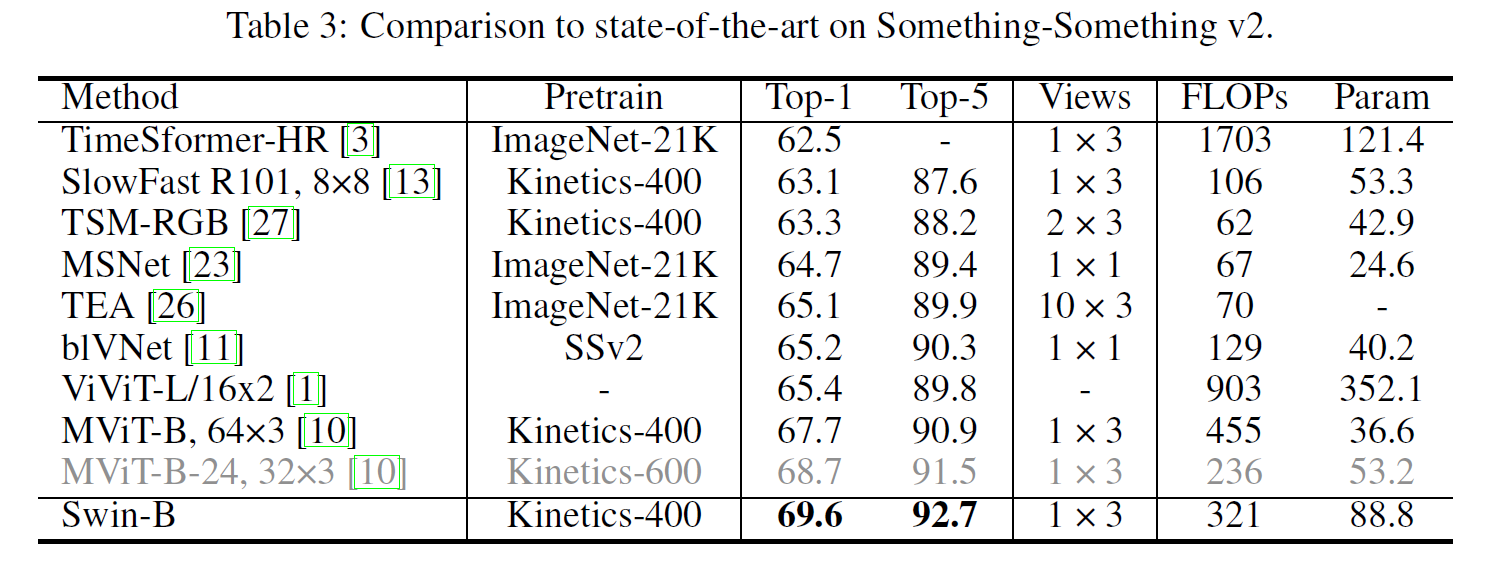
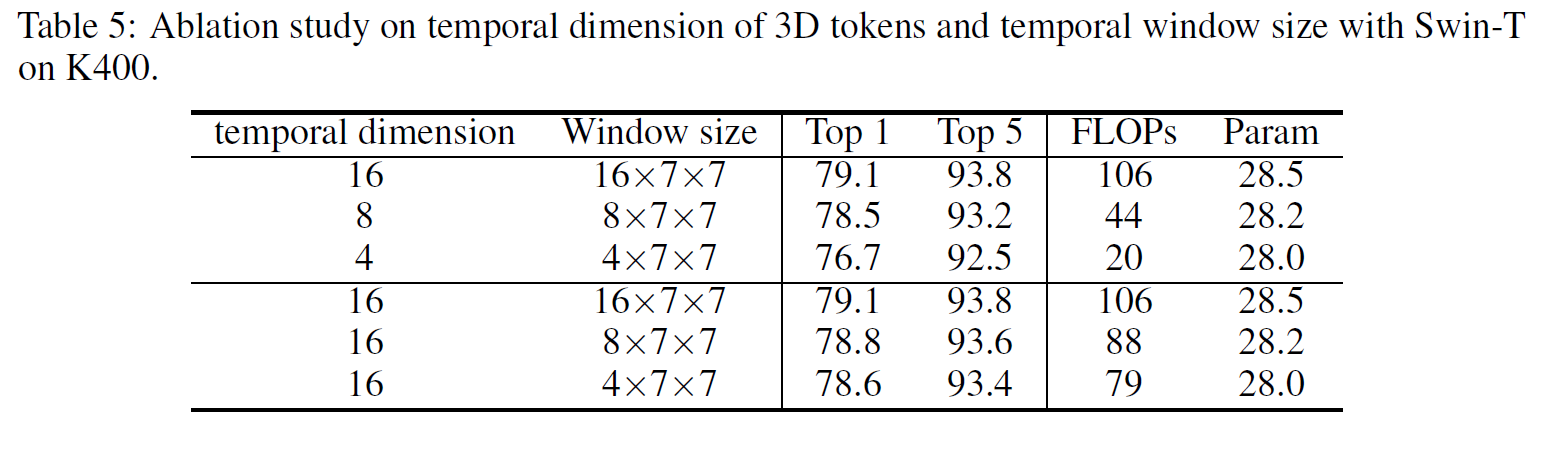
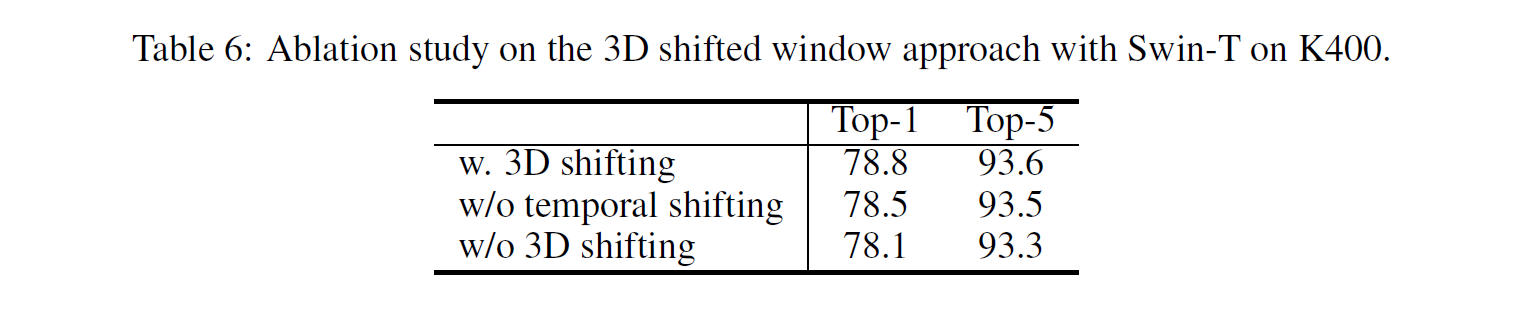
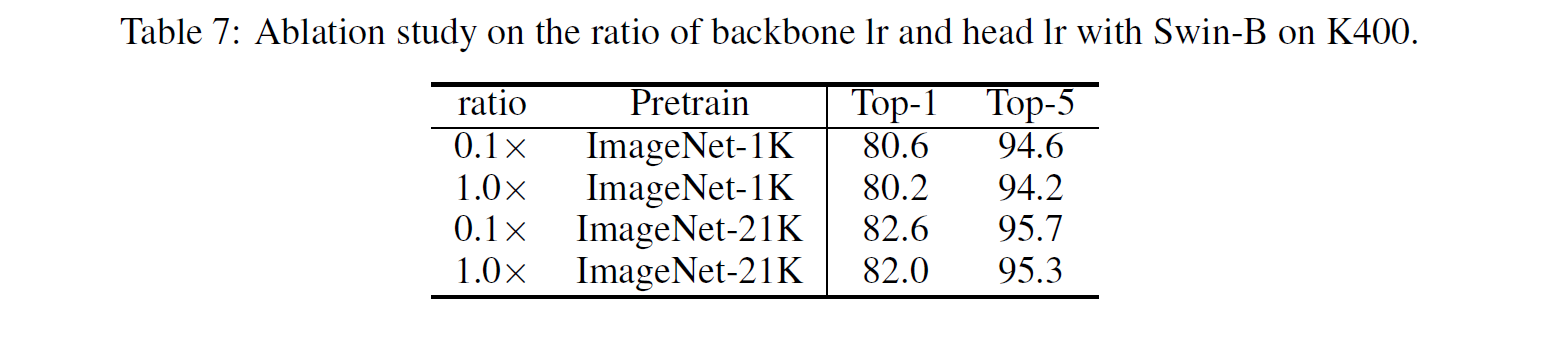
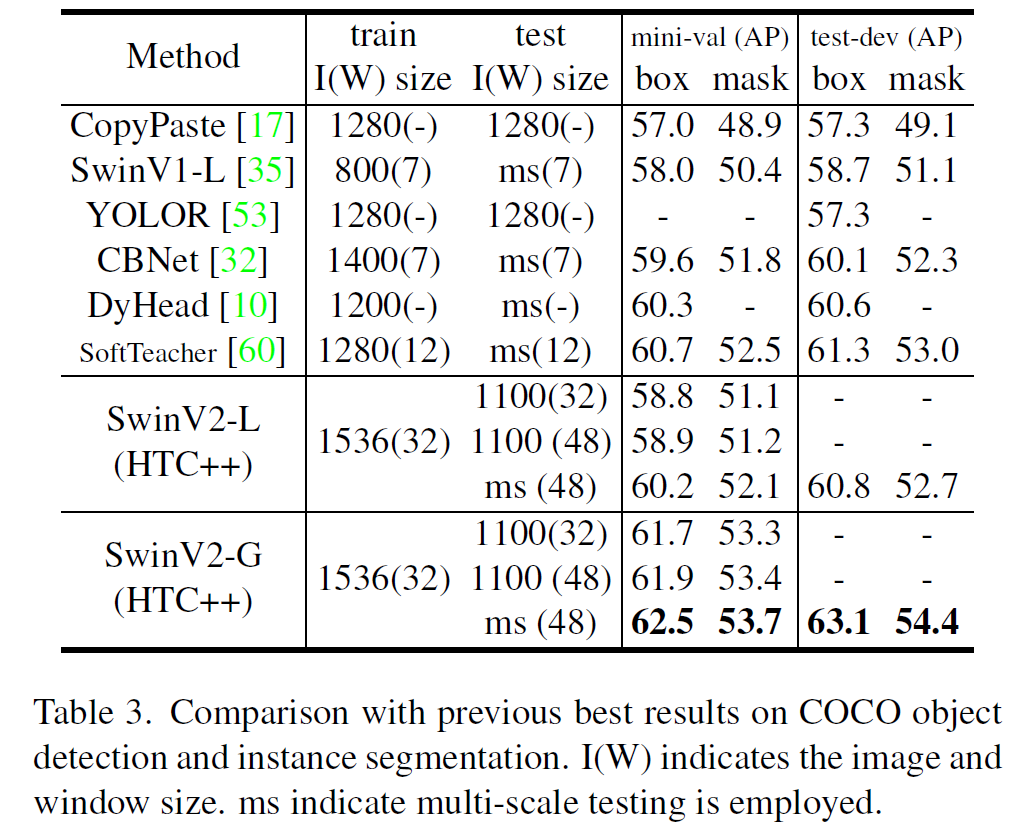
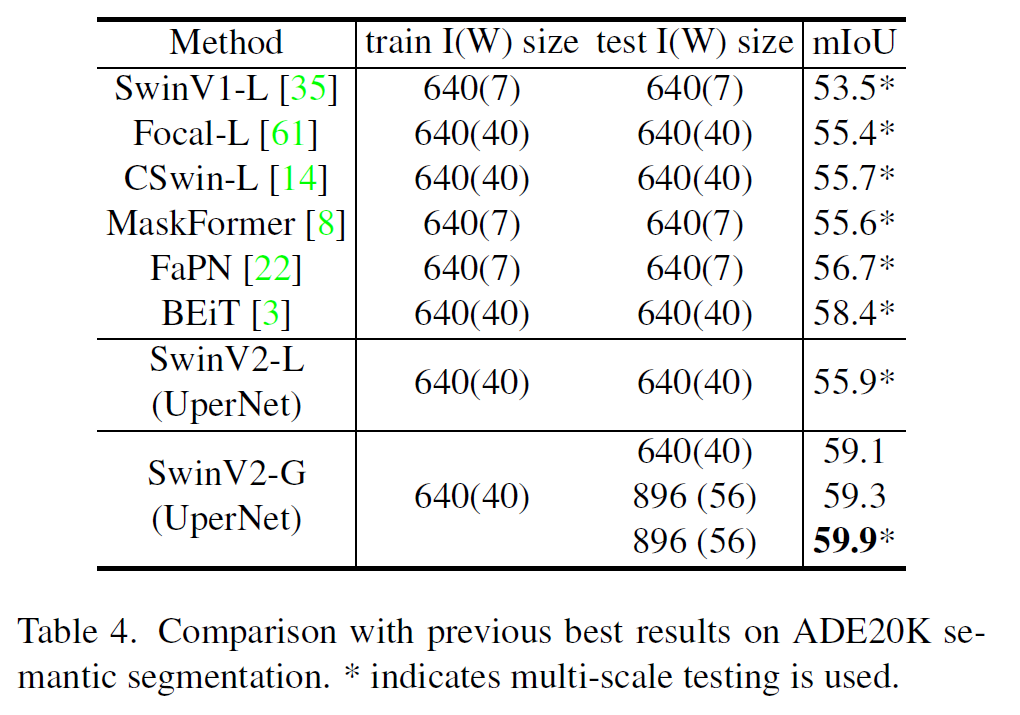
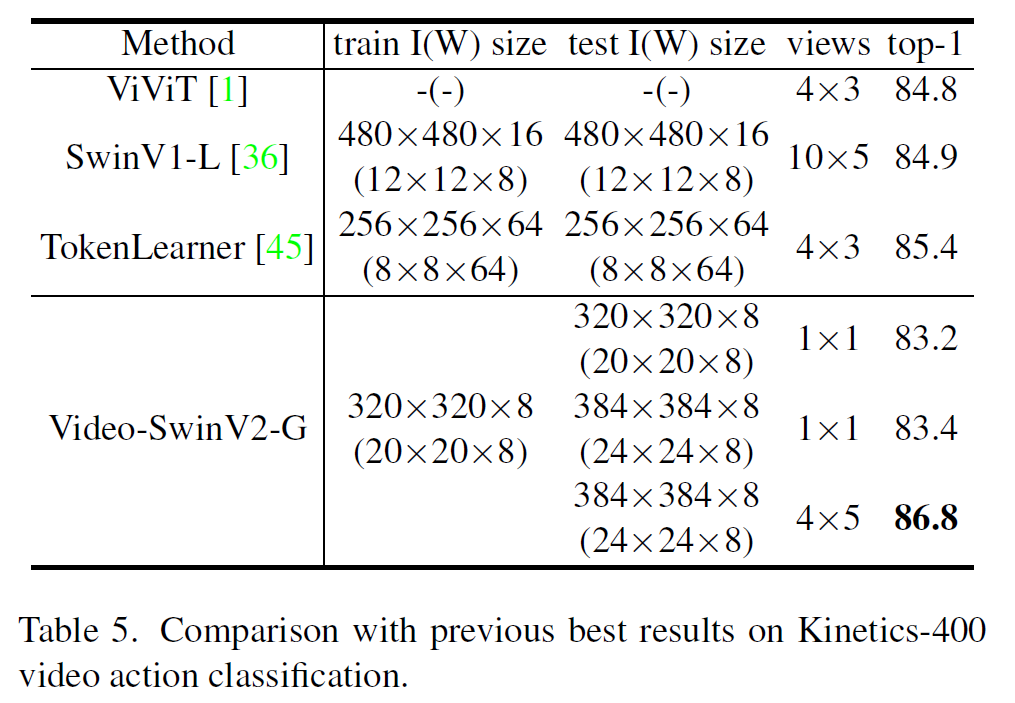
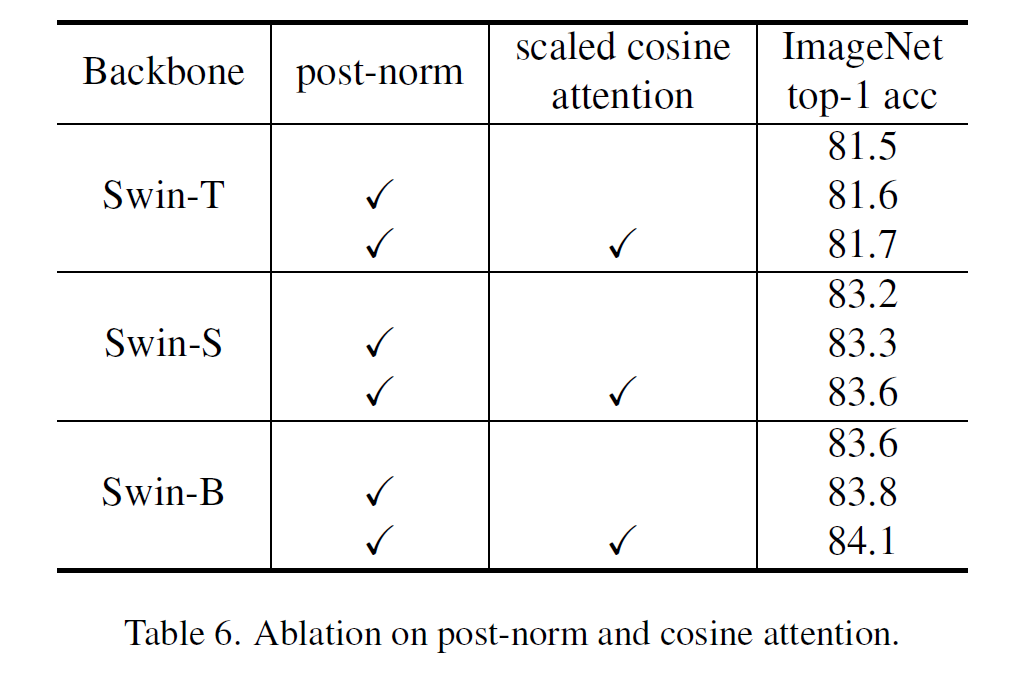
이 글에서는 2021년 1월 OpenAI에서 발표한 CLIP 논문을 간략하게 정리한다.
CLIP
논문 링크: Learning Transferable Visual Models From Natural Language Supervision
Github: https://github.com/openai/CLIP
OpenAI Blog: https://openai.com/blog/clip/
- 2021년 1월(OpenAI Blog)
- OpenAI
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, et al.
간단히, 이미지와 텍스트를 같은 공간으로 보내서 (Multimodal) representation learning을 수행하는 모델이다.
Abstract
기존 SOTA Computer vision 시스템은 고정된 집합의, 미리 지정한 object category에 대해서만 예측을 수행하도록 학습했다. 이는 확장성, 일반성 등을 심각하게 저해하며 데이터를 모으기도 힘들다.
CLIP은 인터넷에서 얻은 대규모 데이터셋을 이용, 이미지와 연관된 caption으로 사전학습한다. 그리고 자연어 지시문(reference)을 주면 zero-shot으로 모델을 downstream task에 적용할 수 있다.
결과적으로 OCR, action recognition 등 30개의 기존 task에서 좋은 성능을 보였다.
1. Introduction and Motivating Work
BERT, OpenAI GPT 등 기존 연구들은 대규모 텍스트 데이터를 모아 사전학습 후 미세조정(pre-training and fine-tuning)하는 방식으로 자연어처리 분야에서 매우 뛰어난 성과를 얻었다. 그러나, 이런 방식이 computer vision 분야에서도 잘 작동하는가?
