
ERNIE 논문 설명(ERNIE-Doc - A Retrospective Long-Document Modeling Transformer)
25 Jul 2021 | Paper_Review NLP ERNIE목차
이 글에서는 Baidu에서 만든 모델 시리즈 ERNIE 중 네 번째(ERNIE-Doc: A Retrospective Long-Document Modeling Transformer)를 살펴보고자 한다.
ERNIE 시리즈는 다음과 같다. 참고로 2번째는 Baidu가 아닌 Tshinghus University에서 발표한 논문이다.
- ERNIE: Enhanced Representation through Knowledge Integration, Yu sun el al., 2019년 4월
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding, Yu Sun et al., 2019년 6월
- ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph, Fei Yu et al., 2019년 6월
- ERNIE-Doc: A Retrospective Long-Document Modeling Transformer, Siyu Ding et al., 2020년 12월
- ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation, Yu Sun et al., 2021년 7월
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
ERNIE-Doc: A Retrospective Long-Document Modeling Transformer
논문 링크: ERNIE-Doc: A Retrospective Long-Document Modeling Transformer
초록(Abstract)
Transformers는 계산량이 sequence의 제곱에 비례해서 길이가 긴 문서를 다루는 데는 적합하지 않다. 단순히 넘치는 부분을 자르는 것은 의미를 훼손할 수 있다.
본 논문에서는 문서 서준 언어 사전학습 모델인 ERNIE-DOC을 제안한다. Retrospective feed mechanism과 enhanced recurrence mechanism을 사용하여 더 긴 길이에 효과적이고 전체 문서의 문맥적 의미를 효율적으로 잡아낼 수 있다. ERNIE-DOC이 문서수준 segment reordering 목적함수를 최적화하여 segment 간 관계를 학습할 수 있게 하여 결과적으로 좋은 성과를 얻었다.

1. 서론(Introduction)
Transformer는 자기지도 방식을 통해 NLP의 광범위한 분야에서 좋은 성과를 얻었다. 그러나 길이의 제곱에 비례하는 계산량은 상당한 부담이 되었다.
BERT는 길이 512를 최대로 하여 진행하였고 널리 쓰였으나 이 또한 context fragmentation 문제가 발생하는 등 한계가 명확했다. 이를 해결하기 위해 이전 segment의 정보를 다음 segment를 처리하는 데 활용하는 방법을 사용하는 Recurrence Transformers 등이 제안되었다.
그러나 여전힌 문서 전체의 문맥 정보를 다 잡아내지 못하였다. 그래서 Recurrence Transformer에 기반한 ERNIE-DOC(A Retrospective Long-Document Modeling Transformer)을 제안한다.
- ERNIE-DOC에서, 각 wegment를 입력으로 두 번 주는 retrospective feed mechanism을 고안, retrospective phase 내의 각 segment는 명시적으로 전체 문서의 정보를 융할할 수 있게 되었다.
- 그러나 이것만으로는 부족한데, 최대 문맥 길이가 layer의 수에
2. 관련 연구(Related Work)
3. doc
4. 실험(Experiments)
5. 분석(Analysis)
###
6. 결론(Conclusion)
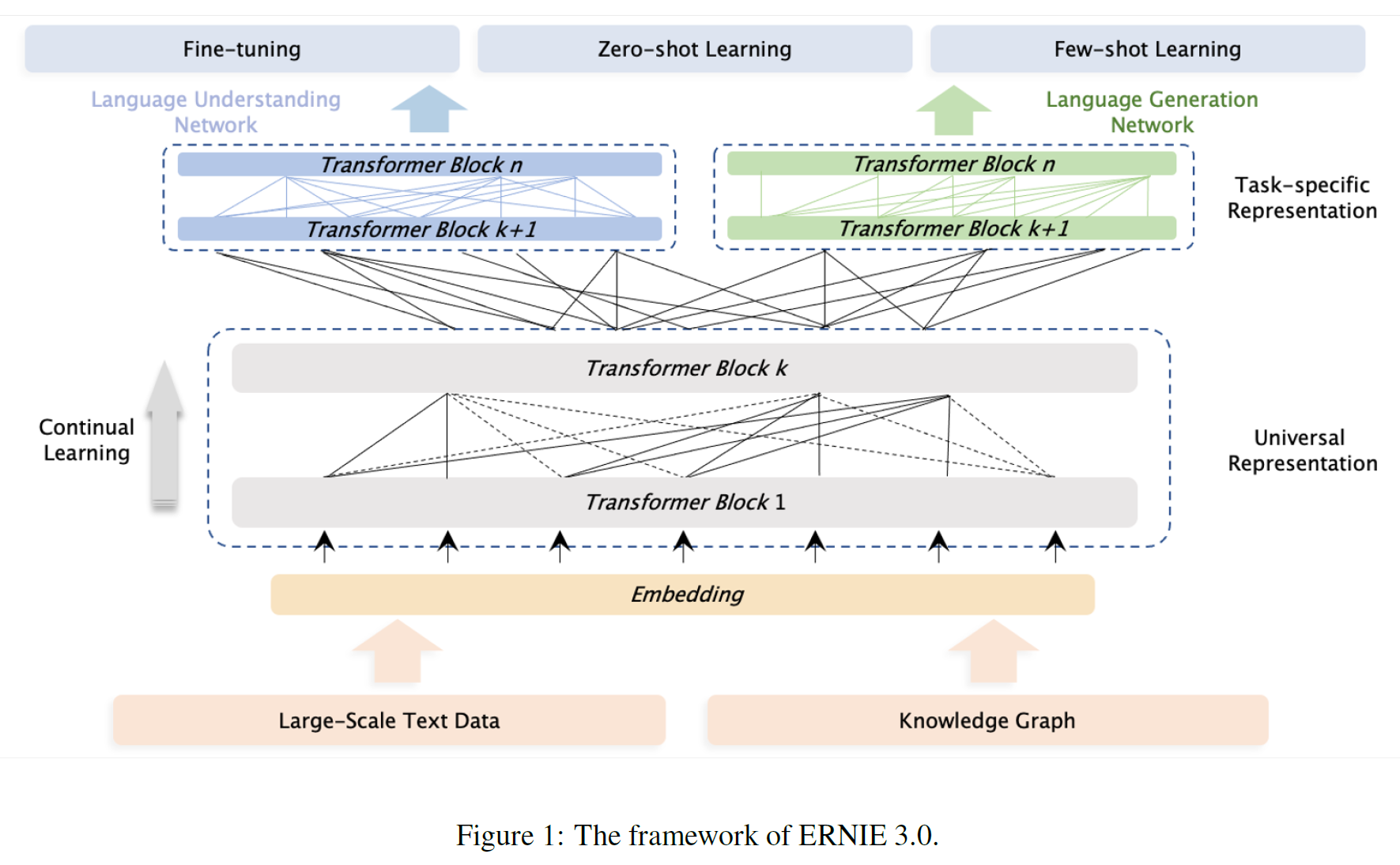
4TB의 대규모 말뭉치, 10B개의 parameter를 갖는 사전학습 framework ERNIE 3.0을 제안하였다. ERNIE 3.0은 auto-encoder, auto-regressive 네트워크를 통합한 사전학습 framework로 자연어이해, 생성, zero-shot 학습에서 모두 좋은 성능을 보였다.
참고문헌(References)
논문 참조!