sun Aug 19 20:29:48 2018 +0900
Unwanted commit from 2nd-branch
...
:
이때 commit의 수가 많으면 다음 명령을 기다리는 커서가 깜빡인다. 여기서 space bar를 누르면 다음 commit들을 계속해서 보여주고, 끝에 다다르면(저장소의 최초 commit에 도달하면) (END)가 표시된다.
끝에 도달했거나 이전 commit들을 더 볼 필요가 없다면, q를 누르면 log 보기를 중단한다(quit).
git log 옵션: –patch(-p), –max-count(-<number>), –oneline(–pretty=oneline), –graph
각 commit의 diff 결과(commit의 세부 변경사항, 변경된 파일의 변경된 부분들을 보여줌)를 보고 싶으면 다음을 입력한다.
git log --patch
# 결과 예시
commit 2eae048f725c1d843cad359d655c193d9fd632b4
Author: greeksharifa <greeksharifa@gmail.com>
Date: Sun Aug 19 20:29:48 2018 +0900
Unwanted commit from 2nd-branch
diff --git a/first.py b/first.py
index 2d61b9f..c73f054 100644
--- a/first.py
+++ b/first.py
@@ -9,3 +9,5 @@ print("This is the 1st sentence written in 3rd-branch.")
print('2nd')
print('test git add .')
+
+print("Unwanted sentence in 2nd-branch")
현재 branch가 아닌 다른 branch의 log를 보고 싶다면 <branch-name>을 추가 입력해 준다.
git log -p origin/main
# 결과 예시
commit 2eae048f725c1d843cad359d655c193d9fd632b4
Author: greeksharifa <greeksharifa@gmail.com>
Date: Sun Aug 19 20:29:48 2018 +0900
Unwanted commit from 2nd-branch
diff --git a/first.py b/first.py
index 2d61b9f..c73f054 100644
--- a/first.py
+++ b/first.py
@@ -9,3 +9,5 @@ print("This is the 1st sentence written in 3rd-branch.")
print('2nd')
print('test git add .')
+
+print("Unwanted sentence in 2nd-branch")
가장 최근의 commit들 3개만 보고 싶다면 다음과 같이 입력한다.
commit의 대표 메시지와 같은 핵심 내용만 보고자 한다면 다음과 같이 입력한다.
git log --oneline
# 결과 예시
da44601 (HEAD -> main, origin/main, origin/HEAD) Merge branch '3rd-branch'
2eae048 Unwanted commit from 2nd-branch
4a521c5 Desired commit from 2nd-branch
참고로, 다음과 같이 입력하면 commit의 고유 id의 전체가 출력된다.
git log --pretty=oneline
# 결과 예시
da446019230a010bf333db9d60529e30bfa3d4e3 (HEAD -> main, origin/main, origin/HEAD) Merge branch '3rd-branch'
2eae048f725c1d843cad359d655c193d9fd632b4 Unwanted commit from 2nd-branch
4a521c56a6c2e50ffa379a7f2737b5e90e9e6df3 Desired commit from 2nd-branch
옵션들은 중복이 가능하다.
--graph 옵션은 branch이 어디서 분기되고 합쳐졌는지와 같은 정보를 그래프로 보여준다. 분기된 지점이 없으면 일렬로 보인다.
git log --graph
# 결과 예시
* commit e8a20c960cfcd3f444d93b735f6bed7bd40ed7c5 (HEAD -> main, origin/main, origin/HEAD)
| Author: greeksharifa <greeksharifa@gmail.com>
| Date: Fri May 29 23:25:35 2020 +0900
|
| accelerate page load speed
|
* commit abbe725235f3144ef6df02c4b1b34cd1804ccd50
| Author: greeksharifa <greeksharifa@gmail.com>
| Date: Fri May 29 22:22:49 2020 +0900
|
| permalink test
|
...
--merges, --no-merges 옵션은 여기를 참고한다.
commit 검색하기
-S 옵션은 commit message나 수정사항 내에 주어진 문자열이 포함되어 있다면 해당 commit이 검색된다.
-G 옵션은 -S와 비슷하지만 정규식 표현으로 검색할 수 있다.
git log -S <string>
git log -G <regex-expression>
일부 commit만 확인하기
- 가장 최신 commit을 제외하고 log를 보려면
git log HEAD^를 사용한다.
- 가장 최신 2개의 commit을 제외하고 보려면
git log HEAD~2를 사용한다.
- 특정 범위의 commit을 확인하려면
git log <commit-1>..<commit-2>를 이용한다.
- 2개의 branch 사이의 차이를 확인하려면
git log <branch-name-1>..<branch-name-2>를 이용한다. 원격 저장소의 branch도 확인 가능하다.
commit과 commit의 변화 과정 전체를 검토: git reflog
git reflog
# 결과 예시:
87ab51e (HEAD -> main, tag: specific_tag) HEAD@{0}: commit: All text in first line will be showed at --onel
ine
da44601 (origin/main, origin/HEAD) HEAD@{1}: clone: from https://github.com/greeksharifa/git_tutorial.git
위와 같이 HEAD@{0}: commit과 HEAD@{1}: clone 이라는 변화를 볼 수 있다. git reflog는 commit 뿐 아니라 commit이 삭제되었는지, 재배치했는지, clone이나 rebase 같은 변화가 있었는지 등등 git에서 일어난 모든 변화를 기록한다.
특정 파일의 수정사항 history 보기: git blame
git blame <filename>의 형태로 사용한다. 파일 히스토리가 나타나는데,
해당 수정사항을 포함하는 commit id, 수정한 사람, 수정 일시, 줄 번호, 수정 내용을 볼 수 있다.
blame이라고 해서 누군가를 비난하는 것은 아니다.
git blame fourth.py
# 결과 예시
8506cef2 (greeksharifa 2020-05-27 21:42:19 +0900 1) print('hello')
dd65e051 (greeksharifa 2020-05-28 23:21:01 +0900 2) print('git')
8506cef2 (greeksharifa 2020-05-27 21:42:19 +0900 3)
dd65e051 (greeksharifa 2020-05-28 23:21:01 +0900 4) print('bye')
00000000 (Not Committed Yet 2020-05-30 14:26:53 +0900 5) print('20000')
00000000 (Not Committed Yet 2020-05-30 14:26:53 +0900 6)
00000000 (Not Committed Yet 2020-05-30 14:26:53 +0900 7) print('for test')
00000000 (Not Committed Yet 2020-05-30 14:26:53 +0900 8) print('for test 2')
00000000 (Not Committed Yet 2020-05-30 14:26:53 +0900 9) print('repeating test')
단, 수정사항을 묶어서 보여주지는 않는다.