이미지 분야에서는 CNN 기반 모델이 강한 면모를 보이기는 하지만, zero-shot learning에서는 매우 낮은 정확도를 보인다. 또 weak supervised learning 방식으로도 어느 정도 성과를 보였으나, 저자들은 이 방식은 zero-shot 학습 능력을 제한한다고 주장한다.
본 논문에서는 4억 개의 이미지 + 텍스트(caption) 쌍으로 대규모 학습한 모델로, 자연어 supervision을 사용하여 학습하였다. 그리고 매우 많은 vision task에서 굉장히 좋은 결과를 얻었다… 어떻게?
2. Approach
2.1. Natural Language Supervision
CLIP은 자연어를 supervision으로 주어 학습한다. 사실 이는 새로운 아이디어는 아니지만, 기존의 많은 image dataset과는 달리 별도의 번거로운 labeling 작업이 필요 없다는 강력한 장점을 가지고 있다. 또한, 이미지에 더해 자연어까지 representation learning을 수행할 수 있고, 다른 종류의 task로도 유연하게 zero-shot transfer이 가능하다. (그래서 자연어 supervision 방식을 취하였다)
2.2. Creating a Sufficiently Large Dataset
- 기존의 MS-COCO, Visual Genome은 품질은 좋으나 그 양이 매우 적다.
- YFCC100M은 매우 큰 데이터셋이지만 그 품질이 좀 들쑥날쑥하다.
CLIP에서는 WIT(WebImageText)라고 명명하는 새로운 데이터셋을 만들었다. 이는 인터넷의 다양한 사이트에서 가져온 4억 개의 (image, text) 쌍으로 구성되어 있다.
2.3. Selecting an Efficient Pre-Training Method
1개의 batch는 $N$개의 (image, text) 쌍으로 구성된다. 그러면, $N$개의 쌍을 모든 $i, j$에 대해서 비교하면 $N$개의 positive pair와 $N^2-N$개의 negative pair를 얻을 수 있다.
그리고
- image와 text를 하나의 공통된 space로 보낸 다음
- positive pair에서의 유사도(cosine similarity)는 최대화하고
- negative pair에서의 유사도는 최소화하도록
- CE loss를 사용하여 학습한다.
이와 같은 과정을 통해 CLIP은 multi-modal embedding space를 학습하게 된다.
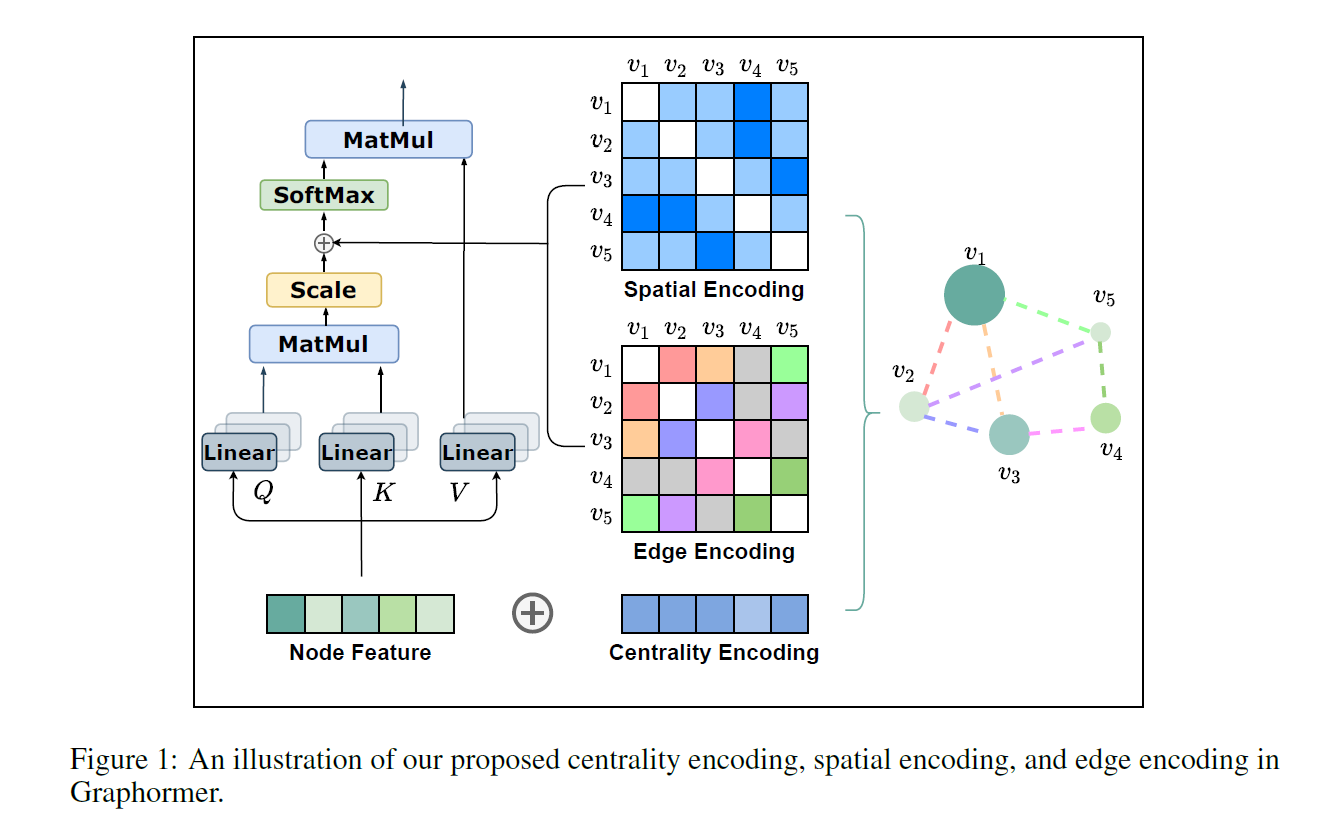
아래 그림에서 파란색 부분이 (이미지, 해당 이미지와 연관된 텍스트)로 구성된 positive pair이다.