다른 commit / branch와의 자세한 차이 확인: git diff
git diff 명령으로는 branch 간 차이를 확인하거나, commit 간 차이를 확인할 수 있다. 다음 예시들을 살펴보자.
git diff는 최신 commit과 현재 상태를 비교한다. 수정된 파일이 있으면 내용이 뜨고, 없으면 아무것도 출력되지 않는다.
git diff
# 결과 예시 1
(빈 줄)
# 결과 예시 2
diff --git a/fourth.py b/fourth.py
index 4c8cfb6..e69de29 100644
--- a/fourth.py
+++ b/fourth.py
@@ -1,5 +0,0 @@
-print('hello')
-print('git')
-
-print('bye')
-print('20000')
\ No newline at end of file
git diff <commit>은 해당 commit 이후 수정된 코드를 보여준다.
git diff <branch-name-1> <branch-name-2>는 두 branch 간 차이를 전부 보여준다. branch를 지정할 때 두 branch의 순서를 바꾸면 추가된 줄과 삭제된 줄이 뒤바뀌니 주의하자.
<branch-name-1>에서 <branch-name-2>로 이동할 때의 변화를 기준으로 +, -가 보여진다. 즉 <branch-name-1>에는 없고 <branch-name-2>에는 있는 코드라면 +로 표시된다.
git diff main 2nd-branch
# 결과 예시
diff --git a/.gitignore b/.gitignore
index 15c8c56..8d16a4b 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,3 +1,3 @@
-
+third.py
.idea/
*dummy*
diff --git a/first.py b/first.py
index baba21f..2d61b9f 100644
--- a/first.py
+++ b/first.py
@@ -1 +1,11 @@
-print("Hello, git!")
+print("Hello, git!") # instead of "Hello, World!"
...
<branch-name-2>를 생략할 수도 있다. 위의 결과와는 +, -가 다르다.
git diff 2nd-branch
# 결과 예시
diff --git a/.gitignore b/.gitignore
index 8d16a4b..15c8c56 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,3 +1,3 @@
-third.py
+
.idea/
*dummy*
diff --git a/first.py b/first.py
index 2d61b9f..baba21f 100644
--- a/first.py
+++ b/first.py
@@ -1,11 +1 @@
-print("Hello, git!") # instead of "Hello, World!"
-print("Hi, git!!")
...
diff의 결과를 보거나 수정하고자 할 때 본인이 쓰는 에디터가 아니라 git bash 내에서 수행하려면 difftool을 사용한다.
git difftool <branch-name-1>..<branch-name-2>
git difftool <commit-1>..<commit-2>
HEAD: branch의 tip
HEAD는 현 branch history의 가장 끝을 의미한다. 여기서 끝은 가장 최신 commit 쪽의 끝이다(시작점을 가리키지 않는다).
다른 의미로는 checkout된 commit, 또는 현재 작업중인 commit이다.
예를 들어, HEAD@{0}은 1번째 최신 commit(즉, 가장 최신 commit)을 의미한다. index는 많은 프로그래밍 언어가 그렇듯 0부터 시작한다. 비슷하게, HEAD@{1}은 2번째 최신 commit을 의미한다.
HEAD^는 HEAD의 직전, 즉 가장 최신 commit을 가리킨다.
범위를 나타낼 땐 ~를 사용한다. 예를 들어, HEAD~3은 가장 최신 commit(1번째)부터 3번째 commit까지를 가리킨다.
HEAD~2^는 HEAD^(가장 최신, 즉 1번째 commit)보다 2번 더 이전 commit까지 간 것이고, 범위(~)를 나타내므로 1~3번째 commit을 가리킨다. 헷갈리니까 3개의 commit을 다루고 싶으면 그냥 HEAD~3을 쓰자.
Tag 붙이기
태그는 특정한 commit을 찾아내기 위해 사용된다. 즐겨찾기와 같은 개념이기 때문에, 여러 commit에 동일한 태그를 붙이지 않도록 한다.
우선 태그를 붙이고 싶은 commit을 찾자.
# 명령어 예시 1
git log --oneline -3
# 결과 예시 1
87ab51e (HEAD -> main) All text in first line will be showed at --oneline
da44601 (origin/main, origin/HEAD) Merge branch '3rd-branch'
2eae048 Unwanted commit from 2nd-branch
# 명령어 예시 2
git log 87ab51e --max-count=1
git show 87ab51e
# 결과 예시 2
commit 87ab51eecef1a526cb504846ddcaed0459f685c8 (HEAD -> main)
Author: greeksharifa <greeksharifa@gmail.com>
Date: Thu May 28 14:49:13 2020 +0900
All text in first line will be showed at --oneline
Maximum length is 50 characters.
Below, is for detailed message.
git tag
이제 태그를 commit에 붙여보자.
git tag <tag-name> 87ab51e
# 명령어 예시
git tag specific_tag 87ab51e
지금까지 붙인 태그 목록을 보려면 다음 명령을 입력한다.
git tag
# 결과 예시
specific_tag
해당 태그가 추가된 commit을 보려면 여기를 참조한다.
특정 commit 보기
git show
commit id를 사용해서 특정 commit을 보고자 하면 다음과 같이 쓴다.
git log 87ab51e --max-count=1
git show 87ab51e
# 결과 예시
Author: greeksharifa <greeksharifa@gmail.com>
Date: Thu May 28 14:49:13 2020 +0900
All text in first line will be showed at --oneline
Maximum length is 50 characters.
Below, is for detailed message.
git show <tag-name>
git show <tag-name>
# 명령어 예시
git show specific_tag
# 결과 예시
commit 87ab51eecef1a526cb504846ddcaed0459f685c8 (HEAD -> main, tag: specific_tag)
Author: greeksharifa <greeksharifa@gmail.com>
Date: Thu May 28 14:49:13 2020 +0900
All text in first line will be showed at --oneline
Maximum length is 50 characters.
Below, is for detailed message.
diff --git a/.gitignore b/.gitignore
index 8d16a4b..6ec8ec8 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,3 +1,2 @@
-third.py
.idea/
*dummy*
diff --git a/third.py b/third.py
new file mode 100644
index 0000000..0360dad
--- /dev/null
+++ b/third.py
@@ -0,0 +1 @@
+print('hello 3!')
Git Branch
branch 목록 업데이트하기
git fetch --all
git fetch -a
특정 원격 저장소의 것만을 업데이트하려면 다음과 같이 한다.
branch 목록 보기
로컬 branch 목록을 보려면 다음을 입력한다.
git branch
git branch --list
git branch -l
# 결과 예시
* main
branch 목록을 보여주는 모든 명령에서, 현재 branch(작업 중인 branch)는 맨 앞에 asterisk(*)가 붙는다.
모든 branch 목록 보기:
git branch --all
git branch -a
# 결과 예시
* main
remotes/origin/2nd-branch
remotes/origin/3rd-branch
remotes/origin/HEAD -> origin/main
remotes/origin/main
remotes/가 붙은 것은 원격 branch라는 뜻이며, branch의 실제 이름에는 remotes/가 포함되지 않는다.
--verbose 옵션을 붙이면 최신 commit까지 출력해 준다.
git branch --all --verbose
# 결과 예시
2nd-branch 1be03c8 Remove files that were uploaded incorrectly
* main 94d511c [ahead 3] fourth ticket
remotes/origin/2nd-branch 1be03c8 Remove files that were uploaded incorrectly
remotes/origin/3rd-branch 90ce4f2 Merge branch '3rd-branch'
remotes/origin/HEAD -> origin/main
remotes/origin/fourth-branch 94d511c fourth tickek
remotes/origin/main da44601 Merge branch '3rd-branch'
main branch의 설명에 붙어 있는 [ahead 3]이라는 문구는 현재 로컬 저장소에는 3개의 commit이 있지만 아직 원격 저장소에 psuh되지 않았음을 의미한다.
원격 branch 목록만 보기:
git branch --remotes
git branch -r
# 결과 예시
origin/2nd-branch
origin/3rd-branch
origin/HEAD -> origin/main
origin/main
branch 이름 변경
먼저 현재 branch의 이름 변경하는 방법은 다음과 같다.
git checkout <old-branch-name>
git branch -m <new-branch-name>
지금 branch가 main(master)이라면 다른 branch의 이름을 바로 변경할 수 있다.
git branch -m <old-branch-name> <new-branch-name>
branch 이름 변경 시 로컬 저장소의 branch 이름도 변경
아래 예시는 master를 main으로 바꿨을 때의 코드이다.
git branch -m main main
git fetch origin
git branch -u origin/main main
git remote set-head origin -a
원격 branch 목록 업데이트
로컬 저장소와 원격 저장소는 실시간 동기화가 이루어지는 것이 아니기 때문에(일부 git 명령을 내릴 때에만 통신이 이루어짐), 원격 branch 목록은 자동으로 최신으로 유지되지 않는다. 목록을 새로 확인하려면 다음을 입력한다.
별다른 변경점이 없으면 아무 것도 표시되지 않는다.
branch 전환
branch를 전환하려면 저장되지 않은 수정사항이 없어야 한다.
수정사항을 다른 데다 임시로 저장하려면 stash를 참고한다.
단순히 branch 간 전환을 하고 싶으면 다음 명령어를 입력한다.
git checkout <branch-name>
# 명령어 예시
git checkout main
# 결과 예시
Switched to branch 'main'
M .gitignore
D second.py
Your branch is ahead of 'origin/main' by 1 commit.
(use "git push" to publish your local commits)
전환을 수행하면,
- 변경된 파일의 목록과
- 현재 로컬 브랜치가 연결되어 있는 원격 브랜치 사이에 얼마만큼의 commit 차이가 있는지
도 알려준다.
로컬에 새 branch를 생성하되, 그 내용을 원격 저장소에 있는 어떤 branch의 내용으로 하고자 하면 다음 명령을 사용한다.
git checkout --track -b <local-branch-name> <remote-branch-name>
# 명령어 예시
git checkout --track -b 2nd-branch origin/2nd-branch
# 결과 예시
Switched to a new branch '2nd-branch'
M .gitignore
D second.py
Branch '2nd-branch' set up to track remote branch '2nd-branch' from 'origin'.
출력에서는 2nd-branch라는 이름의 새 branch로 전환하였고, 파일의 현재 수정 사항을 간략히 보여주며, 로컬 branch 2nd-branch가 origin의 원격 branch 2nd-branch를 추적하게 되었음을 알려준다.
즉 원격 branch의 로컬 사본이 생성되었음을 알 수 있다.
새 branch 생성
git branch <new-branch-name>
# 명령어 예시
git branch fourth-branch
위 명령은 branch를 생성만 한다. 생성한 브랜치에서 작업을 시작하려면 checkout 과정을 거쳐야 한다.
branch 생성과 같이 checkout하기
git checkout -b <new-branch-name> <parent-branch-name>
# 명령어 예시
git checkout -b fourth-branch main
# 결과 예시
Switched to a new branch 'fourth-branch'
새로운 branch는 생성 시점에서 parent branch와 같은 history(commit 기록들)을 갖는다.
원격 저장소의 branch를 로컬 저장소에 복사하며 checkout하기
git checkout -b <local-branch-name> --track <remote-branch-name>
# 명령어 예시
git branch -a
git checkout -b 3rd-branch --track remotes/origin/3rd-branch
git branch
# 결과 예시
2nd-branch
* main
remotes/origin/2nd-branch
remotes/origin/3rd-branch
remotes/origin/HEAD -> origin/main
remotes/origin/fourth-branch
remotes/origin/main
Switched to a new branch '3rd-branch'
Branch '3rd-branch' set up to track remote branch '3rd-branch' from 'origin'.
2nd-branch
* 3rd-branch
main
branch 병합: git merge
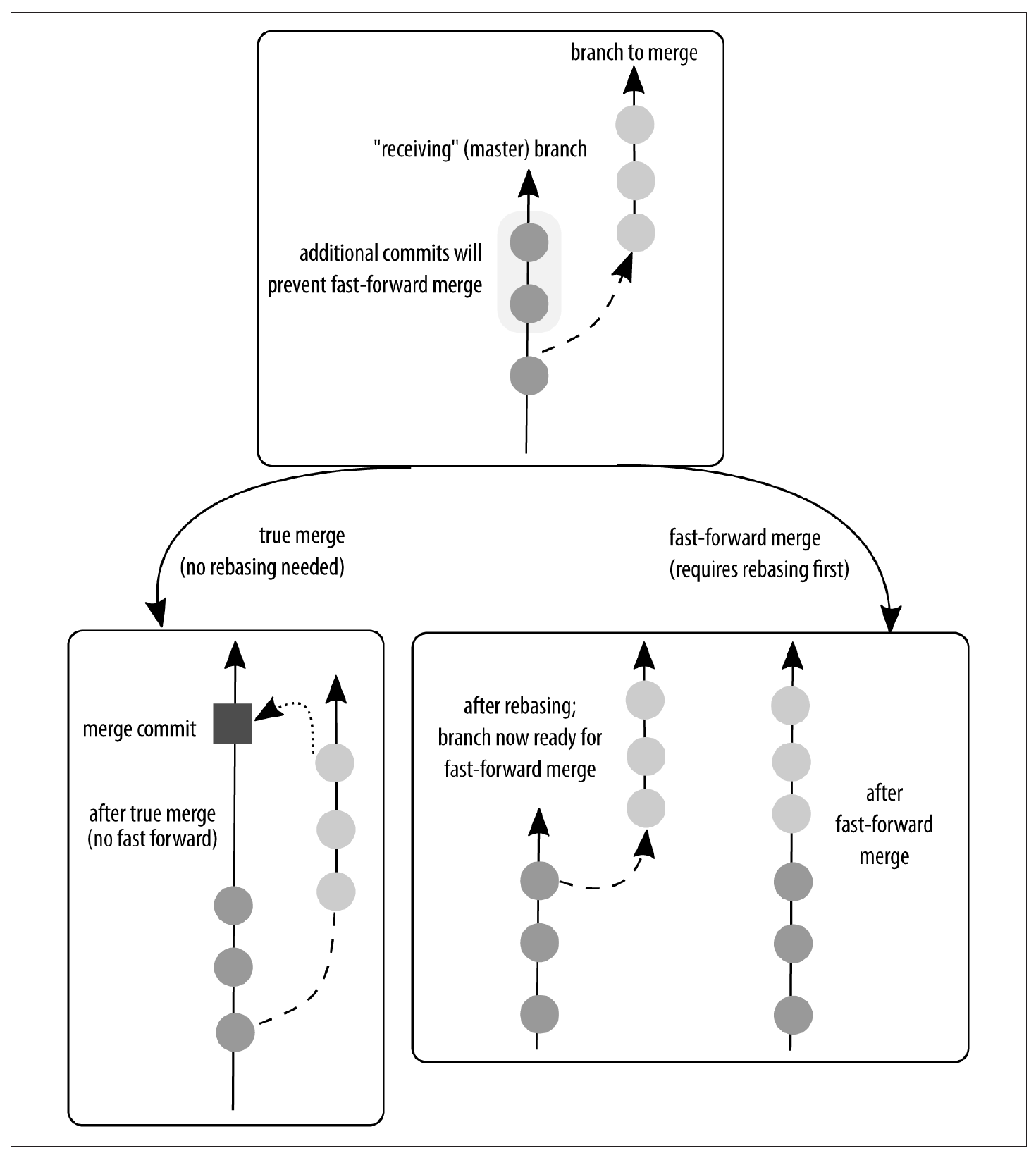
git merge <branch-name>를 사용한다. <branch-name> branch의 수정 사항들(commit)을 현재 branch로 가져와 병합한다. 이 방식은 완전 병합 방식이다.