논문에 있는 아래 코드를 보면 무슨 말인지 이해하기 쉽다.

2.4. Choosing and Scaling a Model
위의 코드에서 image_encoder와 text_encoder를 볼 수 있을 것이다.
- Image encoder: 2개의 architecture를 고려했다.
- ResNet-50에서 약간 수정된 버전인 ResNet-D 버전을 사용한다. Global Average Pooling을 Attention Pooling으로 대체하였다.
- 또한 ViT도 사용한다. Layer Norm 추가 외에는 별다른 수정이 없다.
- Text encoder로는 Transformer를 사용했다. max_length=76인데, 실제 구현체에서는 마지막 token을 고려해서인지 77로 설정되어 있다.
2.5. Training
- ResNet은 ResNet-50, ResNet-101, ResNet-50의 4배, 16배, 64배에 해당하는 EfficientNet-style 모델 3개(RN50x4, RN50x16, RN50x64)를 추가로 더 학습시켰다.
- ViT는 ViT-B/32, ViT-B/16, ViT-L/14를 사용하였다.
- 전부 32 epoch만큼 학습시켰다.
3. Experiments
3.1. Zero-Shot Transfer
3.1.1. Motivation
(대충 중요하단 내용..)
3.1.2. Using CLIP for zero-shot transfer
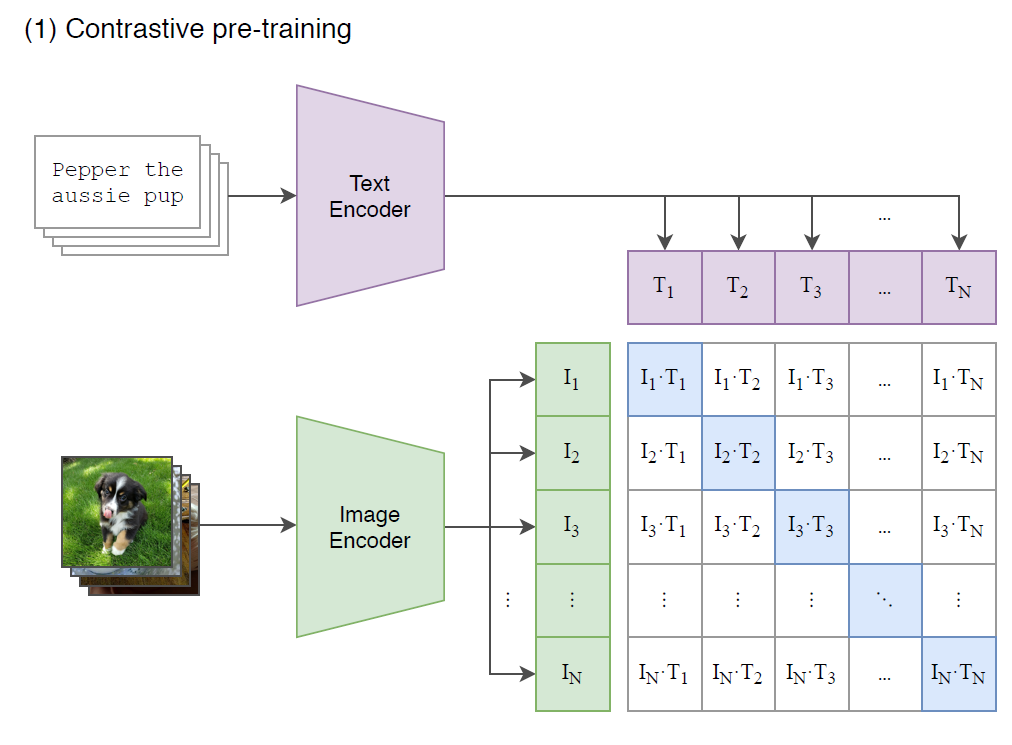
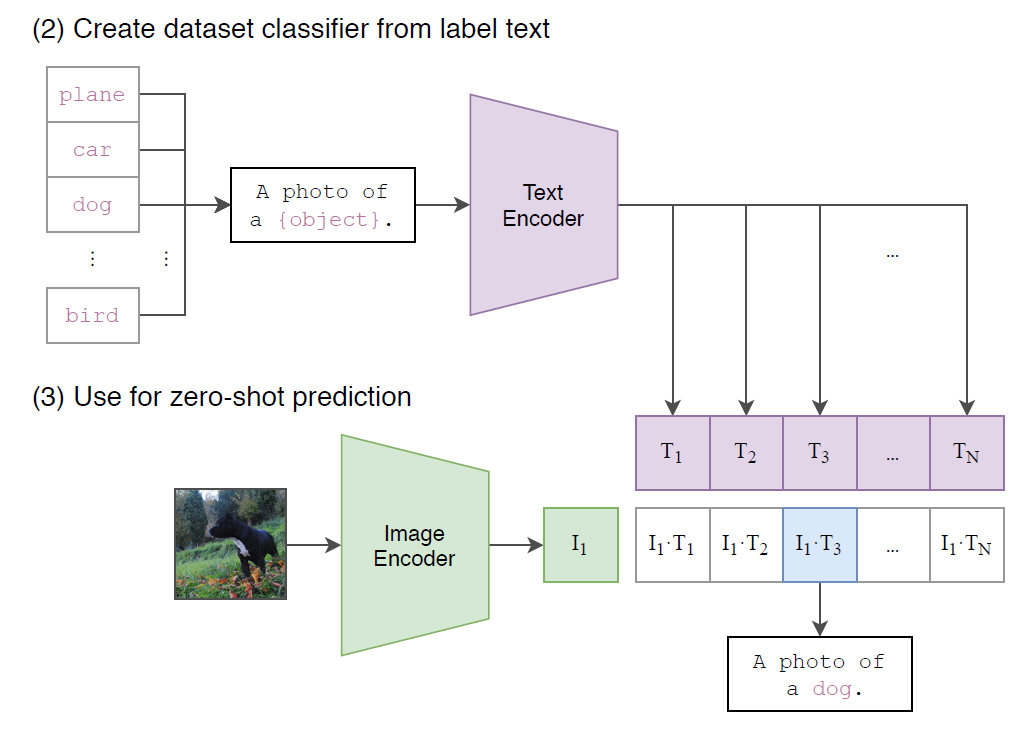
(이미지 분류 task의 경우) 이미지가 주어지면 데이터셋의 모든 class와의 (image, text) 쌍에 대해 유사도를 측정하고 가장 그럴듯한(probable) 쌍을 출력한다.
구체적으로는 아래 그림과 같이, 각 class name을 "A photo of a {class}." 형식의 문장으로 바꾼 뒤, 주어진 이미지와 유사도를 모든 class에 대해 측정하는 방식이다.
3.1.3. Initial comparison to visual n-grams
이미지 분류 문제에서 Visual N-grams 방식보다 실험한 3개의 데이터셋 모두에서 zero-shot 성능이 훨씬 뛰어나다.

3.1.4. Prompt engineering and ensembling
- 절대다수의 이미지 데이터셋은 그 class를 그냥 단순히 숫자로 구성된
id만으로만 저장해 두고 있다.
- 또 다의성 문제도 있는데, class name 외에 추가적인 정보가 없는 경우 다른 class로 인식할 수 있는 문제도 존재한다.
- CLIP을 zero-shot으로 이미지 분류를 시킬 때 하나의 문제는 class name은 대부분 한 단어 정도인 데 비해 사전학습한 데이터는 그렇지 않다는 점이다. 그래서 위에서 설명한 것처럼 class name을 그대로 집어넣어 유사도를 측정하는 대신
"A photo of a {class}." 형식의 문장을 만들어서 유사도를 측정한다.
Prompt engineering and ensembling
GPT-3에서 다룬 것과 비슷하게, 각 task에 맞는 prompt text를 적절히 선택해 주면 분류하는 데 더 도움이 될 수 있다. 예를 들어 위의 문장 형식, "A photo of a {class}."를 상황에 따라
"A photo of a {label}, a type of pet.""a satellite photo of a {label}.""A photo of big {label}""A photo of small {label}"
과 같은 식으로 바꾸면 분류를 더 잘 해낼 수 있다.
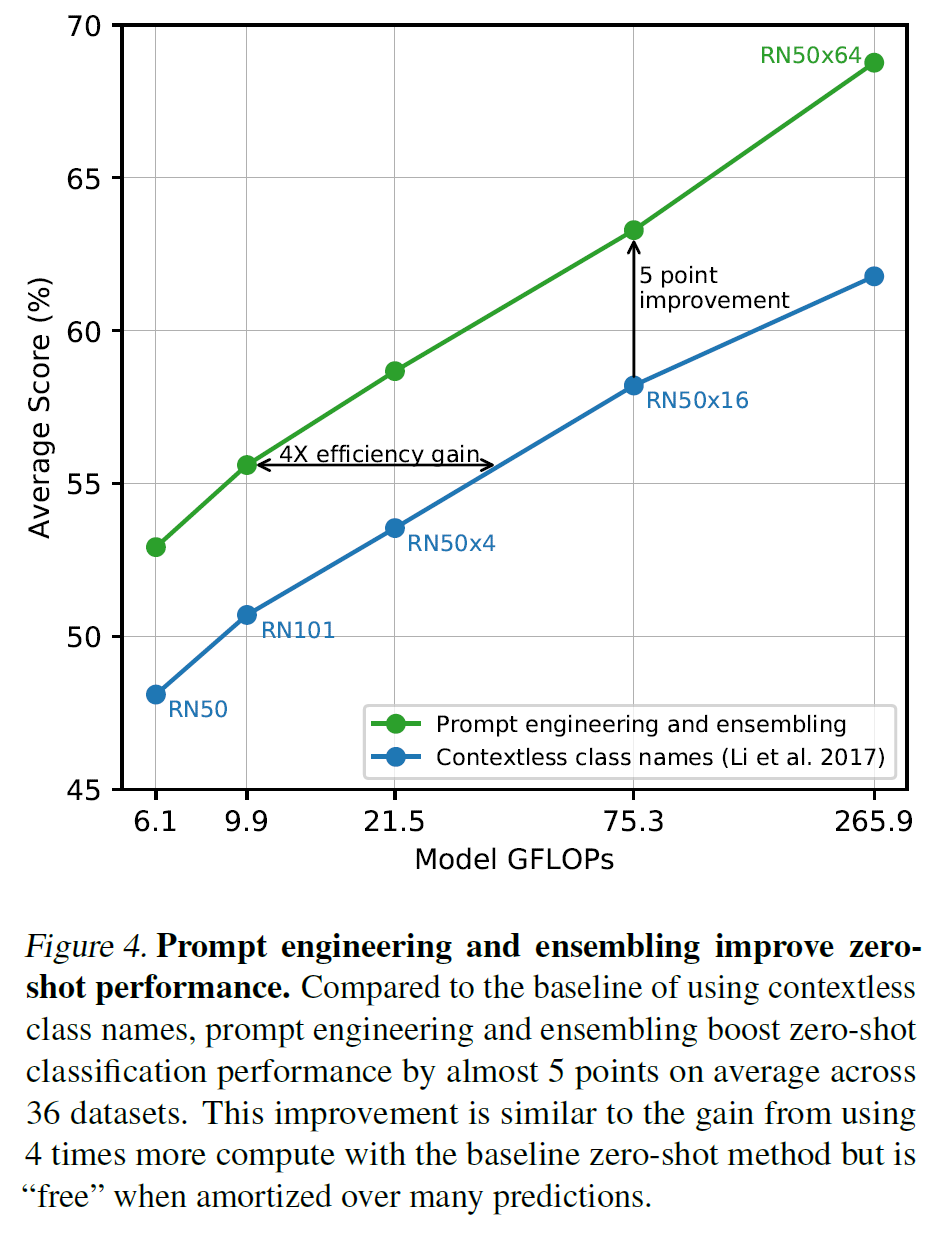
그래서 다양한 image classification 데이터셋에 대한 CLIP의 zero-shot 성능은?