git merge <branch-name>
# 명령어 예시
git merge ticket-branch
# 결과 예시
Updating 96c99dc..94d511c
Fast-forward
.gitignore | 2 +-
fourth.py | 5 +++++
second.py | 9 ---------
third.py | 0
4 files changed, 6 insertions(+), 10 deletions(-)
create mode 100644 fourth.py
delete mode 100644 second.py
create mode 100644 third.py
이와 같은 방법을 history fast-forward라 한다(히스토리 빨리 감기).
병합할 때 ticket branch의 모든 commit들을 하나의 commit으로 합쳐서 parent branch에 병합하고자 할 때는 --squash 옵션을 사용한다.
# 현재 branch가 parent branch일 때
git merge ticket-branch --squash
--squash 옵션은 애초에 branch를 분리하지 말았어야 할 상황에서 쓰면 된다. 즉, 병합 후 parent branch 입장에서는 그냥 하나의 commit이 반영된 것과 같은 효과를 갖는다.
위와 같이 처리했을 때는 ticket branch가 더 이상 필요 없으니 삭제하도록 하자.
병합 시 현 branch의 작업만을 최우선으로 남겨둔다면 다음 옵션을 사용한다.
git merge -X ours <branch-name>
반대로 가져오고자 하는 branch의 작업을 최우선으로 남긴다면 다음을 쓴다.
git merge -X theirs <branch-name>
branch 삭제
git branch --delete <branch-name>
git branch -d <branch-name>
# 명령어 예시
git branch --delete ticket-branch
# 결과 예시
Deleted branch fourth-branch (was 94d511c).
branch 삭제는 해당 branch의 수정사항들이 다른 branch에 병합되어서, 더 이상 필요없음이 확실할 때에만 문제없이 실행된다.
아직 수정사항이 남아 있음에도 그냥 해당 branch 자체를 폐기처분하고 싶으면 --delete 대신 -D 옵션을 사용한다.
이미 원격 저장소에 올라간 branch를 삭제하려면 여기를 참조한다.
작업 취소하기
먼저 가능한 작업 취소 명령들을 살펴보자.
| 원하는 것 |
명령어 |
| 특정 파일의 수정사항 되돌리기 |
git checkout -- <filename> |
| 모든 수정사항을 되돌리기 |
git reset --hard |
| 준비 영역의 모든 수정사항을 삭제 |
git reset --hard <commit> |
| 여러 commit 통합 |
git reset <commit> |
| 이전 commit들을 수정 또는 통합, 혹은 분리 |
git rebase --interactive <commit> |
| untracked 파일을 포함해 모든 수정사항을 되돌리기 |
git clean -fd |
| 이전 commit을 삭제하되 history는 그대로 두기 |
git revert <commit> |
아래는 Git for Teams라는 책에서 가져온 flowchart이다. 뭔가 잘못되었을 때 사용해보도록 하자.
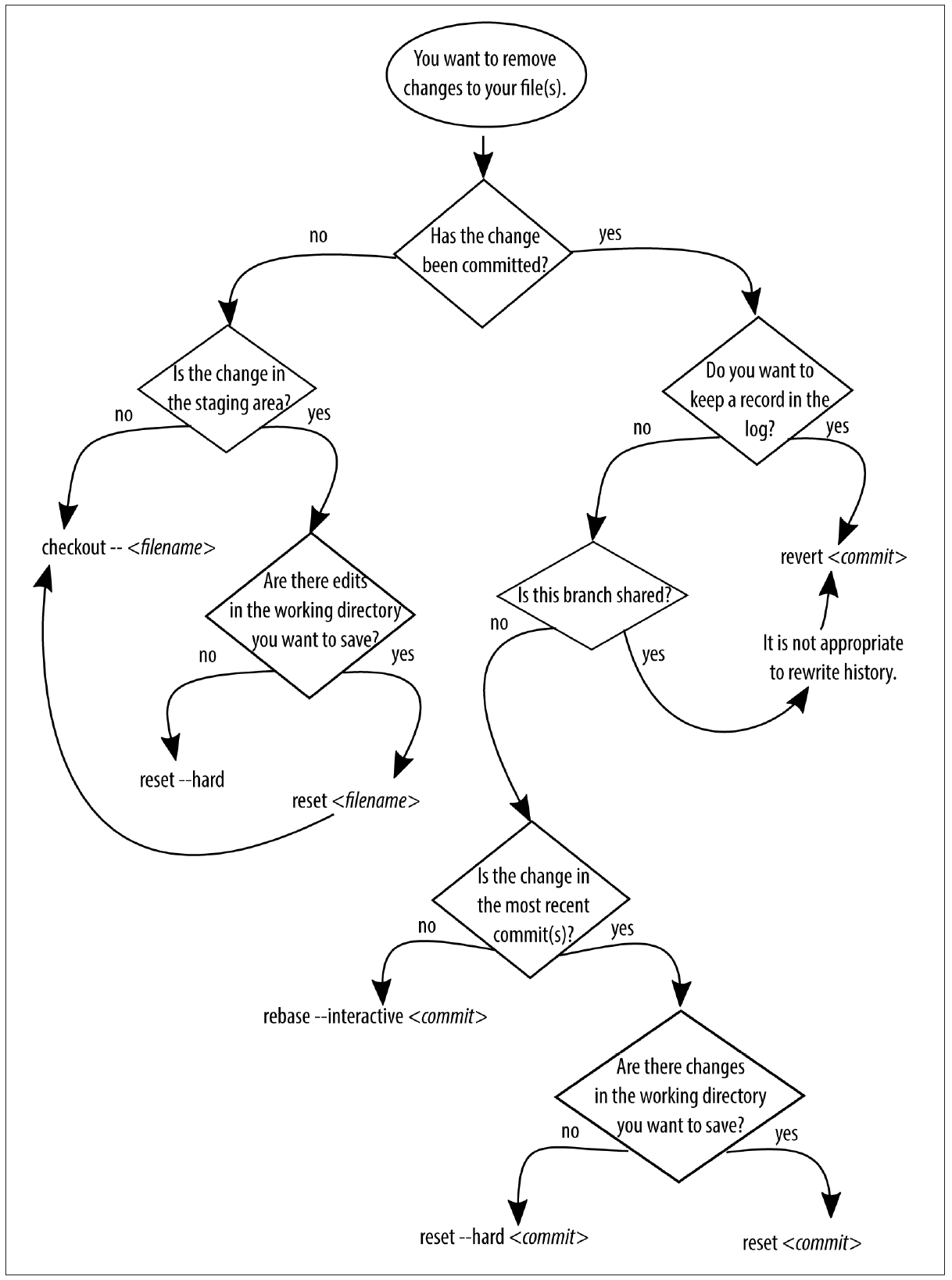
여러 명이 협업하는 프로젝트에서 이미 원격 저장소에 잘못된 수정사항이 올라갔을 때, 이를 강제로 되돌리는 것은 금물이다. ‘잘못된 수정사항을 삭제하는’ 새로운 commit을 만들어 반영시키는 쪽이 훨씬 낫다.
물론 branch를 잘 만들고, pull request 시스템을 적극 활용해서 그러한 일이 일어나지 않도록 하는 것이 최선이다.
혹시나 그런 일이 발생했다면, revert를 사용하라. 다른 명령들은 아직 원격 저장소에 push하지 않았을 때 쓰는 명령들이다.
특정 파일의 수정사항 되돌리기: checkout, reset
특정 파일을 지워 버렸거나 수정을 잘못했다고 하자. 이 때에는 다음 전제조건이 있다.
수정사항을 commit하지 않았을 때
commit하지 않았다면, 다음 두 가지 경우가 있다. git status를 입력하면 친절히 알려준다.
git status
#결과 예시
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: third.py
no changes added to commit (use "git add" and/or "git commit -a")
마지막 줄에서 아직 commit된 것이 없다는 것을 확인해야 한다.
- 수정사항을 준비 영역에 올리지 않았을 때(
git add를 안 수행했을 때)
git checkout -- <filename>- 그러면 파일이 원래대로 복구된다.
- 수정사항을 stage했을 때(
git add를 수행했을 때)
- 그러면 위 결과 예시처럼
no changes added to commit ...이라는 메시지가 없다. 다음 두 명령을 입력한다.
git reset HEAD <filename>git checkout -- <filename>
을 입력한다.- 그러면 가장 최신(HEAD) commit에 저장되어 있는 파일의 원래 상태가 복구된다. commit하지 않았을 때 사용할 수 있는 이유가 이것이다.
- 아니면 명령어 두 개를 합친 다음 명령을 써도 된다.
git reset --hard HEAD -- <filename>
git reset <filename>은 git add <filename>의 역방향이라고 보면 된다. 물론 git reset <commit> <filename>은 파일을 여러 commit 이전으로 되돌릴 수 있기 때문에 상황에 따라서는 다른 작업일 수 있다.
비슷하게, git reset -p <filename>은 git add -p <filename>의 역 작업이다.
git reset의 옵션은 여러 개가 있다.
git reset [-q | -p] [--] <paths>: <paths>는 <filename>을 포함한다. 즉, filename 뿐만 아니라 디렉토리 등도 가능하다. 이 명령의 효과는 git add [-p]의 역 작업이다.git reset [--soft | --mixed [-N] | --hard | --merge | --keep] -[q] [<commit>]
--hard: <commit> 이후 발생한 모든 수정사항과 준비 영역의 수정사항이 폐기된다.--soft는 파일의 수정사항이 남아 있으며, 수정된 파일들이 모두 Changes to be committed 상태가 된다.--mixed는 파일의 수정사항은 남아 있으나 준비 영역의 수정사항은 폐기된다. mixed가 기본 옵션이다.--merge는 준비 영역의 수정사항은 폐기하고 <commit>과 HEAD 사이 수정된 파일들을 업데이트하지만 수정된 파일들은 stage되지 않는다.--keep은 --merge와 비슷하나 <commit>때와 HEAD 때가 다른 파일에 일부 변화가 있는 경우에는 reset 과정이 중단된다.
모든 파일의 수정사항 되돌리기:
branch 병합 취소하기
먼저 다음 flowchart를 살펴보자.
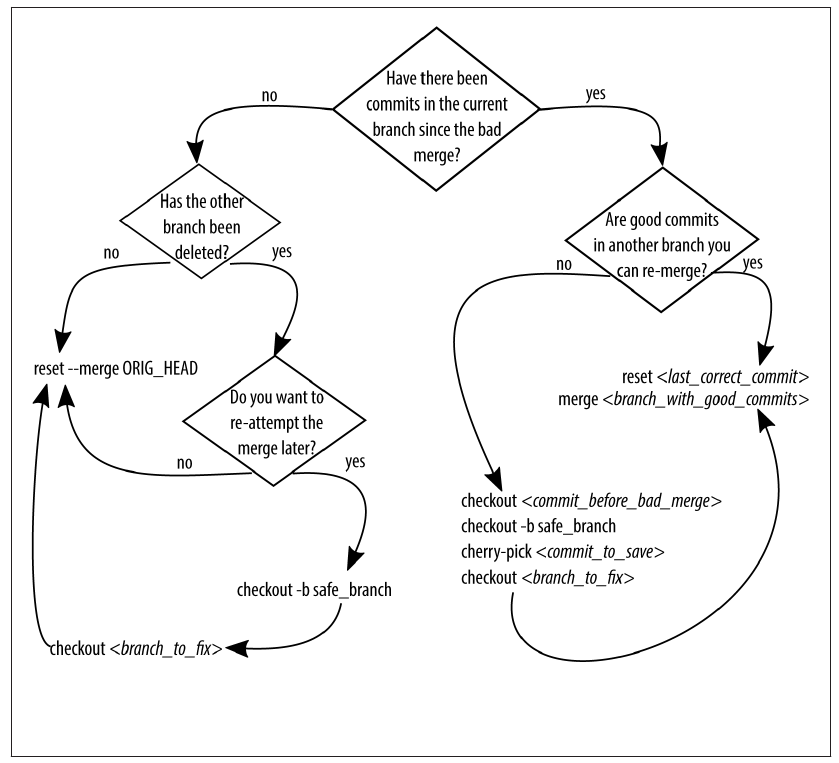
바로 직전에 한 병합(merge)를 취소하려면 다음 명령어를 입력한다.
git reset --merge ORIG_HEAD
병합 후 추가한 commit이 있으면 해당 지점의 commit을 지정해야 한다.