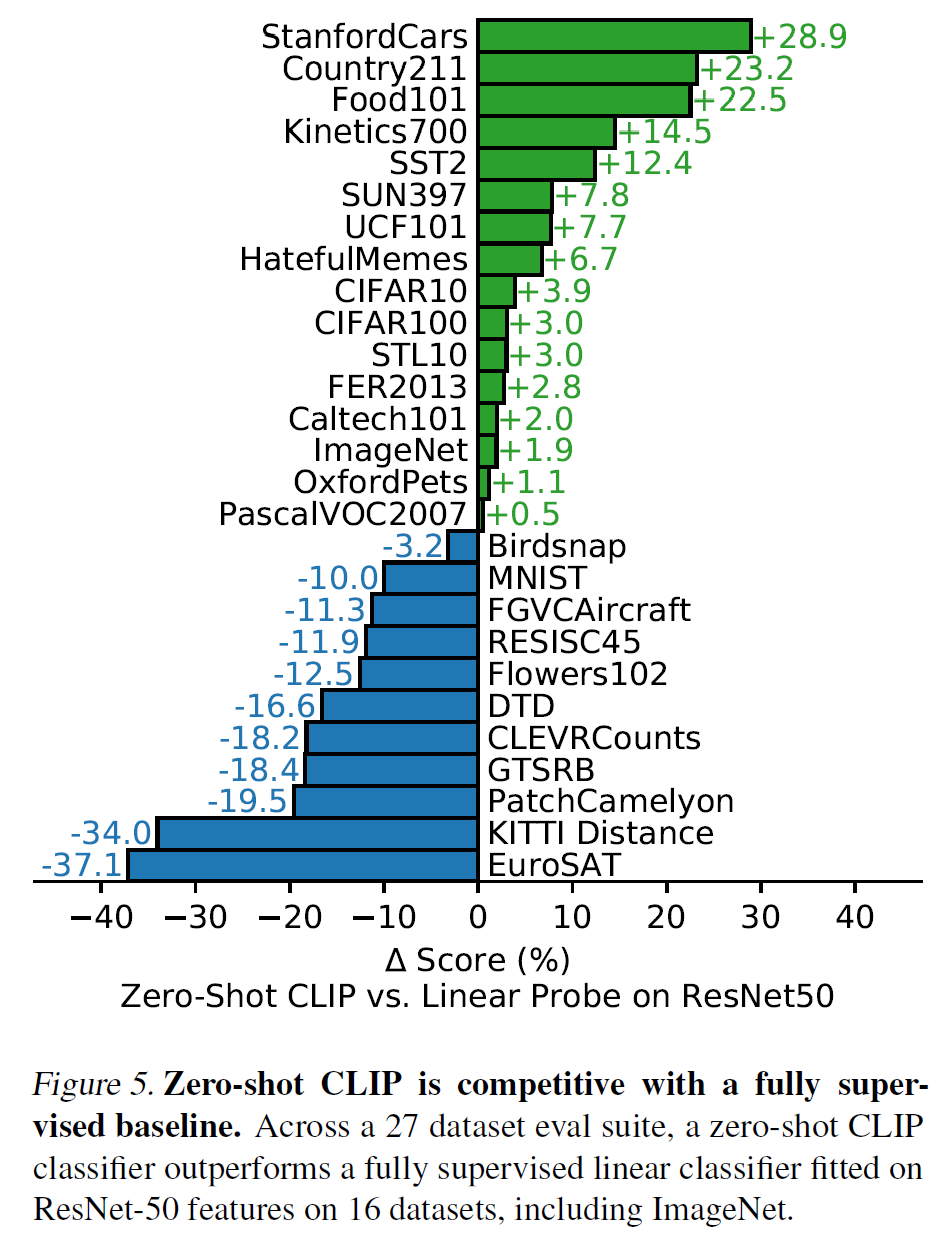
27개 중 16개의 데이터셋에서 ResNet-50 baseline에 비해 더 좋은 성능을 보였다. 여기서 데이터셋 특성별로 조금씩 성능 차가 다른데,
- Stanford Cars, Food101과 같은 fine-grained task에서는 성능이 크게 앞선다.
- OxfordPets, Birdsnap에서는 비슷비슷한데, 이는 WIT와 ImageNet 간에 per-task supervision 양의 차이 때문이라 여겨진다.
- STL10에서는 99.3%의 정확도로 SOTA를 달성했다.
- EuroSAT, RESISC45은 satellite image를 분류하는 데이터셋인데, 이렇게 상당히 특수하거나 복잡한 경우 CLIP의 성능은 baseline보다 많이 낮았다. 아마 사전학습할 때 그렇게 지엽적?인 정보는 학습하지 못했기 때문일 것이다.
아래는 다른 모델이 few-shot 성능보다 CLIP의 zero-shot 성능이 더 나음을 보여준다.
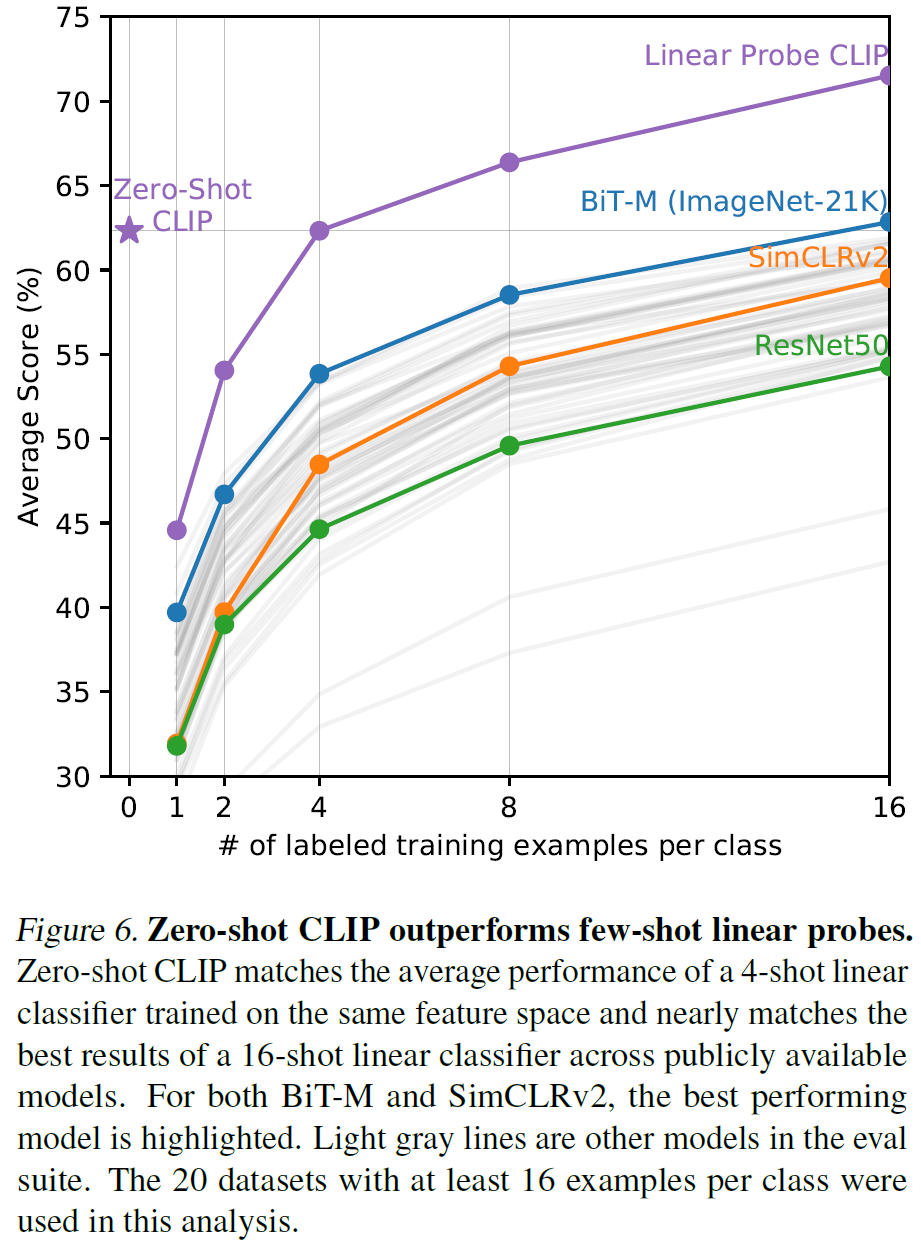
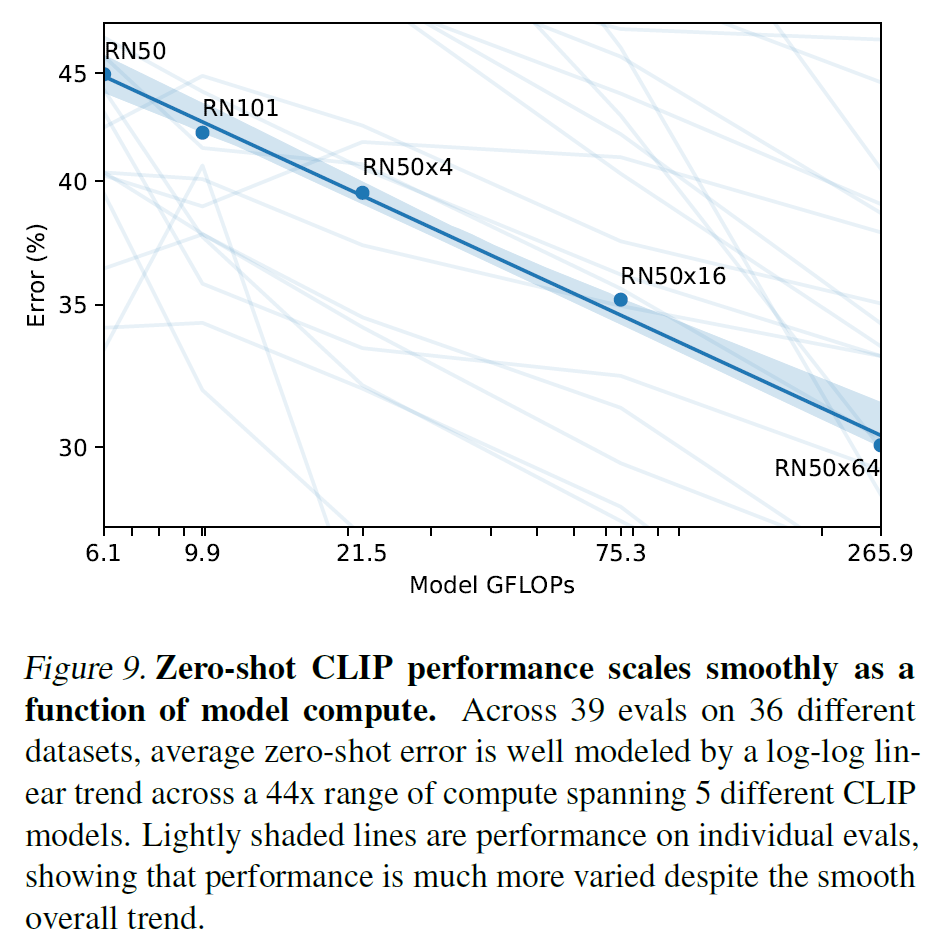
3.2. Representation Learning
Image의 특성을 최대한 잘 설명하는 어떤 feature(representation)을 잘 뽑아 이를 다른 downstream task에 활용하겠다는 것인데, CLIP은 이런 image representation을 상당히 잘 뽑는 것 같다.
모델의 representation learning 성능은 뽑아진 representation을 선형모델에 넣은 성능으로 평가하며, CLIP 논문에서도 이와 같은 방법을 사용하였다.