어디인지 잘 모르겠으면 reflog를 사용해보자.
이미 원격 저장소에 공유된 branch 병합을 취소하는 방법은 여기를 참고한다.
커밋 합치기: git reset <commit>
기본적으로, git reset은 branch tip을 <commit>으로 옮기는 과정이다. 그래서, git reset <option> HEAD는 마지막 commit의 상태로 준비 영역 또는 파일 내용을 되돌리는(reset) 작업이다.
또한, 바로 위에서 살펴봤듯이, git reset은 기본 옵션이 --mixed이며, 이는 옵션을 따로 명시하지 않으면 git reset은 파일의 수정사항은 그대로 둔 채 준비 영역에는 추가된 수정사항이 없는 상태로 만든다.
그래서 특정 이전 commit을 지정하여 git reset <commit>을 수행하면 해당 <commit>부터 HEAD까지의 파일의 수정사항은 작업트리(=프로젝트 디렉토리 전체)에 그대로 남아 있지만, 준비 영역에는 아무런 변화도 기록되어 있지 않다.
먼저 어떤 커밋들을 합칠지 git log --oneline으로 확인해보자.
# 결과 예시
c8c731b (HEAD -> main, origin/main, origin/HEAD) doong commit
87ab51e (tag: specific_tag) All text in first line will be showed at --oneline
da44601 Merge branch '3rd-branch'
2eae048 Unwanted commit from 2nd-branch
4a521c5 Desired commit from 2nd-branch
이제 가장 최신 2개의 commit을 합치고 싶으면, 현재 branch의 HEAD를 c8c731b에서 da44601로 옮기면 된다.
그러면 직전 2개의 commit의 수정사항이 파일에는 그대로 남아 있지만, 준비 영역이나 commit 내역에선 사라진다. 이제 stage, commit, push 3단계를 수행하면 최종적으로 commit 2개가 1개로 합쳐진다.
<commit> id를 지정하는 것이 헷갈린다면 git reset HEAD~2로 실행하자. 이는 여기에서 볼 수 있듯이 범위로 2개의 commit을 포함한다.
git rebase
rebase는 일반적으로 history rearrange의 역할을 한다. 즉, 여러 commit들의 순서를 재배치하는 작업이라 할 수 있다. 혹은 parent branch의 수정사항을 가져오면서 자신의 commit은 그 이후에 추가된 것처럼 하는, 마치 분기된 시점을 뒤로 미룬 듯한 작업을 수행할 수도 있다.
그러나 rebase와 같은 기존 작업을 취소 또는 변경하는 명령은 일반적으로 충돌(conflict)이 일어나는 경우가 많다. 충돌이 발생하면 git은 작업을 일시 중지하고 사용자에게 충돌을 처리하라고 한다.
main branch의 commit을 topic branch로 가져오기
다음과 같은 상황을 가정하자. 각 알파벳은 하나의 commit이며, 각 이름은 branch의 이름을 나타낸다.
아래 각 예시는 git help에 나오는 도움말을 이용하였다.
A---B---C topic
/
D---E---F---G main
commit F, G를 topic branch에 반영(포함)시키려 한다면,
A'--B'--C' topic
/
D---E---F---G main
commit A’와 A는 프로젝트에 동일한 수정사항을 적용시키지만, 16진수로 된 commit의 고유 id(da44601 같은)는 다르다. 즉, 엄밀히는 다른 commit이다.
commit을 재배열하는 명령어는 다음과 같다. 현재 branch는 topic이라 가정한다.
git rebase main
git rebase main topic
commit A, B, C가 F, G와 코드 상으로 동일한 파일 또는 다른 일부분을 수정하지 않았다면, 이 rebase 작업은 자동으로 완료된다.
만약 topic branch에 이미 main branch로부터 가져온 commit이 일부 존재하면, 이 commit들은 새로 배치되지 않는다.
A---B---C topic
/
D---E---A'---F main
에서
B'---C' topic
/
D---E---A'---F main
로 바뀐다.
branch의 parent 바꾸기: –onto
topic을 next가 아닌 main에서 분기된 것처럼 바꾸고자 한다. 즉,
o---A---B---o---C main
\
D---o---o---o---E next
\
o---o---o topic
이걸 아래와 같이 바꿔보자.
o---A---B---o---C main
| \
| o'--o'--o' topic
\
D---o---o---o---E next
topic branch의 history에는 이제 commit D~E 대신 commit A~B가 포함되어 있다.
이는 다음과 같은 명령어로 수행할 수 있다:
git rebase --onto main next topic
다른 예시는:
H---I---J topicB
/
E---F---G topicA
/
A---B---C---D main
git rebase --onto main topicA topicB
H'--I'--J' topicB
/
| E---F---G topicA
|/
A---B---C---D main
특정 범위의 commit들 제거하기
E---F---G---H---I---J topic
topic branch의 5번째 최신 commit부터, 3번째 최신 commit 직전까지 commit을 topic branch에서 폐기하고 싶다고 하자. 그러면 다음 명령어로 사용 가능하다.
git rebase --onto <branch-name>~<start-number> <branch-name>~<end-number> <branch-name>
# 명령어 예시
git rebase --onto topic~5 topic~3 topic
E---H'---I'---J' topic
여기서 5(번째 최신 commit, F)은 삭제되고, 3(번째 최신 commit, H)은 삭제되지 않음을 주의하라. rebase가 되기 때문에 commit의 고유 id는 바뀐다(H -> H’)
충돌 시 해결법
일반적으로 rebase에서 수정하는 2개 이상의 commit이 같은 파일을 수정하면 충돌이 발생한다.
보통은 다음 과정을 거치면 해결된다.
- 충돌이 일어난 파일에 적절한 조취를 취한다. 파일을 남기거나/삭제하거나, 또는 파일 일부분에서 남길 부분을 찾는다. 코드 중 다음과 비슷해 보이는 부분이 있을 것이다. 적절히 지워서 해결하자.
ㅤ<<<<<<<< HEAD
ㅤ<current-code>
ㅤ========
ㅤ<incoming-code>
ㅤ>>>>>>>> da446019230a010bf333db9d60529e30bfa3d4e3
git add <conflict-resolved-filename>git rebase --continue
그냥 다 모르겠고(?) rebase 작업을 취소하고자 하면 다음을 입력한다.
rebase로 commit 합치거나 수정하기
다음과 같은 history가 있다고 하자.
c3eace0 (HEAD -> main, origin/main, origin/HEAD) git checkout, reset, rebase
f6c56ef what igt
bd80626 github hem
b7801a2 github overall
608a518 highlighter theme change
여러 개의 commit들을 합치거나, commit message를 수정하거나 하는 작업은 모두 rebase로 가능하다.