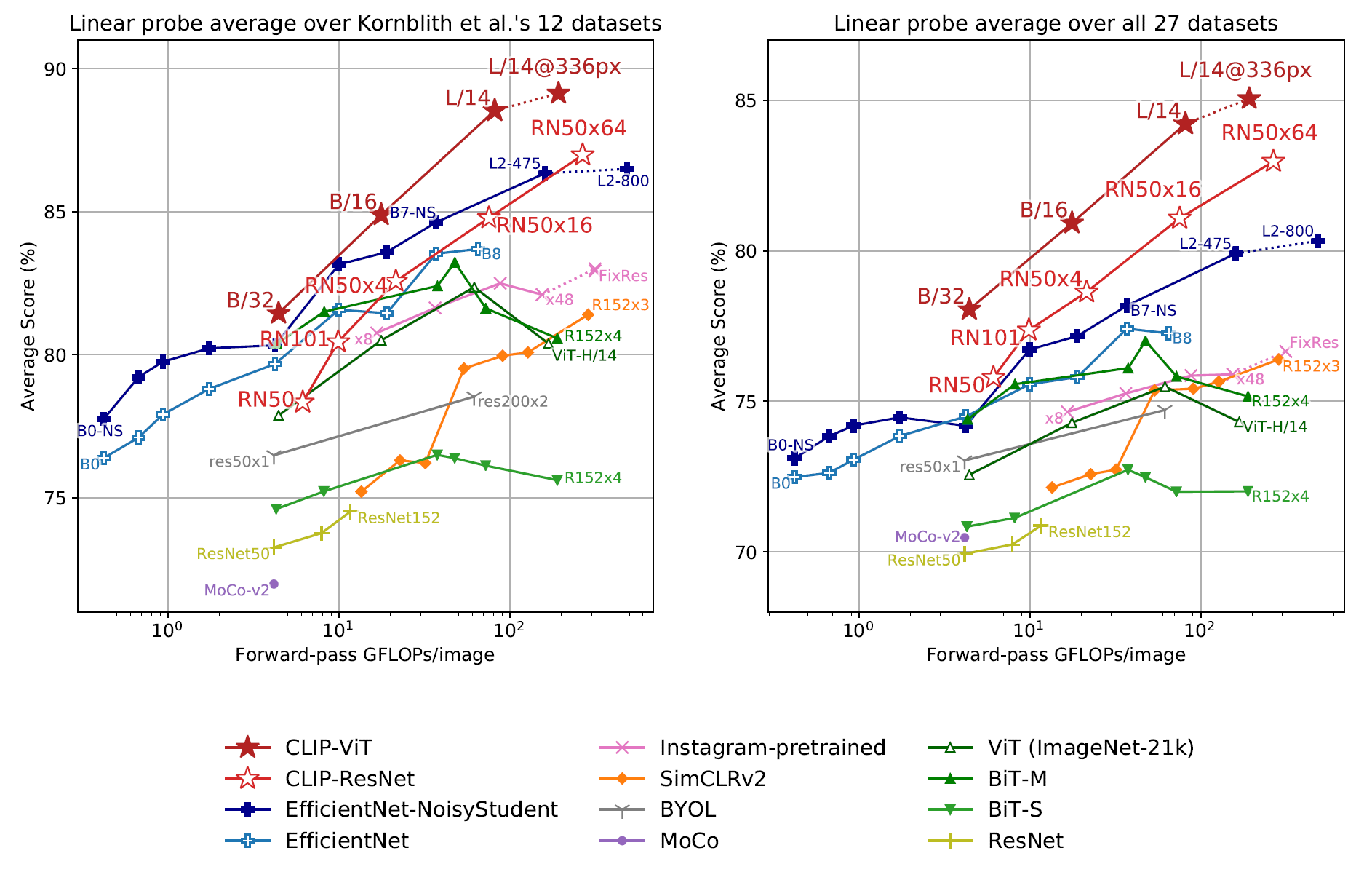
작은 모델은 기존의 SOTA보다 조금 낮은 성능을 보이지만 가장 큰 모델인 ResNetx64, ViT 기반 모델의 경우 다른 모델에 전부 앞선다.
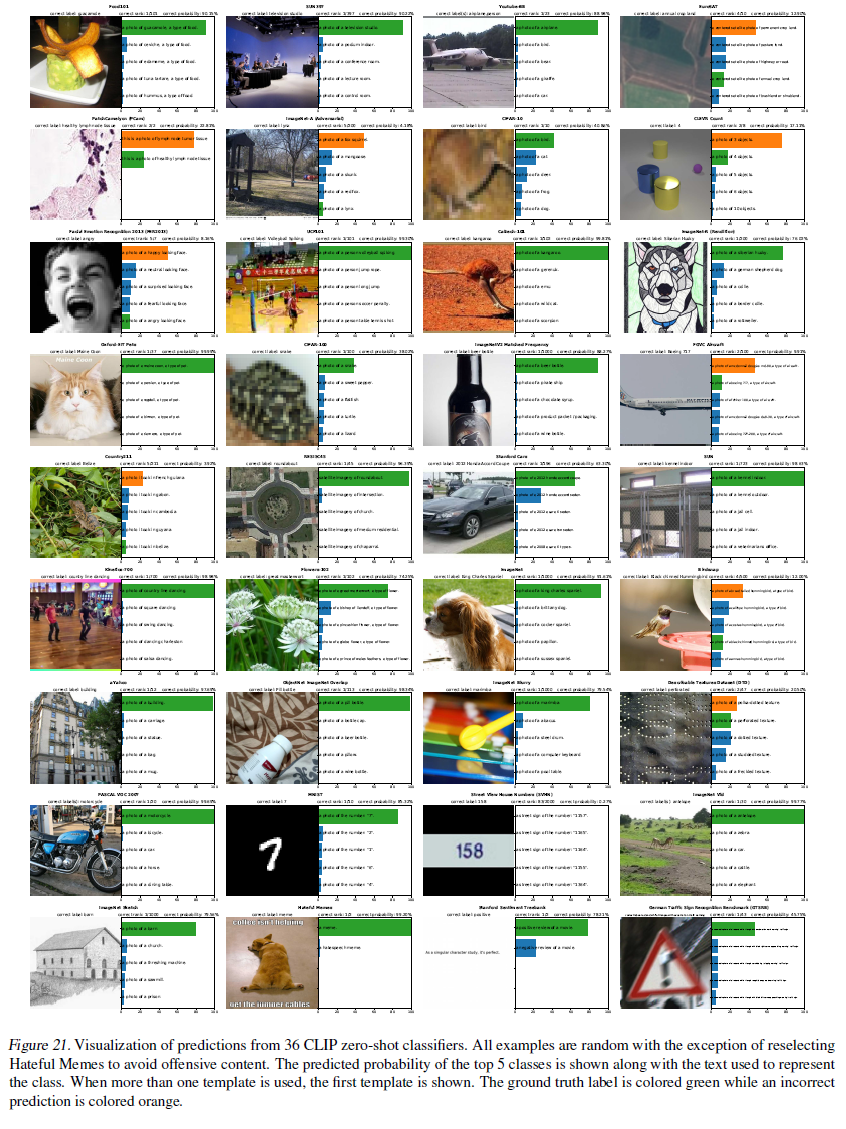
부록에서 qualitative example을 볼 수 있다.
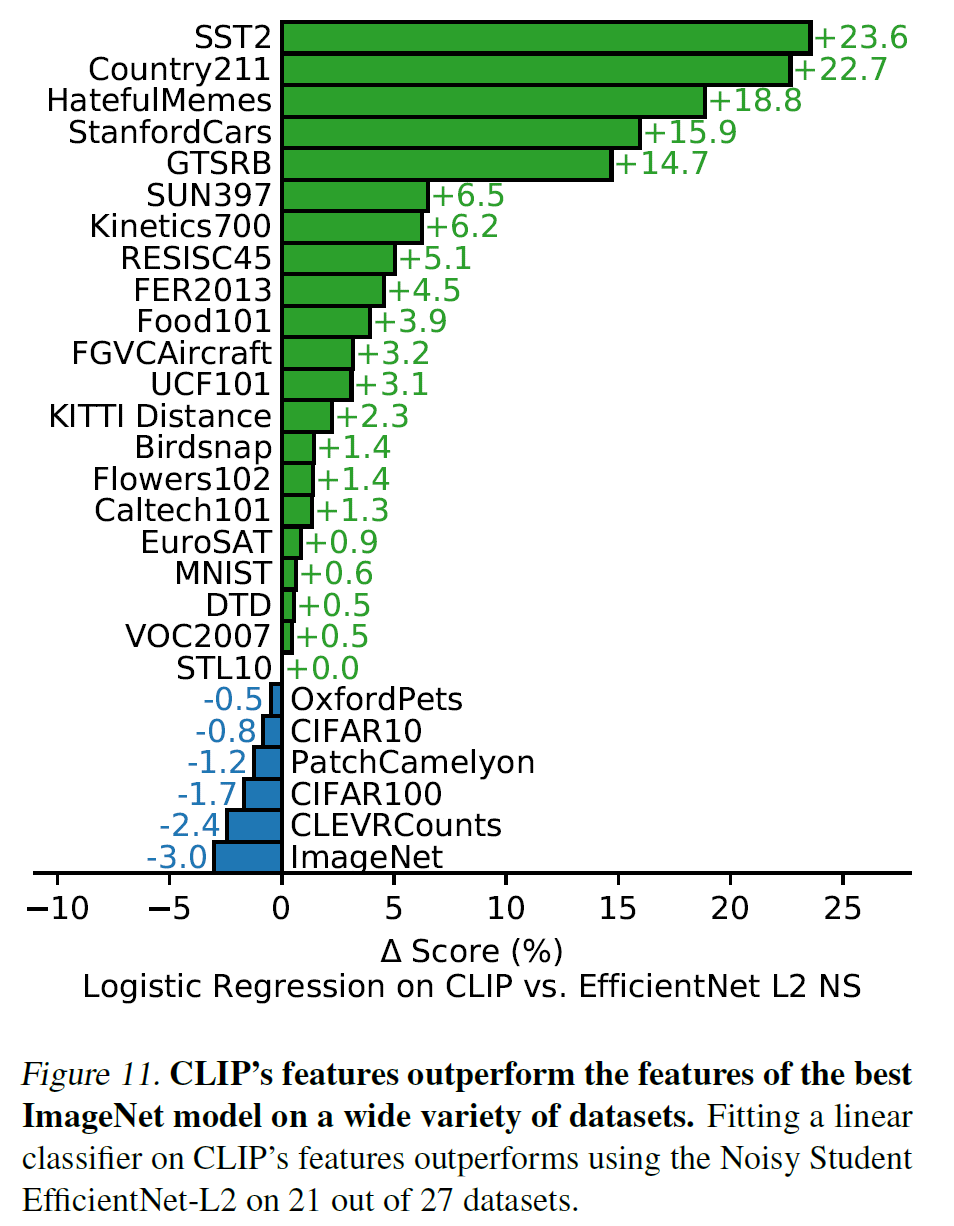
EfficientNet과 비교해 봐도 성능이 좋다.
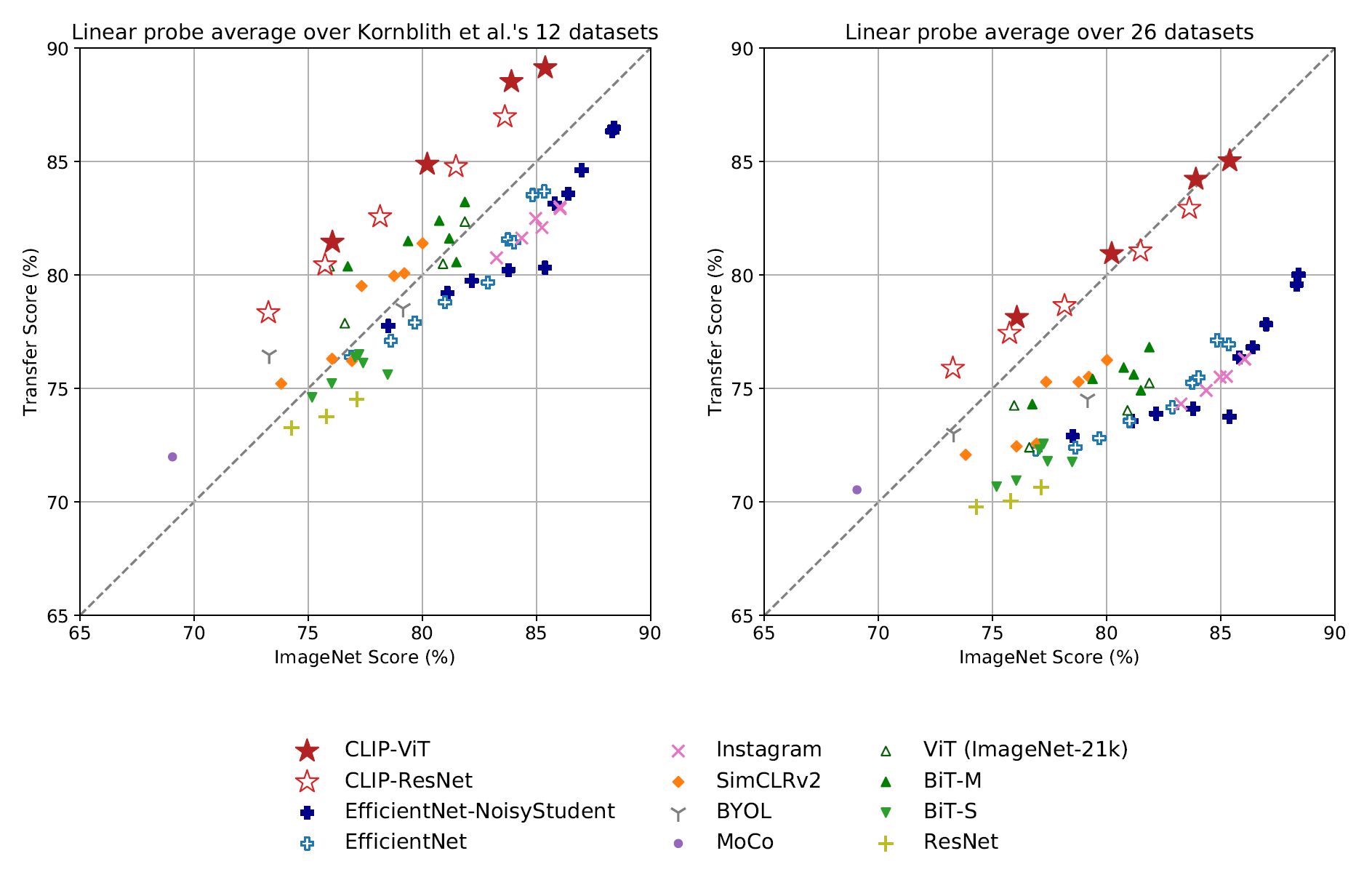
3.3. Robustness to Natural Distribution Shift
기계학습 모델의 경우 근본적으로 overfitting 위험 및 일반화 실패(혹은 낮은 일반화 성능)의 가능성이 항상 있는데, 이는 training set과 test set의 distribution이 동일할 것이라는 가정에 기초해 있기 때문이기도 하다. 이러한 차이를 distribution shift라고 한다.
참고: 이 문제를 해결하기 위한 방법이 데이터의 domain(distribution)에 불변한 어떤 것(invariants)를 뽑는 것이고, 이를 Domain Generalization라 한다.
본 섹션에서는 CLIP이 Distribution Shift에 강건함을 실험 결과로 보여준다.
먼저 아래는 task shift에 관한 것이다. 다른 task로 transfer를 수행했을 때 CLIP의 representation이 얼마나 더 나은지 보여주는 그림이라 할 수 있다.
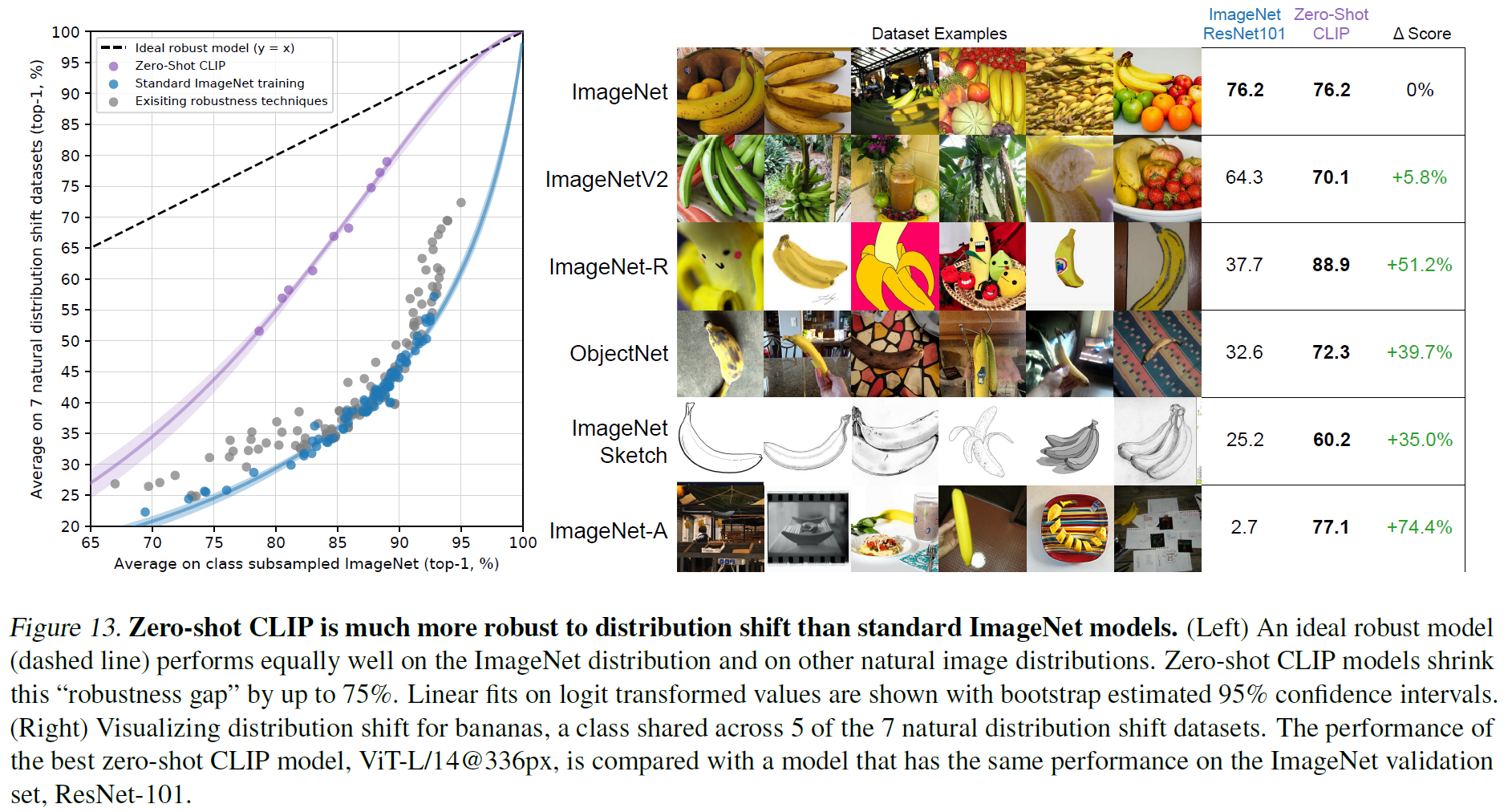
ImageNet류의 데이터셋이 여러 개 있는데, 바나나를 예로 들면
- ImageNet V1은 통상적인 바나나 상품 사진이라면,
- ImageNet V2는 좀 더 다양한 모양의 바나나 사진을,
- ImageNet-R은 실제 바나나 사진뿐만 아니라 그림이나 여러 변형이 일어난 사진
- ObjectNet은 다양한 배경이나 상황의 바나나 사진
- ImageNet Sketch는 바나나 스케치 사진
- ImageNet-A는 굉장히 다양한 구도의 바나나 사진
이런 데이터를 갖고 있는 데이터셋들인데, 각각 data distribution이 다를 것임을 쉽게 알 수 있다.
ResNet101과 비교하여, CLIP은 zero-shot 성능을 위 데이터셋에서 비교했을 때 훨씬 더 성능이 높음을 알 수 있다. 즉, distribution shift에 상당히 강건(robust)하다.
참고: 논문에서는 robustness를 2가지로 분류한다. (by Taori et al.)
- Effective robustness: Distribution shift에서의 정확도 개선
- Relative robustness: Out-of-distribution에서의 정확도 개선
물론, 모엘의 robustness를 높이려면 위 2가지 모두의 정확도에서 개선이 이루어져야 할 것이다.
아래 그림은 ImageNet에 조금 더 adaptation을 시켰을 때(정확도 9.2% 상승), 모델의 전체적인 robustness는 조금 낮아졌음을 보여준다. 일종의 trade-off가 존재한다고 보면 된다.
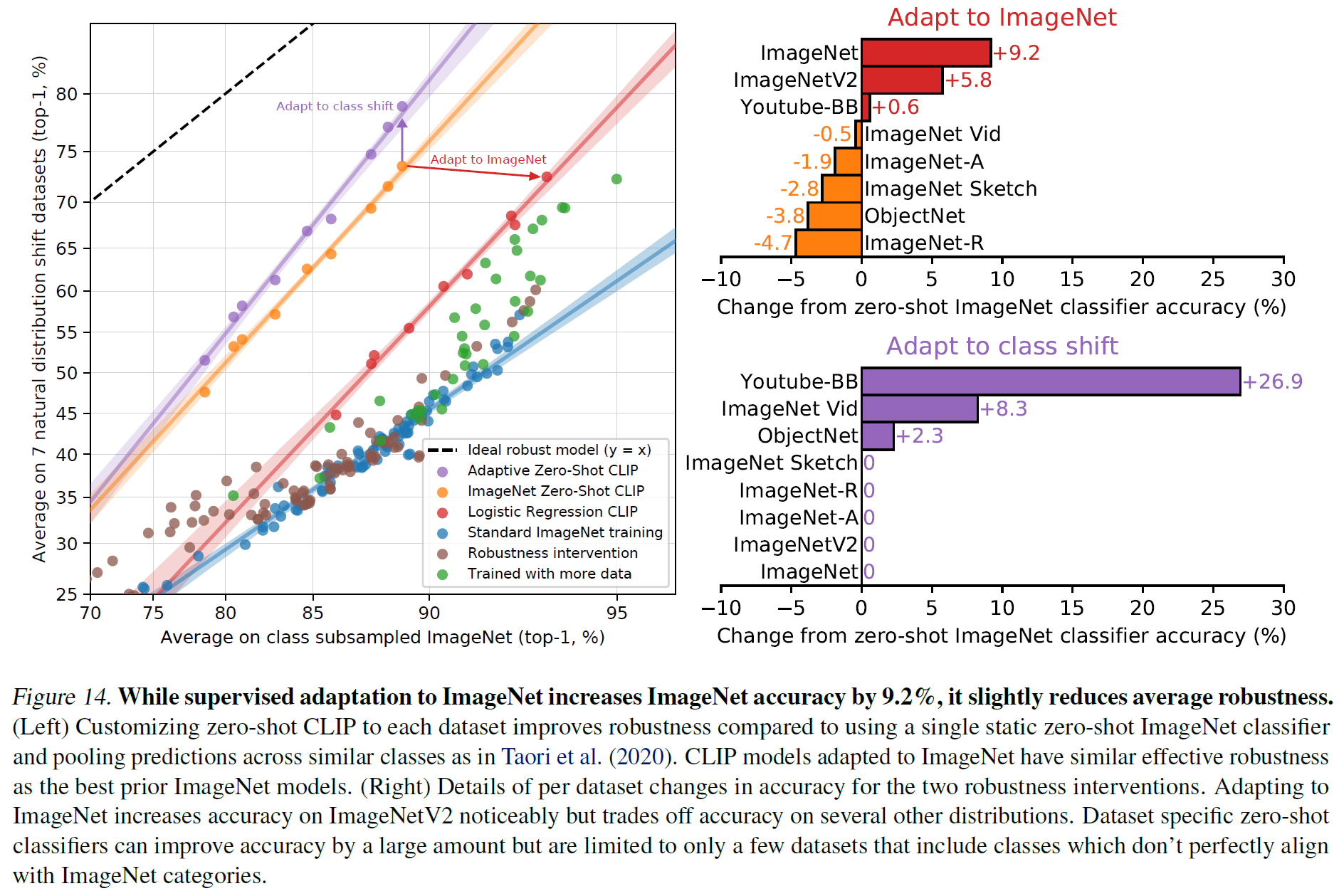
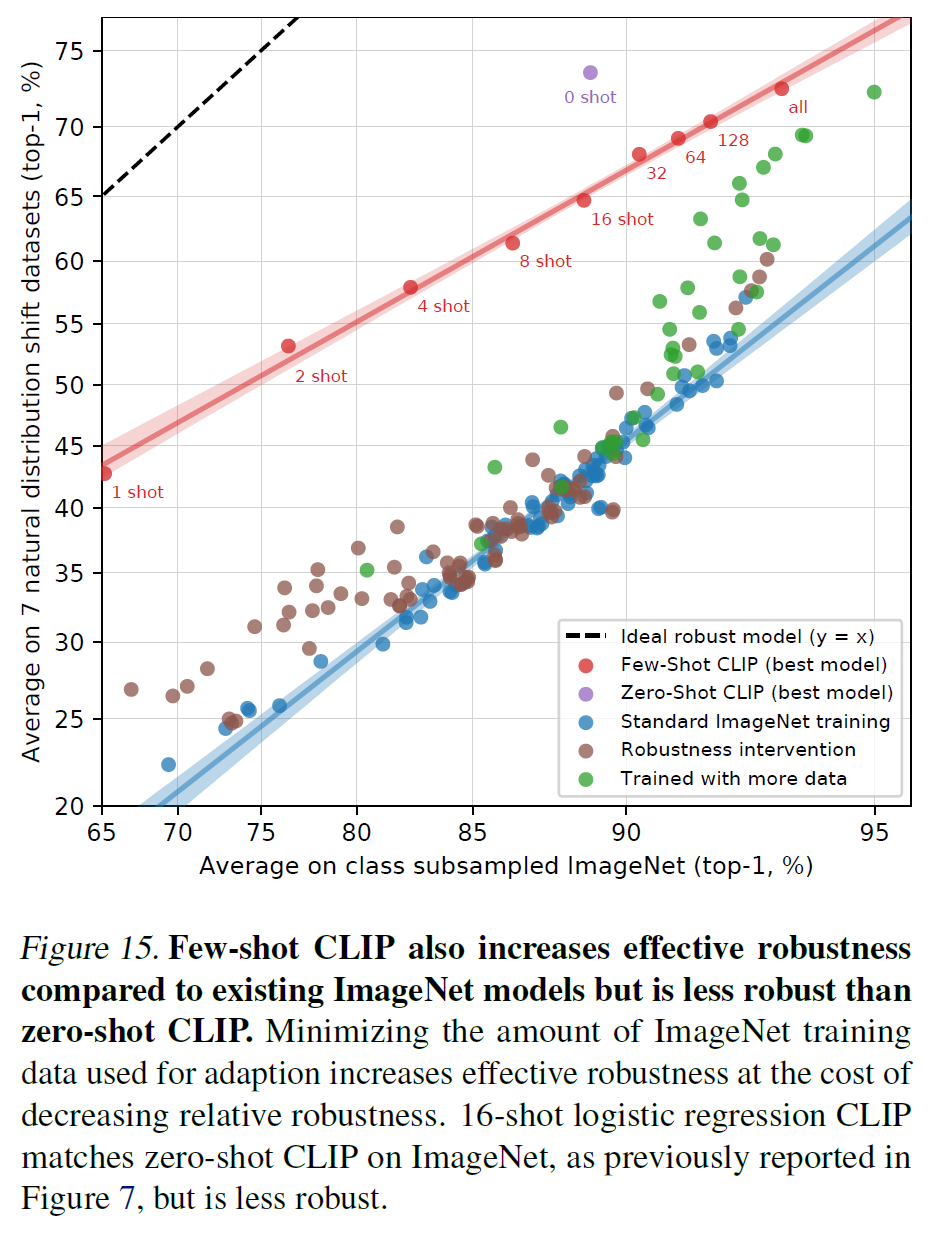
비슷하게, CLIP을 few-shot 학습을 시키면 해당 task는 더 잘 풀게 되지만, zero-shot CLIP에 비해서 robustness는 떨어진다.