실행하면, vim 에디터가 열릴 것이다(ubuntu의 경우 nano일 수 있다). vim을 쓰는 방법은 여기를 참고한다.
rebase하는 부분에서는 다른 git command들과는 달리 수정할 commit 중 가장 오래된 commit이 가장 위에 온다.
git rebase --interactive <commit>
git rebase -i <commit>
# 명령 예시
git rebase -interactive 608a518
git rebase -i HEAD~4
# 결과 예시
pick c3eace0 (HEAD -> main, origin/main, origin/HEAD) git checkout, reset, rebase
pick f6c56ef what igt
pick bd80626 github hem
pick b7801a2 github overall
# Rebase 608a518..c3eace0 onto 608a518
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
설명을 잘 살펴보면 다음을 알 수 있다:
pick = p는 수정 사항과 commit을 그대로 둔다. 각 commit의 맨 앞에는 기본적으로 pick으로 설정되어 있다. 이 상태에서 아무 것도 안 하고 나간다면 이번 rebase는 아무 효과도 없다.reword = r은 pick과 거의 같지만 commit message를 수정할 수 있다. commit message를 수정하고 앞의 pick을 reword나 r로 바꾸면 commit의 메시지를 수정할 수 있다. 가장 최신의 commit에 r을 붙였다면 git commit --amend와 효과가 같다.edit = e는 해당 commit을 수정할 수 있다. reset 등의 작업이 가능하다.squash = s는 해당 commit이 바로 이전 commit에 흡수되며, commit message 또한 합쳐져서 하나로 된다. 합친 메시지들이 존재하는 에디터가 다시 열린다.fixup = f는 squash와 비슷하지만, 해당 commit의 message는 삭제된다.exec = x는 commit들 아래 줄에 명령어를 추가하여 실행하게 할 수 있다.
수정한 예시는 다음과 같다. 약어를 써도 되고 안 써도 된다.
pick c3eace0 (HEAD -> main, origin/main, origin/HEAD) git checkout, reset, rebase
f f6c56ef what igt
f bd80626 github hem
fixup b7801a2 github overall
...(아래 주석은 지워도 되고 안 지워도 된다. 어차피 commit에서는 무시되는 도움말이다)
하나의 commit을 2개로 분리하기
가장 최신 commit이라면 git reset HEAD~1을 사용하여 직전 commit 상태로 되돌린 뒤 stage-commit을 2번 수행하면 되고, 그 이전 commit이라면 rebase에서 해당 commit을 edit으로 두고 같은 과정을 반복하면 된다.
# 명령어 예시
git rebase HEAD~4
# pick -> edit
git add -p <filename>
git commit -m <1st-commit-message>
git add -p <filename1> <filename2>
git commit -m <2nd-commit-message>
git rebase --continue
commit을 되돌리는 commit: git revert
예를 들어, 4a521c5이라는 commit이 코드 3줄을 수정하고, 2줄을 제거하는 commit이라고 하자. 나중에, 이 commit이 완전히 잘못된 내용임을 알았으나, 이미 원격 저장소에 push되었다고 하자. 이럴 때 해당 commit을 취소하는 작업을 git revert로 수행할 수 있다.
아니, 정확히는 commit을 되돌리는 역할을 하는 commit을 추가하는 commit을 새로 생성할 수 있다.
git revert <commit>
# 명령어 예시
git revert 4a521c5
# 결과 예시
[main 4a521c5] Revert "specific_commit_description"
공유된 branch 병합 취소하기
먼저 어디서 병합이 일어났는지를 살펴본다. git log --merges를 쓰면 병합 commit만을 볼 수 있다. 반대로 --no-merges는 병합 commit은 제외하고 log를 보여준다.
git log --merges
# 결과 예시
commit da446019230a010bf333db9d60529e30bfa3d4e3 (origin/main, origin/HEAD)
Merge: 4a521c5 2eae048
Author: greeksharifa <greeksharifa@gmail.com>
Date: Sun Aug 19 20:59:24 2018 +0900
Merge branch '3rd-branch'
commit 90ce4f2ec8b5cd26af51e03401fb4541abfffbc2 (tag: v0.5, origin/3rd-branch)
Merge: e934e3e 317200f
Author: greeksharifa <greeksharifa.gmail.com>
Date: Sun Aug 12 15:42:06 2018 +0900
Merge branch '3rd-branch'
아니면 git log --graph나 git reflog를 활용한다.
이제 다음 그림을 참고하자.
완전 병합인 경우 다음 명령을 사용한다.
git revert --mainline <branch-number> <commit>
# 명령어 예시
git revert --maineline 1 4a521c5
여기서 <branch-number>는 남길 branch의 번호이다. git log --graph에서 보여지는 선들 중에서 가장 왼쪽부터 1번이며, 보통은 1번을 남기게 된다.
병합 commit이 따로 없다면 잘못된 commit들을 개별적으로 처리해야 한다.
특정 commit을 포함하는 모든 branch의 목록을 보자.
git branch --contains <commit>
취소할 commit들이 인접해 있다면 다음 명령으로 하나의 취소 commit을 생성할 수 있다.
git revert --no-commit <last commit to keep>..<newest commit to reject>
# 결과 예시
git revert --no-commit 4a521c5..2eae048
변경 사항을 검토하고 취소 과정을 끝내자.
인접해 있지 않다면 각 commit을 하나씩 취소 작업을 해야 한다. 심심한 위로의 말을 전한다.
git revert <commit-1>
git revert <commit-2>
...
history 완전 삭제하기: 완전범죄?
혹시나 비밀번호 같은 걸 원격 저장소에 올려버렸다면, 다른 팀원들이 봤든 안 봤든 최대한 흔적도 없이 날려버려야 한다. 이 때는 다음 명령들을 실행한다. 삭제할 파일이 password.crypt라고 하자.
git filter-branch --index-filter 'git rm --cached --ignore-unmatch password.crypt' HEAD
git reflog expire --expire=now --all
git gc --prune=now
git push origin --force --all --tags
각각 특정 파일을 저장소에서 완전히 삭제하고, history에서 없애고, 모든 commit되지 않은 수정사항을 작업트리에서 삭제하는 명령이다.
다른 팀원들에게는 rebase를 진행시키거나 아예 로컬 저장소를 밀어버린 다음 새로 clone해서 받으라고 말한다.
git pull --rebase=preserve
수정사항 임시 저장하기: git stash
지금 당장 branch를 전환해서 다른 branch의 내용을 봐야 하는데 commit할 만큼은 안 되는 수정사항이 작업트리에 남아 있을 때가 있다. 그럴 때는 잠시 넣어 두는 명령이 필요하다.
git stash
git stash save
git stash save "stash message"
# 결과 예시
Saved working directory and index state WIP on main: 94d511c fourth ticket
commit message처럼 간략한 메시지를 적고 싶다면 git stash save "<stash-message>"로 사용한다.