본 섹션에서는 CLIP을 사람의 performance, 그리고 사람의 학습하는 정도와 비교하려고 한다.
사람도 zero-shot으로, 아무것도 보지 않고 지시문만 주어졌을 때 문제를 풀었을 때 정답률, 그리고 한두 개의 예시를 보고 나서 문제를 풀 때 정답률 등을 CLIP과 비교하는 식이다.
- 데이터셋은 Oxford IIT Pets dataset을 사용
- 5명의 다른 사람에게 test split의 3669개 이미지를 주고 37종류의 개/고양이 중 어느 것인지(혹은
I don't know를 고를 수도 있음)를 선택하게 하였다.
- 5명의 사람은 인터넷 검색 없이, 그리고 아무런 예시도 보지 못한 채 이미지를 labeling해야 한다.
- one-shot과 two-shot에서는 각 1, 2개의 예시를 본 다음 labeling을 하게 된다.
- 자세히 나와 있지는 않지만, 아마 37종의 개/고양이에 대한 기본적인 설명 정도는 있었을 것이다. 아무리 zero-shot을 한다지만 그러지 않으면 어떻게 풀겠는가?
그래서 사람과 CLIP을 비교한 결과는 아래과 같다.
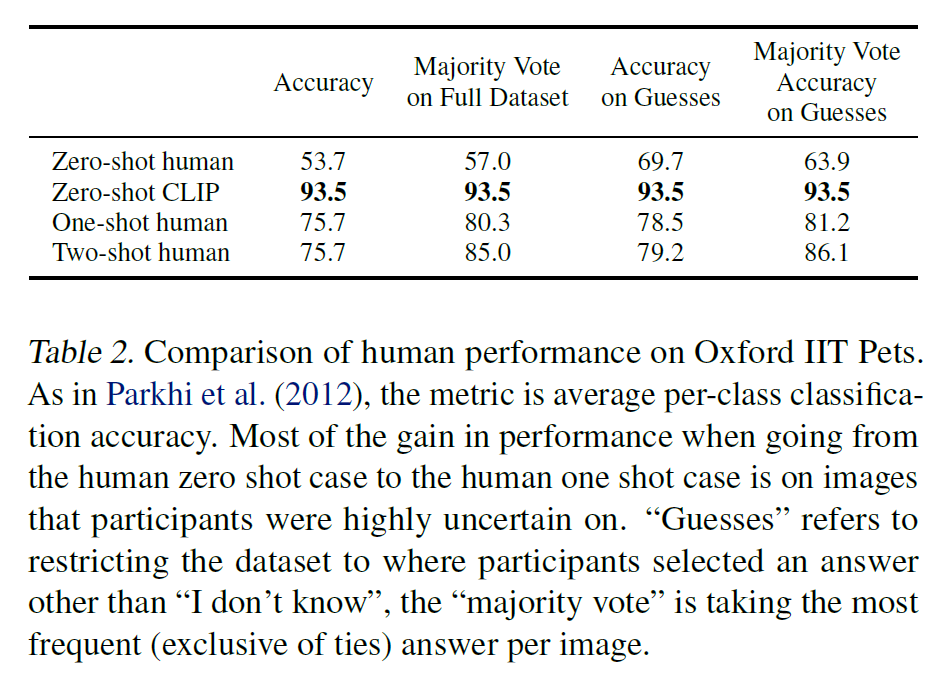
사람과 비교해 월등히 뛰어나다. 예시를 보여줘도 사람이 더 못한다(…).
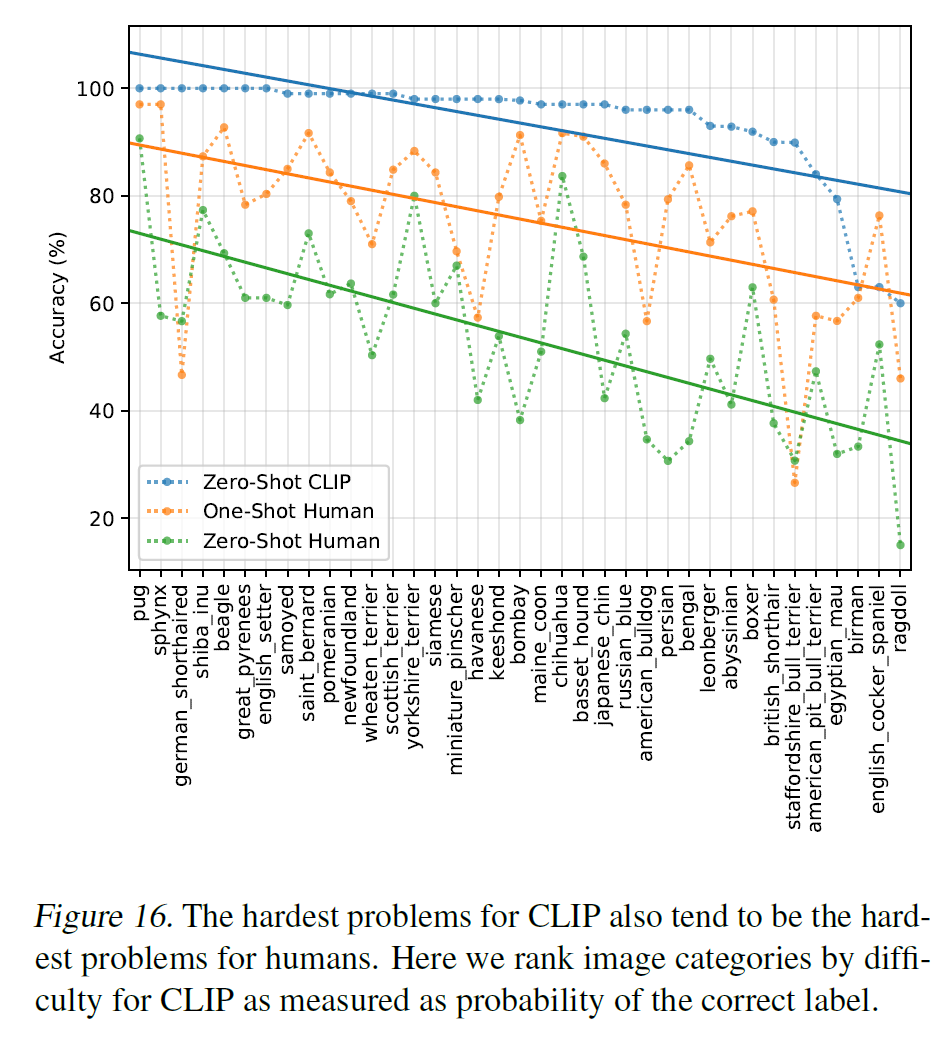
참고로 CLIP에게 어려운 문제는 사람도 어려워한다고 한다. 흠..
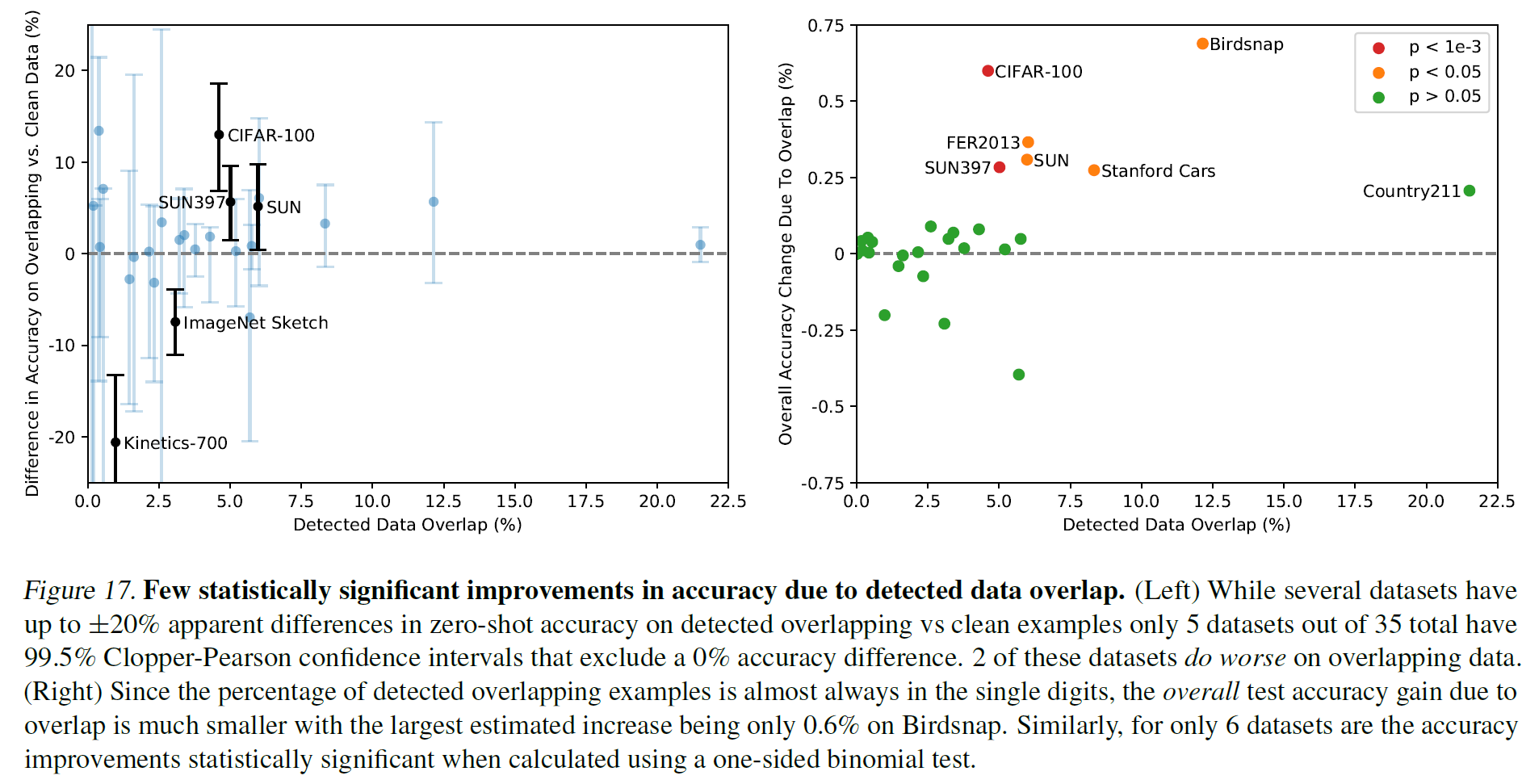
5. Data Overlap Analysis
대규모 데이터셋을 구성할 때 한 가지 걱정거리는 이후 사용할 downstream task에도 똑같이 포함되는 데이터가 있을 수 있다는 것이다(즉, 두 데이터셋에 overlap되는 데이터나 부분집합이 있을 수 있다). 원칙적으로는 겹치는 데이터가 없어야 downstream task에 대해 정확한 성능을 측정할 수 있다.
이를 방지하는 방법은 데이터셋에서 모든 중복된 데이터를 제거하는 것이다. 그러나 이는 benchmark나 이후 분석 등의 범위를 제한할 수 있다.
대신, CLIP은 데이터가 얼마나 겹치는지, 그리고 이것이 얼마나 성능에 영향을 주는지를 평가할 것이다. (별 영향이 없다면, 조금 겹쳐도 모델의 성능이 충분히 좋다, 라고 얘기할 수 있을 듯하다.)