그러나 git stash [save] 명령은 untracked 파일들은 저장하지 않는다. 이 파일들까지 임시 저장하라면 다음과 같이 쓴다.
git stash save --include-untracked
git stash -u
반대로 stage된 파일을 stash하지 않으려면 git stash --keep-index로 사용한다.
git stash도 git add와 비슷하게 --patch 옵션을 지원한다. 남길 부분을 파일 내에서 선택하고 싶다면 해당 옵션을 사용하라.
stash로 저장한 목록을 보려면 다음 명령을 입력한다.
git stash list
#결과 예시
stash@{0}: WIP on main: 94d511c fourth ticket
stash@{1}: WIP on main: 94d511c fourth ticket
stash의 내용이 기억나지 않으면 git stash stash@{<number>} 명령을 쓴다.
git stash stash@{1}
# 결과 예시
Merge: 94d511c 7060e4d f4a6d7f
Author: greeksharifa <greeksharifa@gmail.com>
Date: Sat May 30 13:51:23 2020 +0900
WIP on main: 94d511c fourth tickek
diff --cc .gitignore
index 15c8c56,15c8c56,0000000..f6f1686
mode 100644,100644,000000..100644
--- a/.gitignore
+++ b/.gitignore
@@@@ -1,3 -1,3 -1,0 +1,5 @@@@
+
+.idea/
+*dummy*
+++
+++*.txt
diff --cc doonggoos.py
...
잠시 넣어 둔 stash를 다시 작업트리로 꺼내오려면 git stash apply stash@{<number>}를 사용한다.
git stash apply stash@{0}
# 결과 예시
On branch main
Your branch and 'origin/main' have diverged,
and have 3 and 2 different commits each, respectively.
(use "git pull" to merge the remote branch into yours)
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: doonggoos.py
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: .gitignore
modified: fourth.py
어떤 파일들이 변경되었는지 알려준다.
더 이상 안 쓸 stash를 제거하려면 git stash drop stash@{<number>}를 사용한다.
git stash drop stash@{0}
#결과 예시
Dropped stash@{0} (9f700348f8688c3cbc21c17e4bc3d231b3abd0c3)
작업트리 청소하기: git clean
untracked 파일을 그냥 없애버리고 싶다면 git clean -d를 쓴다.
tracking하지 않는 모든 정보를 지워버리려면 git clean -f -d를 사용한다. 말 그대로 강제(-f, force)다.
그냥 지워버려도 되는지 확인하고 싶다면 -n 옵션을 붙여서 실행시키면 된다. 그러면 어떤 파일들이 영향을 받는지 알려준다.
.gitignore에 명시한 등 무시되는 파일은 git clean으로 지워지지 않는다. 이런 파일들까지 싹 다 지우려면 -x 옵션을 붙인다.
대화형으로 실행하려면 -i 옵션을 붙이면 된다.
최초의 오류 commit 찾기: git bisect
git bisect는 일종의 디버깅 툴이다. 코드에 어떤 버그가 있지만 그게 언제 추가됐는지 정확히 모를 때 쓴다.
bisect를 쓰려면 우선 다음 조건이 필요하다.
- 어떤 문제가 있는 시점을 알고(보통은 현재일 것이다)
- 해당 문제가 없는 과거의 어떤 commit 시점을 알고 있을 때
그러면 git bisect를 통해 이분탐색을 수행하여 잘못된 코드가 어떤 commit에서 나타났는지 찾는다. 이분 탐색하며 중간 지점의 commit에서 다시 build해 보고,
- 문제가 있으면
git bisect bad 입력, 해당 commit 이전을 탐색하고,
- 문제가 없으면
git bisect good 입력, 해당 commit 이후를 탐색한다.
# 명령어 및 결과 예시
git bisect start # 시작
git bisect bad [<commit>] # 어떤 시점(<commit>을 안 쓰면 현재)에 문제가 있고
git bisect good <commit> # 어떤 시점에는 문제가 없음을 git에 알리기
Bisecting: 675 revisions left to test after this (roughly 10 steps)
# 그러면 675개의 수정 사항 중 이분 탐색을 수행한다. 2^10 = 1024이니 10단계만 테스트하면 된다.
git bisect good
Bisecting: 337 revisions left to test after this (roughly 9 steps)
git bisect <bad/good>
...
bisect 세션을 끝내고 원래 상태로 돌아가려면 git bisect reset을 입력한다.
만약 중간 지점으로 선택된 commit이 테스트할 수 없다면 bad / good 대신 git bisect skip을 입력해서 잠시 패스하고 근처의 다른 commit을 테스트 대상으로 할 수 있다.
branch에서 특정 commit만 다른 branch로 적용하기: git cherry-pick
git cherry-pick <commit> 명령은 branch의 병합 없이도 다른 branch의 특정 commit을 가져올 수 있다. ticket branch에 있는 96c99dc라는 commit을 main branch로 가져오고자 한다.
# 명령어 예시
git checkout main
git cherry-pick 96c99dc
# 결과 예시
[3rd-branch 32d6b93] example commit message
Date: Sat May 30 18:51:51 2020 +0900
1 file changed, 2 insertions(+), 3 deletions(-)
명령어 마음대로 설정하기: Git Alias
alias는 단축만 가능한 것은 아니지만, 단축할 때 많이 쓴다.
git reset HEAD -- <filename>이 입력하기 귀찮거나 자주 실수한다면, 직관적인 명령어로 바꿔 줄 수 있다.
git config alias.<another-name> '<original-command>' 형식으로 쓴다.
git config --global alias.unstage 'reset HEAD --'
이제 아래 두 명령은 동일한 효과를 갖는다.
git reset HEAD -- <filename>
git unstage <filename>
충돌 자동 해결: Reuse Recorded Resolution(git.rerere)
정확히는 전부 자동으로 해 주는 것은 아니고, 예전에 비슷한 충돌을 해결한 적이 있다면 같은 방식으로 자동으로 해결하도록 설정할 수 있다.
다음 설정으로 활성화한다.
git config --global rerere.enabled true
- 처음 충돌이 났을 때
git rerere status로 충돌 파일을 확인한다. git rerere diff로 충돌을 해결한다.
- 이후 처리 과정은 일반 충돌 처리 과정과 같다.
- commit하고 나면
Recorded resolution for <filename>이라는 메시지를 볼 수 있다.
- 다음으로 비슷한 충돌이 났을 때에는 다음 메시지를 확인할 수 있다.
Resolved <filename> using previous resolution. : 이미 충돌을 해결했다는 뜻이다.- 충돌 파일을 확인해봐도 충돌된 부분을 찾을 수 없다. 그냥 commit하면 된다.