- 각 평가 데이터셋마다 얼마나 겹치는지 duplicate detector를 만들어(부록 C) 사용한다. 그리고 가장 가까운 이웃을 찾고 데이터셋마다 recall을 최대화하면서 높은 precision을 유지하도록 threshold를 건다. 이 제한을 사용해서 2개의 두 부분집합을 만든다.
Overlap: 위 threshold 하에서 training example과 일정 이상 유사한 모델 example을 포함한다.Clean: threshold 이하의 모든 example을 포함한다.All: 아무 수정도 가하지 않은 전체 데이터셋.All 대비 Overlap 비율을 측정하여 오염도(the degree of data contamination)를 기록한다.
- 위 3개의 split에 대해 zero-shot CLIP 성능을 측정하고
All - Clean을 주요 측정 지표로 사용한다. 이 측정 결과는 데이터 오염도에 따라 차이가 있을 것이다. 만약 양의 값을 가지면 측정된 정확도 중 얼마만큼이나 오염된 데이터에 의해 부풀려졌는지 확인할 수 있을 것이다.
- overlap된 정도가 낮을 경우 binomial significance test도 수행하고(null hypothesis로
Clean에서의 정확도 사용), Overlap 부분집합에 대해 one-trailed(greater) p-value 값을 계산한다. Dirty에서 99.5% Clopper-Pearson confidence interval 또한 계산한다.
아래가 결과인데, 일부의 경우에서 data overlap으로 인해 정확도가 조금 부풀려진 것을 확인할 수 있다.
- (왼쪽) 35개 중 5개의 데이터셋에서만 99.5% (신뢰)구간을 벗어난다. 근데 2개의 데이터셋에서는 overlap이 발생했는데 성능이 더 낮다.
- (오른쪽) detector로 탐지한 overlapping example의 비율이 한 자리수라서 overlap에 의한 overall test 정확도 향상이 전체에 비해 크지 않다. (아마 이를 보정하여 새로 계산한 결과) 6개의 데이터셋만이 유의미한 차이가 있음을 볼 수 있다.
6. Limitations
CLIP에도 한계점은 여럿 있다.
- ResNet-50이나 101과 비교해서 zero-shot CLIP이 더 좋긴 한데 이 baseline은 현재 SOTA에 비하면 많이 낮은 성능을 가지는 모델이다. zero-shot CLIP이 전반적으로 SOTA 성능에 도달하려면 계산량이 1000배는 증가해야 할 것이라고 말하고 있다. 이는 현재로선 불가능하므로, 이를 줄이기 위한 추가 연구가 필요하다.
- zero-shot CLIP의 성능은 강한 부분(task)도 있지만 그렇지 못한 부분도 많다. Task-specific 모델과 비교하여 여러 유형의 세분회된 분류(즉, 좁은 범위에서의 분류 문제)에서 특히 약하다. 또한 사진에서 가장 가까운 자동차까지의 거리를 분류하는 task와 같은, CLIP이 사전학습 단계에서 학습했을 리 없는 새로운 종류의 문제에서는 정답률이 거의 찍는 수준일 수 있다.
- CLIP은 고품질의 OCR representation을 학습하지만, MNIST에서 88%의 정확도밖에 달성하지 못한다. 매우 단순한 logistic regression 모델보다 낮은 이 성능은 사전학습 데이터셋에 MNIST의 손글씨 이미지와 유사한 example이 거의 없기 때문일 것이며, 이러한 결과는 CLIP이 일반적인 딥러닝 모델의 취약한 일반화(generalization)라는 근본적인 문제를 거의 해결하지 못했음을 의미한다.
- 딥러닝의 데이터 활용률이 매우 낮은 것도 별로 개선하지 못했는데, 4억 개의 이미지를 1초에 하나씩 32 epoch을 수행하면 405년이 걸린다..
- 또 인터넷에서 그냥 수집한 데이터로 CLIP을 학습시켰는데, 이러면 CLIP은 기존에도 사람이 가지고 있는 여러 사회적 편견들도 똑같이 학습하게 된다(윤리 문제). 이는 다음 섹션에서 다룬다.
7. Broader Impacts
CLIP은 여러 작업을 수행할 수 있고 광범위한 기능을 가질 수 있다. 고양이와 개 이미지를 주고 분류를 시킬 수도, 백화점에서 찍은 이미지를 주고 좀도둑을 분류하도록 요청할 수도 있다.
CLIP은 OCR을 수행할 수 있고, 따라서 스캔한 문서를 검색가능하게 만들거나, 화면 판독, 혹은 번호판을 읽을 수 있다. 그래서 동작 인식, 물체 분류, 얼굴 감정 인식 등 광범위하게 응용할 수 있는 기술은 감시에 사용될 수 있다. 그래서 사회적 의미를 감안할 때 감시할 수 있는 이러한 영역에서 사용 영역을 다루고자 한다.
7.1. Bias
사회적 편견은 데이터셋 내에 그대로 녹아들어가 있고, 이를 통해 학습하는 모델 역시 이를 그대로 학습할 수 있다. 실제로, 이 논문에서는 FairFace benchmark dataset으로 여러 실험을 진행하였다.
명예훼손의 피해가 통계적으로 적은(소수자, 혹은 낮다고 잘못 생각하는 위치)의 인구 그룹에 불균형적으로 영향을 미치는지를 조사한 한 가지 예시를 정리해 보면(이는 논문 결과를 요약한 것이며 특정 편향을 갖고 쓴 글이 아님):
- FairFace에 있는 class에 더해 새로운 class name을 추가했다.
- ‘동물’, ‘고릴라’, ‘침팬지’, ‘오랑우탄’, ‘도둑’, ‘범죄자’ 및 ‘수상한 사람’.
- 전체 이미지의 4.9% 정도는 분명 사람의 이미지임에도 위에서 추가한 비인간 class로 잘못 분류되었다.
- ‘흑인’이 14% 정도로 가장 높은 오분류 비율을 보였으며 나머지 모든 인종은 8% 이하의 오분류율을 보였다.
- 0~20세 이하의 사람이 그 이상의 사람보다 오분류율이 더 높았다.
- 남성은 16.5%가 범죄와 관련된 class(‘도둑’, ‘수상한 사람’, ‘범죄자’)로 분류된 반면 여성은 9.8%만이 범죄자 관련 class로 분류되었다.
즉, CLIP은(그리고 아마도 다른 모델들도) 어떤 사회적 편향을 그대로 학습했다고 볼 수 있다.
이외에도 국회의원 관련 데이터셋으로 평가했을 때 남성은 prisoner, mobster(제소자 혹은 조직폭력배), 여성은 nanny 혹은 housekeeper(유모 혹은 가정부)와 연관이 깊다고 나오며, 여성이 갈색 머리, 금발과 연관이 잘 지어지는 반면 남성은 임원, 의사와 더 잘 짝지어진다…
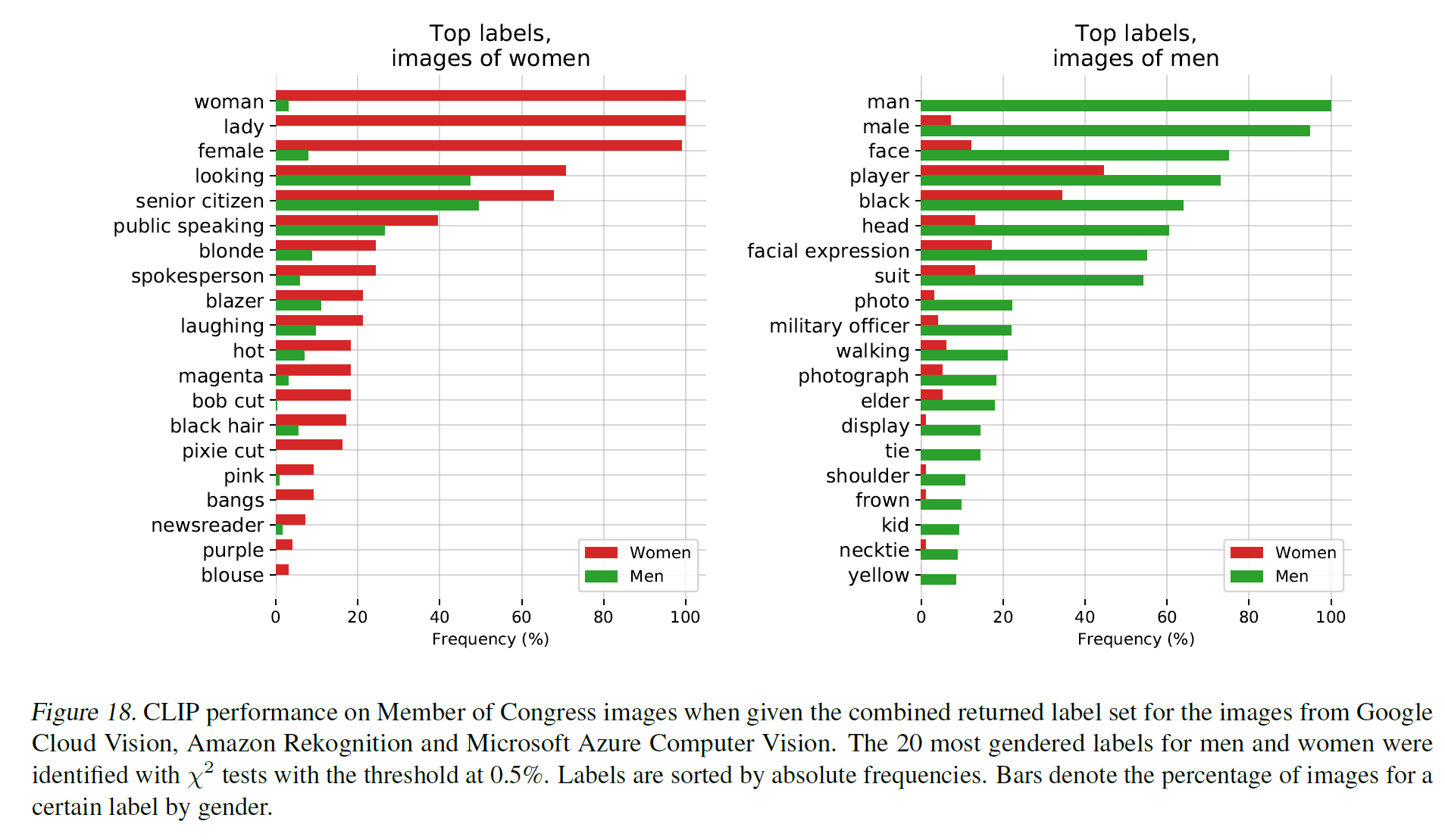
그리고, class design도 신중하게 잘 정해야 한다. class name을 어떻게 추가하느냐에 따라서도 위 결과는 달라질 수 있다.
즉, 모델을 만들 때에는 편향성을 반드시 인지하고 이를 보완하기 위한 방안이 반드시 필요하다.
7.2. Surveillance
실험 결과는 사실 CLIP은 task-specific한 학습을 하지 않았기 때문에 다른 유명한 모델보다 성능은 떨어진다. 그래서 특정 감시 작업에는 효용이 떨어지기는 하지만 CLIP과 유사한 모델은 맞춤형 감시 작업의 문턱을 낮출 수도 있다.
7.3. Future Work
다음을 통해 모델이 유용하게 사용될 가능성을 높일 수 있을 것이다:
- 연구 초기에 모델의 잠재적인 downstream task를 생각하고, 응용에 대해 생각해 본다.
- 정책 입안자의 개입이 필요할 수 있는 상당한 민감도를 가지는 작업을 표면화한다.
- 모델의 편향을 더 잘 특성화하여, 다른 연구자들의 관심 영역과 개입 영역에 대해 경고한다.
- 추후 연구를 위해 잠재적인 실패 모드와 영역을 식별한다.
논문의 저자들은 이러한 연구에 기여할 계획이며 이 분석이 후속 연구에 몇 가지 동기를 부여하는 예시를 제공하기를 바란다고 한다.
CLIP은 image, text의 multimodal embedding space를 학습한 만큼 vision+language의 많은 분야에 활용될 수 있다.
- image-text pair dataset
- Text-Image Retreival
- Weakly supervised learning
- learning joint (vision + language) model
9. Conclusion
자연어처리에서 크게 성공한 task-agnostic web-scale 사전학습 방식을 vision 분야에도 적용하였다. 그리고 모델의 성능, 사회적인 의미 등을 분석하였다.
CLIP은 사전학습 중 다양한 작업을 수행하는 방법을 학습한다. 그리고 자연어 prompt를 통해 여러 기존 데이터셋에 대해 zero-shot 학습을 수행, 좋은 결과를 얻었다.
OpenAI는 뭔가 항상 큰 모델을 만들고, 그 영향에 대해 생각을 해 보는 것 같다: 그러면서 공개하지 않은 모델이 여럿 있다. 이름값 못하네?
물론 이건 Microsoft에 종속되고 있기 때문이긴 하다.